Contents |
What is Subversion and why you need to use it.
The following is a very basic introduction to Subversion and what it does.
For a full online instruction book
on how to use Subversion, visit
http://svnbook.red-bean.com/en/1.7/index.html, which is available on the
Subversion website.
The following notes are taken from TortoiseSVN Help
What is Subversion?
"Subversion is version control: the art of managing changes to information."
Programmers have used version control for years to manage the changes to their software
when checking or debugging.
It was introduced to prevent programmers, working on the same files, from overwriting
each others software, possibly reintroducing bugs some poor programmer has spent ages removing.
It is for a similar reason that the Computer Laboratory has introduced Subversion.
Why you need to use it
"But I only work on a few files, and I like the way I do things, why should I change when it looks like more work for me and a bit more confusing? "
You're right!
Subversion is going to make your simple editing work more of a challenge,
but there are various reasons why we are introducing it:
- It is bad form not to
It is generally expected that large sites, such as the Computer Laboratory's (which is edited by numerous authors), should be properly managed.
Version control is, therefore, being introduced to avoid unnecessary overwriting of files and stem the confusion caused by dupliate or outdated files.
- The website is dynamic
At this present time of writing, the website is undergoing a general overhaul, but the long-term aim is to keep the website current and relevant.
New authors have been introduced to achieve this, which means there is a potential for different people to be editing the same pages simultaniously, even if they are working on different sections.
Subversion will ensure that files are not overwritten, but information merged.
Subversion introduces a system that remembers every change ever written to its repository, such as:
addition, deletion, and rearrangement of files and directories.
- Your time and efforts are not wasted by having your work overwritten and lost
- You don't have to wait for other people to finish their edits on a file before you can access it
- You can track the changes made to a file, who made them and when
- You can retrieve an older version of a file should the need arise, and be precise about the date of file you want to retrieve
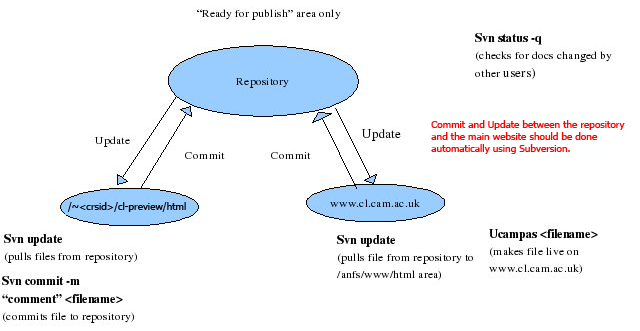
How it works
| Note: You may or may not find this section of interest, but as you get used to using Subversion, you may find it of use to understand what is happening behind the scenes. |
Files are stored in a
central repository, similar to an ordinary file server, except
that it remembers every change ever made to the files and directories.
This
allows you to recover older versions of your files and examine the history of
how and when your data changed, and who changed it.
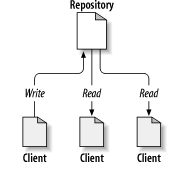
The Repository
 |
|
To manage the multiple file versions, Subversion uses a Copy-Modify-Merge model
as an alternative to locking.
In this model, each user's client reads the
repository and creates a personal working copy of the file or project.
Users
then work in parallel, modifying their private copies.
Finally, the private
copies are merged together into a new, final version.
The version control system
often assists with the merging, but ultimately a human being is responsible for
making it happen correctly.
This is much more efficient than the Lock-Modify-Unlock method which means only one person can be editing a file at a time.
An example
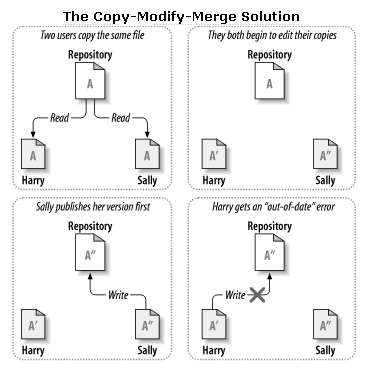 |
|
Conflicts
But what if Sally's changes do overlap with Harry's changes causing a conflict?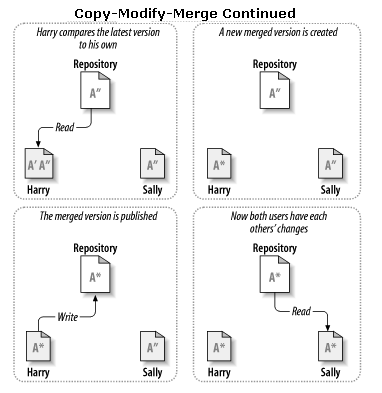 |
|
|
Note: The software can't automatically resolve conflicts. Only authors do this as they are capable of understanding and making the necessary intelligent choices. |
The copy-modify-merge model may sound a bit chaotic, but in practice, it runs extremely smoothly, as users work in parallel, never waiting for one another.
When they work on the same files, it turns out that:- most of their concurrent changes don't overlap at all
- conflicts are infrequent
- the amount of time it takes to resolve conflicts is far less than the time lost by a locking system, or rewriting a page