
Projects
Training a Task-Specific Image Restoration Loss
Winter Conference on Applications of Computer Vision (WACV) 2022
* Equal contribution
Abstract
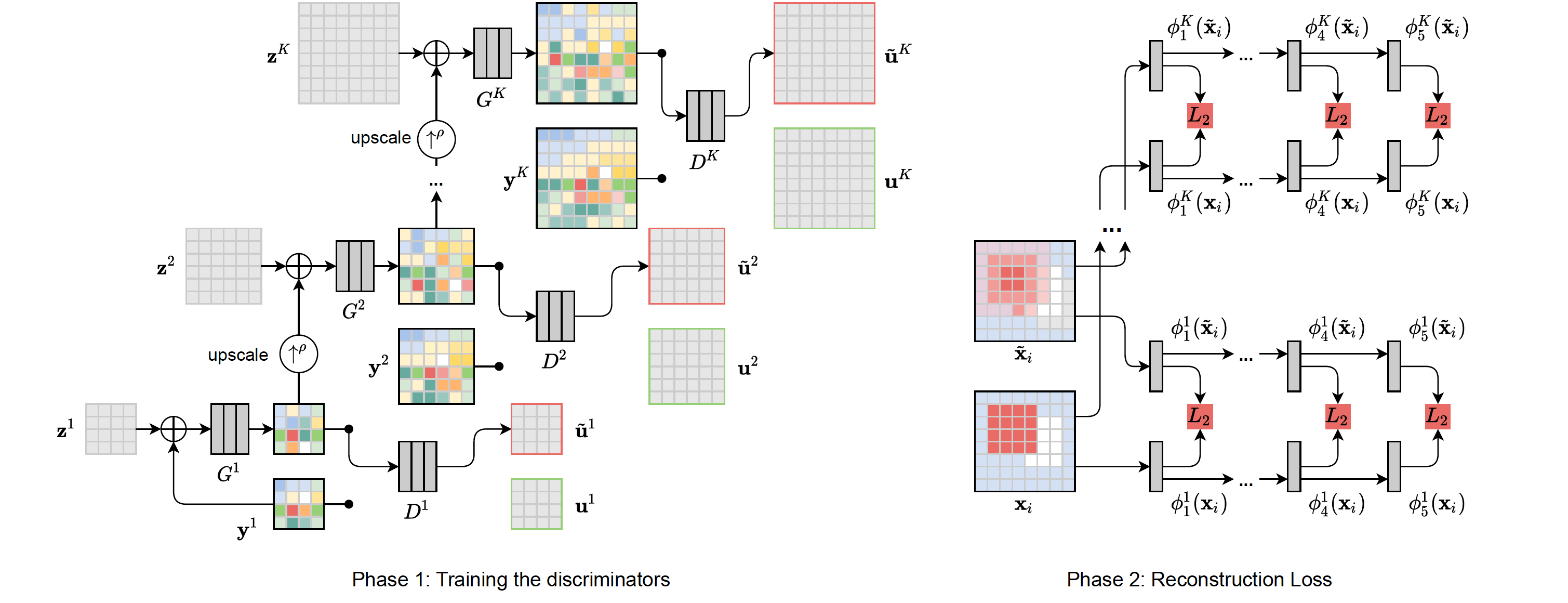
The choice of a loss function is an important factor when training neural networks for image restoration problems, such as single image super resolution. The loss function should encourage natural and perceptually pleasing results. A popular choice for a loss is a pre-trained network, such as VGG, which is used as a feature extractor for computing the difference between restored and reference images. However, such an approach has multiple drawbacks: it is computationally expensive, requires regularization and hyperparameter tuning, and involves a large network trained on an unrelated task. Furthermore, it has been observed that there is no single loss function that works best across all applications and across different datasets. In this work, we instead propose to train a set of loss functions that are application specific in nature. Our loss function comprises a series of discriminators that are trained to detect and penalize the presence of application-specific artifacts. We show that a single natural image and corresponding distortions are sufficient to train our feature extractor that outperforms state-of-the-art loss functions in applications like single image super resolution, denoising, and JPEG artifact removal. Finally, we conclude that an effective loss function does not have to be a good predictor of perceived image quality, but instead needs to be specialized in identifying the distortions for a given restoration method.
Downloads
Applications
We provide a comprehensive comparison of qualitative results for different loss functions across different applications. To begin with, we show results for two Single Image Super-Resolution (SISR) networks, namely, Enhanced Deep Super-Resolution (EDSR) and Super-Resolution ResNet (SR-ResNet). Further, we show the results for the applications of image denoising and JPEG artefact removal.
Single Image Super-Resolution (SISR)
Image denoising
JPEG artefact removal
We compare the performance of different losses for two codec compression qualities.
Hyper-parameter tuning for VGG and LPIPS
To find the best weightage, we conduct a hyper-parameter search over controlling the weightage sum of of VGG/LPIPS and MSE feature-wise loss fucntions: MSE + weight * VGG/LPIPS.
Contact
Please contact Aamir Mustafa or Rafał K. Mantiuk with any questions regarding the method.
Acknowledgements
This project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement N◦ 725253–EyeCode).
![]()