
Projects
Dimensional Affect Recognition using Continuous Conditional Random Fields
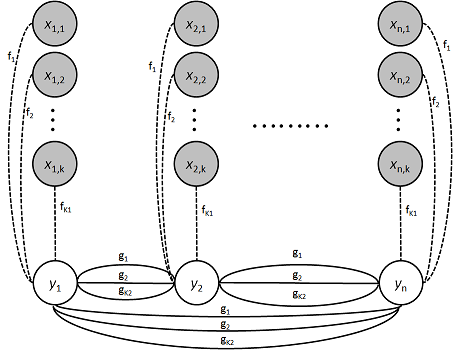
Abstract
During everyday interaction people display various non-verbal signals that convey emotions. These signals are multi-modal and range from facial expressions, shifts in posture, head pose, and non-verbal speech. They are subtle, continuous and complex. Our work concentrates on the problem of automatic recognition of emotions from such multimodal signals. We propose the use of Continuous Conditional Random Fields (CCRF) in combination with Support Vector Machines for Regression (SVR) for modeling continuous emotion in dimensional space. Our Correlation Aware Continuous Conditional Random Field (CA-CCRF) exploits the non-orthogonality of emotion dimensions. By using visual features based on geometric shape and appearance, and a carefully selected subset of audio features we show that our CCRF and CA-CCRF approaches outperform previously published baselines for all four affective dimensions of valence, arousal, power and expectancy.
Downloads
- Paper (PDF)
- Appendix (PDF)
- Matlab source (ZIP)
Code
The code available for download uses the approaches described in the paper, and can be used to produce the results presented there.
Citing our work
If you use any of the resources provided on this page in any of your publications we ask you to cite the following work.
Dimensional Affect Recognition using Continuous Conditional Random Fields
Tadas Baltrušaitis, Ntombikayise Banda, and Peter Robinson
in IEEE Conference on Automatic Face and Gesture Recognition 2013, Shanghai, China, April 2013
Bibtex
@inproceedings{Baltrusaitis2013,
author = {Tadas Baltru\v{s}aitis and Ntombikayise Banda and Peter Robinson},
title = {Dimensional Affect Recognition using Continuous Conditional Random Fields},
booktitle = {IEEE Conference on Automatic Face and Gesture Recognition},
year = 2013,
}