
Projects
3D Constrained Local Model for Rigid and Non-Rigid Facial Tracking
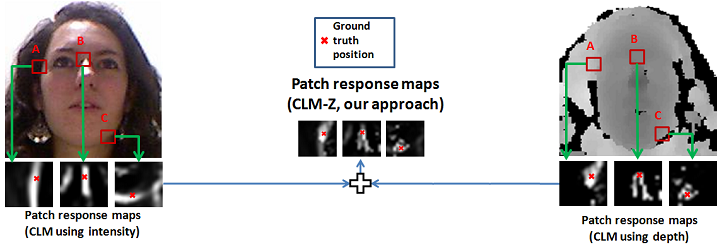
Abstract
We present 3D Constrained Local Model (CLM-Z) for robust facial feature tracking under varying pose. Our approach integrates both depth and intensity information in a common framework. We show the benefit of our CLMZ method in both accuracy and convergence rates over regular CLM formulation through experiments on publicly available datasets. Additionally, we demonstrate a way to combine a rigid head pose tracker with CLM-Z that benefits rigid head tracking. We show better performance than the current state-of-the-art approaches in head pose tracking with our extension of the generalised adaptive view-based appearance model (GAVAM).
Downloads
- Paper (PDF, 2.56 MB)
- Source (C++ Visual Studio Project, with Matlab scripts to run experiments), please email the author for access
Code
The code available for download uses the approaches described in the paper. However, it contains several slight tweaks added for robustness and performance. Therefore, the results of running the code on the datasets used in the paper are slightly those reported in the paper (better in most cases). This is mainly due to the use of an extended training model to that described in the paper. Additionally, failure criteria were added allowing the CLM and CLM-Z tracking to reinitialise when tracking is lost.
The code also contains experiment running scripts, with the results to expect from running the code on the publicly available datasets used in the paper and described below.
The exact code that was run in the paper can also be made available upon request. However that code is not cleaned up and would be slightly more difficult to follow.
Datasets Used
ICT-3DHP
ICT-3DHP is a video dataset of ground truth labeled head poses. In addition to colour videos it has a per frame depth map captured using Microsoft Kinect.
To run our code on this dataset, simply change the expected database location in the provided Matlab scripts and run them.
Boston University
For a purely intensity based benchmark we use the Boston University head pose dataset which can be dowloaded here. We use the uniform light subset.
To run our tracker on the dataset one can just use the Matlab script code provided with the code. The expected results are made available with the code. They will be slightly different from those reported in the paper, due to several fixes and additional robustness tweaks.
Biwi
As an additional benchmark we used the Biwi Kinect Head Pose Database. This is a similar dataset to that of ICT-3DHP. However, it is more difficult for temporal trackers due to many missing frames, and very large pose variations. The dataset contains over 15K images of 20 people. For each frame, a depth image, the corresponding rgb image (both 640x480 pixels), and the annotation is provided. To run our code on this dataset it first needs to be converted to videos and the depth images have to be aligned using the provided calibration data.
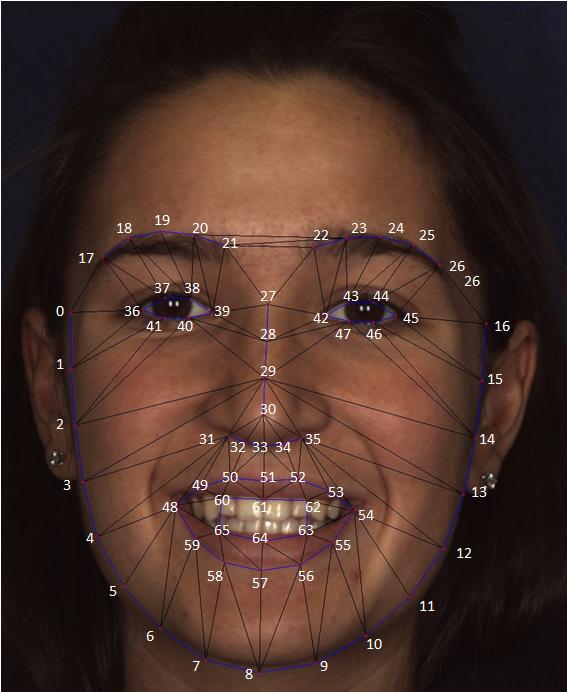
We also took and hand labeled a subset of the Biwi dataset for facial feature points, in order to evaluate our facial tracking, The labels can be found here. Indices can be found here.
{kind=link}
BU-4DFE
As a static dataset we used BU-4DFE. This is a high-resolution 3D dynamic facial expression database. The 3D facial expressions are captured at a video rate (25 frames per second). The database contains 606 3D facial expression sequences captured from 101 subjects.
We converted this dataset into separate images and generated depth images for them. This allowed us to train our CLM-Z patch experts using both the texture and depth images. We hand labeled a subset of images on from this dataset. The labels are split into two parts, as some depth images are noisy not all of them could have been used for training, the labels for clean images can be found here, while the labels for all images are here. Indices can be found here.
Citing our work
If you use any of the resources provided on this page in any of your publications we ask you to cite the following work.
3D Constrained Local Model for Rigid and Non-Rigid Facial Tracking
Tadas Baltrušaitis, Peter Robinson, and Louis-Philippe Morency
in IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, June 2012
Bibtex
@inproceedings{Baltrusaitis2012,
author = {Tadas Baltru\v{s}aitis and Peter Robinson and Louis-Philippe Morency},
title = {3D Constrained Local Model for Rigid and Non-Rigid Facial Tracking},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition},
year = 2012,
}