
Course pages 2017–18
Optimising Compilers
Principal lecturer: Dr Timothy Jones
These slides due to (and copyright holder): Tom Stuart
Taken by: Part II
The slides for each lecture are available as individual downloads below;
alternatively, download them all as one giant
document (3.5M PDF, 644 pages), which is also available in a
tree-preserving 8-up format for printing
(3.5M PDF, 81 pages).
Note that Lecture13a must be downloaded separately as
1-up or as 8-up
There is an errata at the end of this page
- Lecture 1: Introduction (352k PDF, 37 pages)
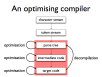






- Structure of an optimising compiler
- Why optimise?
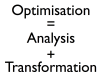
- Optimisation = Analysis + Transformation
- 3-address code
- Flowgraphs
- Basic blocks
- Types of analysis
- Locating basic blocks
- Lecture 2: Unreachable-code & -procedure elimination (263k PDF, 53 pages)
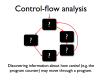


- Control-flow analysis operates on the control structure of a program (flowgraphs and call graphs)
- Unreachable-code elimination is an intra-procedural optimisation which reduces code size
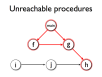
- Unreachable-procedure elimination is a similar, interprocedural optimisation making use of the program's call graph
- Analyses for both optimisations must be imprecise in order to guarantee safety
- Lecture 3: Live variable analysis (497k PDF, 45 pages)





- Data-flow analysis collects information about how data moves through a program
- Variable liveness is a data-flow property
- Live variable analysis (LVA) is a backwards data-flow analysis for determining variable liveness
- LVA may be expressed as a pair of complementary data-flow equations, which can be combined
- A simple iterative algorithm can be used to find the smallest solution to the LVA data-flow equations
- Lecture 4: Available expression analysis (453k PDF, 58 pages)




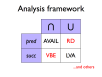
- Expression availability is a data-flow property
- Available expression analysis (AVAIL) is a forwards data-flow analysis for determining expression availability
- AVAIL may be expressed as a pair of complementary data-flow equations, which may be combined
- A simple iterative algorithm can be used to find the largest solution to the AVAIL data-flow equations
- AVAIL and LVA are both instances (among others) of the same data-flow analysis framework
- Lecture 5: Data-flow anomalies and clash graphs (162k PDF, 40 pages)




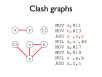
- Data-flow analysis is helpful in locating (and sometimes correcting) data-flow anomalies
- LVA allows us to identify dead code and possible uses of uninitialised variables
- Write-write anomalies can be identified with a similar analysis
- Imprecision may lead to overzealous warnings
- LVA allows us to construct a clash graph
- Lecture 6: Register allocation (477k PDF, 45 pages)
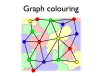
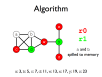
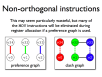

- A register allocation phase is required to assign each virtual register to a physical one during compilation
- Registers may be allocated by colouring the vertices of a clash graph
- When the number of physical registers is limited, some virtual registers may be spilled to memory
- Non-orthogonal instructions may be handled with additional MOVs and new edges on the clash graph
- Procedure calling standards are also handled this way
- Lecture 7: Redundancy elimination (352k PDF, 37 pages)

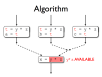

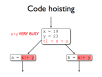
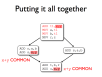
- Some optimisations exist to reduce or remove redundancy in programs
- One such optimisation, common-subexpression elimination, is enabled by AVAIL
- Copy propagation makes CSE practical
- Other code motion optimisations can also help to reduce redundancy
- The optimisations work together to improve code
- Lecture 8: Static single-assignment; strength reduction (189k PDF, 35 pages)


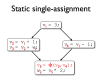




- Live range splitting reduces register pressure
- In SSA form, each variable is assigned to only once
- SSA uses Φ-functions to handle control-flow merges
- SSA aids register allocation and many optimisations
- Optimal ordering of compiler phases is difficult
- Algebraic identities enable code improvements
- Strength reduction uses them to improve loops
- Lecture 9: Abstract interpretation (101k PDF, 27 pages)



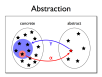

- Abstractions are manageably simple models of unmanageably complex reality
- Abstract interpretation is a general technique for executing simplified versions of computations
- For example, the sign of an arithmetic result can be sometimes determined without doing any arithmetic
- Abstractions are approximate, but must be safe
- Data-flow analysis is a form of abstract interpretation
- Lecture 10: Strictness analysis (215k PDF, 44 pages)





- Functional languages can use CBV or CBN evaluation
- CBV is more efficient but can only be used in place of CBN if termination behaviour is unaffected
- Strictness shows dependencies of termination
- Abstract interpretation may be used to perform strictness analysis of user-defined functions
- The resulting strictness functions tell us when it is safe to use CBV in place of CBN
- Lecture 11: Constraint-based analysis (168k PDF, 42 pages)





- Many analyses can be formulated using constraints
- 0CFA is a constraint-based analysis
- Inequality constraints are generated from the syntax of a program
- A minimal solution to the constraints provides a safe approximation to dynamic control-flow behaviour
- Polyvariant (as in 1CFA) and polymorphic approaches may improve precision
- Lecture 12: Inference-based analysis (173k PDF, 21 pages)





- Inference-based analysis is another useful framework
- Inference rules are used to produce judgements about programs and their properties
- Type systems are the best-known example
- Richer properties give more detailed information
- An inference system used for analysis has an associated safety condition
- Lecture 13: Effect systems (277k PDF, 37 pages)






- Effect systems are a form of inference-based analysis
- Side-effects occur when expressions are evaluated
- Function types must be annotated to account for latent effects
- A type system may be modified to produce judgements about both types and effects
- Subtyping may be required to handle annotated types
- Different effect structures may give more information
- Lecture 13a: Points-to and alias analysis
- Anderson's points-to analysis
- Worked through example of Andersen's analysis as individual slides or 8-up
- Lecture 14: Instruction scheduling (364k PDF, 45 pages)
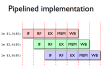


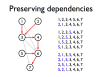
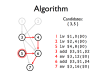
- Instruction pipelines allow a processor to work on executing several instructions at once
- Pipeline hazards cause stalls and impede optimal throughput, even when feed-forwarding is used
- Instructions may be reordered to avoid stalls
- Dependencies between instructions limit reordering
- Static scheduling heuristics may be used to achieve near-optimal scheduling with an O(n²) algorithm
- Lecture 15: Register allocation vs. instruction scheduling; legality of reverse engineering (216k PDF, 29 pages)




- Register allocation makes scheduling harder by creating extra dependencies between instructions
- Less aggressive register allocation may be desirable
- Some processors allocate and schedule dynamically
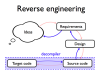
- Reverse engineering is used to extract source code and specifications from executable code
- Existing copyright legislation may permit limited reverse engineering for interoperability purposes
- Lecture 16: Decompilation (270k PDF, 35 pages)

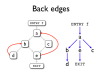


- Decompilation is another application of program analysis and transformation
- Compilation discards lots of information about programs, some of which can be recovered
- Loops can be identified by using dominator trees
- Other control structure can also be recovered
- Types can be partially reconstructed with constraint-based analysis
Errata
On slide 6 in lecture 11 (constraint-based analysis), the specimen language is missing a lambda application term.