
Kiwi is open source: the live repo is hosted on bitbucket.org/djg11/bitbucket-hprls2. There are stable snapshots linked on adjacent web pages.
Demo at FPL 2017, September, Ghent.
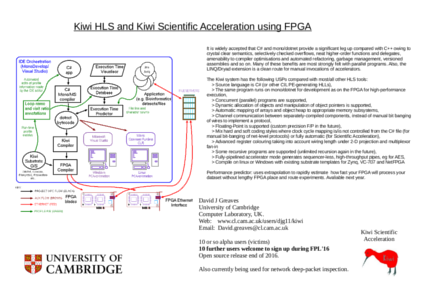
The Kiwi project aims to make reconfigurable computing technology like Field Programmable Gate Arrays (FPGAs) more accessible to mainstream programmers. FPGAs have a huge potential for quickly performing many interesting computations in parallel but their exploitation by computer programmers is limited by the need to think like a hardware engineer and the need to use hardware description languages rather than conventional programming languages.
The Von Neumann computer has hit a wall in terms of increasing clock frequency. It is widely accepted that Parallel Computing is the most energy-efficient way forward. The FPGA is intrinsically massively-parallel and can exploit the abundant transistor count of contemporary VLSI. Andre DeHon points out that the Von Neumann architecture no longer addresses the relevant problem: he writes "Stored-program processors are about compactness, fitting the computation into the minimum area possible".
"Stored-program processors are about compactness,
fitting the computation into the minimum area possible." -- Andre DeHon
 |
The FPGA alternative: Pico Computing FPGA-based server blade: Four FPGAs, a PCI-e bus switch and a 3-D DRAM Cube, but no CPU! |
Why is computing on an FPGA becoming a good idea ?
Spatio-Parallel processing uses less energy than equivalent temporal processing (ie at higher clock rates) for various reasons. David Greaves gives nine:
It is widely accepted that many problems in scientific computing can be vastly accelerated using either FPGA or GPU execution resources. Also, the FPGA approach in particular leads generally to a significant saving in execution energy. The product of the two gains can be typically one thousand fold.
Kiwi provides acceleration for multi-threaded (parallel) programs provided they can be converted to .NET bytecode. Originating from Microsoft, the .NET (also known as CIL) is a well-engineered, general purpose intermediate code that runs on many platforms, including mono/linux.
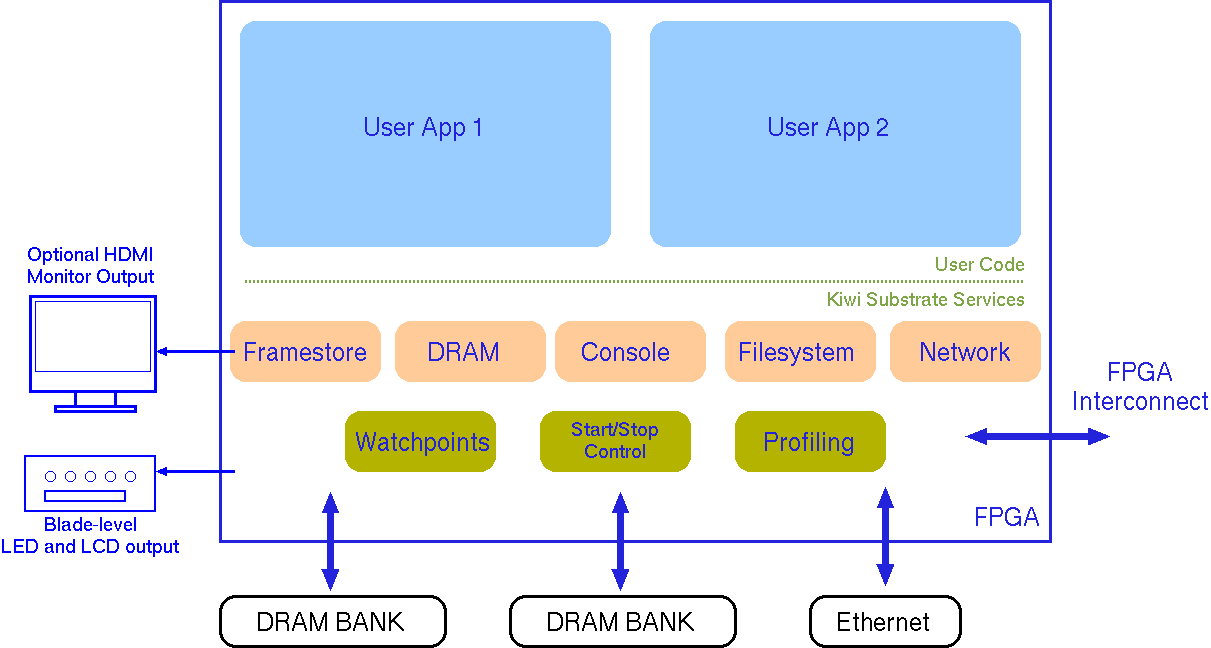
We use the term substrate to refer to an FPGA board or boards that is loaded with various standard parts of the Kiwi system. The most important substrate facilities are access to DRAM memory, a disk filesystem and a console/debug channel. Basic run/stop/error status output to LEDs via GPIO is also provided.
The substrate is like an operating system on the FPGA. It supports connection to more than one application.
The basic .NET classes for streamreader, streamwriter, textreader and textwriter are provided. Random access using ftell and fseek is also supported.
Very high bandwidth writes to the framestore are an intrinsic feature of FPGA computing. The framestore can be used for high-performance visualisation or just for a progress indicator- e.g. percentage of the job processed.
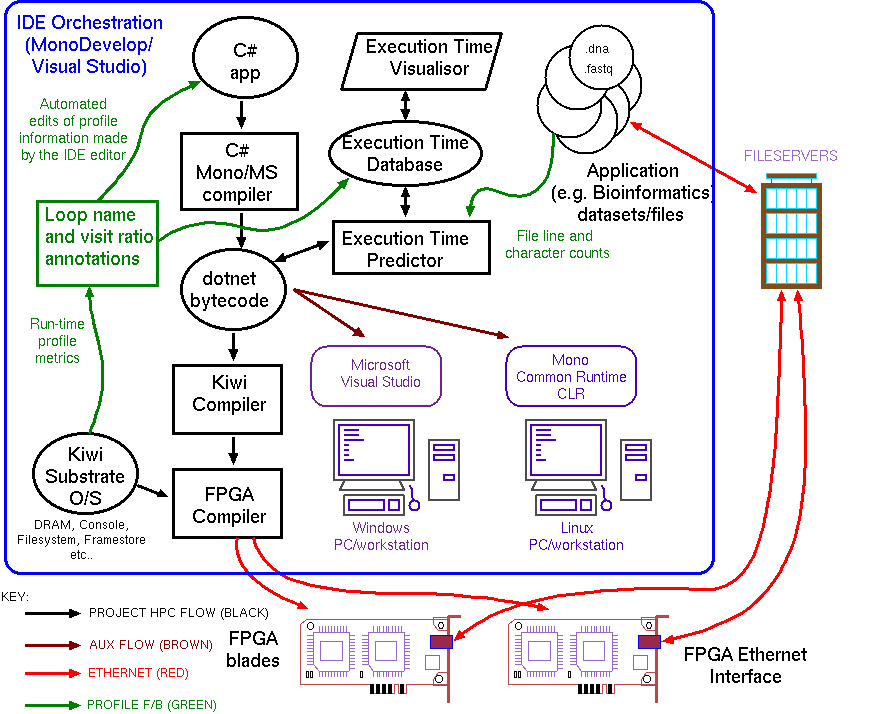
Find out what speedup you will achieve before investing an afternoon in the projection to FPGA bitstream.
When using FPGA acceleration, as with all high-performance computing, careful design of datastructures is a most important consideration. This requires a good idea of what is stored where and how frequently it must move. Moreover, the key to compiling software to high-performance circuits is to balance the ow of data on the various paths. Given that such information is available inside tools such as Kiwi, the novel aspect in this project is to augment and forward this information up to the user so that they can make informed decisions and rapid experiments at the data structure and algorithm level.
The profile counters in the substrate, when enables, count the number of visits to a carefully-chosen set of basic blocks. This information is compared with the original prediction and a recalibration file is generated that can either be permanently inserted in the program's source code or else kept in the IDE alongside the program.
A design exploration demo using the Performance Predictor is being put together on this link: Kiwi Performance Predictor Demo.
There have been numerous high-level synthesis (HLS) projects in recent decades. Finally HLS has come of age, with all FPGA and EDA vendors offering HLS products. Nearly all of the prior work has used C, C++ or SystemC as the source HLL. (Historical note: Greaves CTOV compiler from 1995 is now owned by Synopsys Greaves-CTOV-1995 via the Tenison EDA sale.)
It is widely accepted that C# and mono/dotnet provide a significant leg up compared with C++ owing to crystal clear semantics, selectively checked overflows, neat higher-order functions and delegates, amenability to compiler optimisations and automated refactoring, garbage management, versioned assemblies and so on. Many of these benefits are most strongly felt with parallel programs. Also, the LINQ/Dryad extension is a clean route for manual invocations of accelerators.
The Kiwi system has the following USPs compared with most/all other HLS tools:
The performance predictor will be a vital component for scientific users, but can perhaps be adapted for embedded hard-real-time control where Kiwi is being used for protocol implementation and deep packet inspection in the Network As A Service project.
A number of demos and projects have been done using Kiwi in the last five years. Here we are collecting together a number of them and making sure they still compile. All the following will become links in the near future...
We have a new technique for compiling heavy control flow that differs from conventional HLS. It is called VSFG. "Exposing ILP in custom hardware with a dataflow compiler IR". This is being prototyped within the Kiwi framework (and in other projects).
Although Kiwi is a tool that mainly/essentially works, a lot of further development is envisioned. Apart from bug fixing, the main development/research areas for Kiwi at the moment are:
The Kiwi compiler, KiwiC, itself consists of about 22 klocs (thousand lines of code) of F# (FSharp) code that is a front end to the HPR L/S logic synthesis library that is composed of another 60 or so klocs of F#. The code density for F#, like other dialects of ML, is perhaps (conservatively perhaps) 3 times higher than for common imperative languages like C++, Java and C#, so it is a significant project.
Kiwi is open source: download a snapshot from HERE.
First Draft User Manual 80 pages (PDF)
Hastlayer's dotnet to FPGA project.
Performance predictor demo: Kiwi Performance Predictor Demo.
Acceleration of graph algorithms using multi-blade Co-Synthesis Kiwi-Axelgraph.