
Malcolm Scott
Supervision exercises: Computer Networking (2014)
You are expected to produce solutions to all the questions for each supervision. I don't expect long essay-style answers or intricate diagrams (use the number of marks as a clue to how much you should write); spend longer thinking about the questions than writing your answers. A few parts of these exercises involve practical work; don't make the mistake of thinking that these will not require much time.
Email your solutions to me at least 24 hours before the supervision starts. If you prefer to hand-write your answers, I'd much prefer it if you could scan them in. I prefer PDF, formatted with wide margins and plenty of white space, so that I can annotate it.
When emailing me regarding supervisions (or any other lab business) please only use my lab address, or your email will be misfiled and may slip by unnoticed:
Some of these questions were inspired by, adapted from or blatantly stolen from numerous sources in the lab and elsewhere, to whom I am grateful.
Supervision 1
1.0. Terminology and Dubious Analogy
- Consider a communication network consisting of a room full of people, where one or more people are exchanging thoughts with one or more others by talking.
- For each of the abstract terms
- node
- channel
- entity
- layer
- transmission (the act thereof)
- coding
- addressing
- multiplexing
- Briefly compare and contrast this network with a shared-media wireless Ethernet and with a single Ethernet link, for the following channel criteria:
- physical medium [1 mark]
- total capacity [1 mark]
- maximum user-to-user capacity [1 mark]
- medium access control [2 marks]
- geograhical area [1 mark]
- failure modes [2 marks]
- For each of the abstract terms
- Multiplexing basics:
- Give an example of multiplexing in a real (non-computer-related) system. Explain your example's concurrency-control policy on access to the lower-layer channel, and how this is agreed. [2 marks]
- What kind of traffic is suited to synchronous time-division multiplexing? Define the term circuit. Give an example of a circuit which is not implemented using time-division multiplexing. [3 marks]
- Give three ways in which asynchronous time-division multiplexing is more complex than synchronous time-division multiplexing. Why is asynchronous TDM used on the Internet? [7 marks]
1.1. Layering
Note added Fri 24 Jan: you might not have reached the lecture which covers this yet. The OSI model is concerned with layers of abstraction in network protocols, and how a packet is formed from various types of metadata and data; please read ahead in the slides for Topic 2 if necessary.
- What is the purpose of the OSI model? [2 marks]
- For the lower four layers of the OSI model, give for each:
- a brief description of the layer;
- an example used on the Internet;
- where it's implemented in the Internet in interconnection equipment and/or end systems.
- Where would each of the following systems fit into the OSI model?
- a HTTP proxy server;
- a VPN (i.e. encapsulating encrypted IP packets inside another protocol such as UDP or TCP);
- Internet standard protocol RFC 1149.
1.3. Wireshark basics—practical
Wireshark is a tool to capture network frames/packets sent from and received by your computer. We will use it in future supervisions, but I would like you to familiarise yourself with it now.
Wireshark needs administrative privileges to capture packets, so will not work on the PWF. You can install it on your own machine, though (it works on Linux, Windows or OS X). Once installed on Linux, you may need to run sudo wireshark to capture packets (but be aware of the risks of running complex applications as root); see the Wireshark wiki on Capture Privileges for other options. The Capture Setup wiki page may also be useful.
If you cannot get it to work, or do not have a suitable computer, let me know and I'll arrange something.
Perform the following tasks and answer the questions in bold:
- What is the difference between a frame and a packet? (NB: I (and perhaps the lecturer) will sometimes say "packet" when I strictly should have said "frame". I apologise in advance for sloppy terminology caused by my interest in particular parts of the network stack; feel free to correct me.) [1 mark]
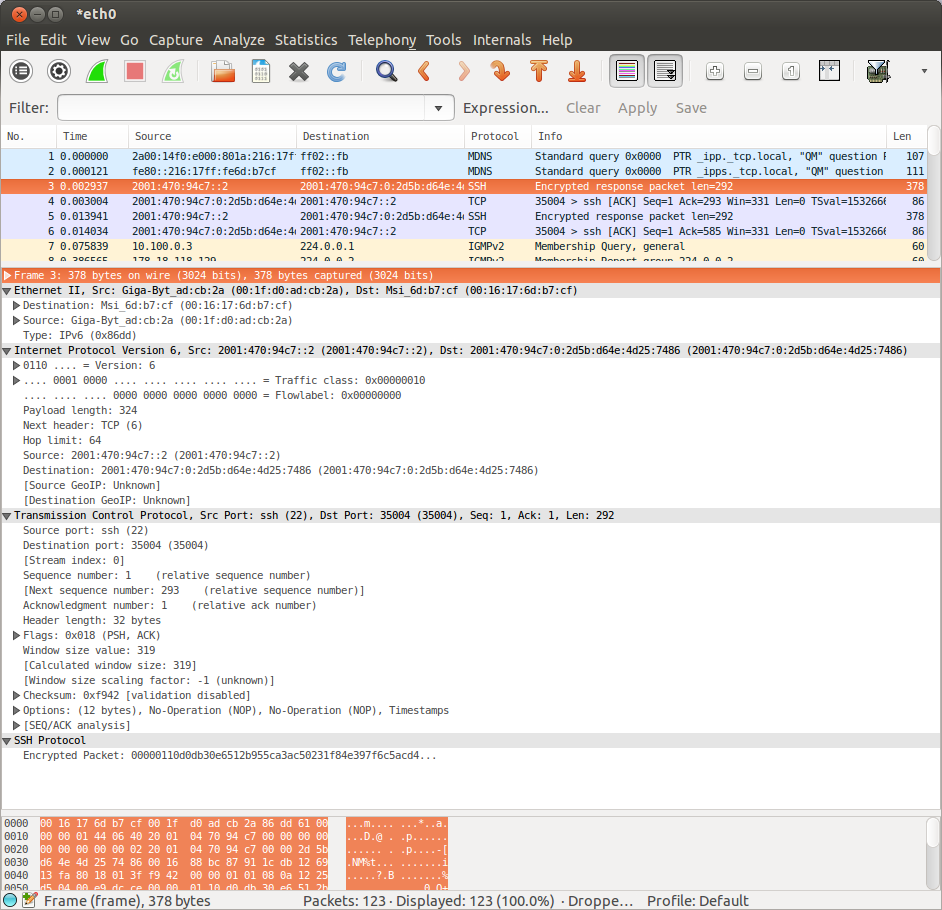 Use Wireshark to capture a few packets whilst you use the Internet (e.g. load a web page, or send an email). You will probably have to read the documentation and/or experiment a bit to figure out how to do this. It should look something like the one shown here.
Use Wireshark to capture a few packets whilst you use the Internet (e.g. load a web page, or send an email). You will probably have to read the documentation and/or experiment a bit to figure out how to do this. It should look something like the one shown here.The top part of the window is a list of frames/packets. The middle shows a dissection of the contents of the selected frame. At the bottom is the raw binary data of the selected frame exactly as received.
- Select a few frames and examine the dissections. Explain why (almost) every frame contains several protocols. Which protocols are always present in every packet, and which change depending on the packet you have selected? How do the protocols fit together to form a single frame? [4 marks]
- Take a screenshot, similar to the one shown, of one of the packets involved in your use of the Internet (e.g. the HTTP request). You may wish to apply a filter to view only the particular packets you are looking for (there will almost certainly be a lot of additional signalling traffic caused by services on the router, your system and nearby systems): for example, the filters http or tcp.port == 80 show only HTTP packets.
- Annotate your screenshot to show relevant information (e.g. how can you tell that this is the packet you were looking for?).
- Is the content of your Internet use visible in the packet (i.e. can you see the web address you visited, the email address you contacted, etc.?) Why / why not? (The answer will depend on the protocol you picked.) [2 marks]
Supervision 2
2.0. Physical and Data Link layers in the slides
Topic 3 (in slide set 2) is entitled "The Data Link Layer". However, several of the slides are entirely concerned with other layers, or apply generally to any layer, so the title of the topic is rather misleading.
For each of the ideas in slides 8 to 41 inclusive ("Coding – a channel function" to "Error Detection vs Correction"), identify which layer(s) it is concerned with. [6 marks]
2.1. Line coding
- What problems are Manchester coding designed to solve? [2 marks]
- Name a line coding scheme used in an Ethernet physical layer and explain why it is used instead of Manchester coding. [2 marks]
- Is physical line coding a challenge or an aid for an organisation such as the NSA which seeks to passively intercept high-throughput communication lines? [2 marks]
2.2. More wireless multiple access: CDMA
Note: don't confuse CDMA and CSMA.
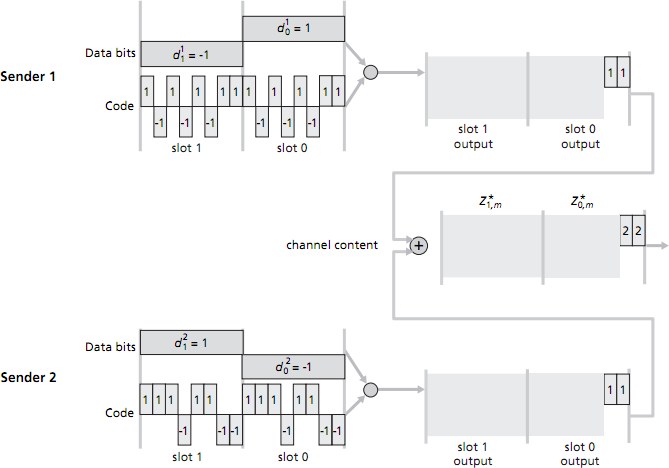
Consider a CDMA scenario with two senders and two receivers. The chipping rate is 8 mini-slots for each data bit. The 8-bit CDMA code for sender 1 is 1, -1, 1, -1, 1, -1, 1, 1. The 8-bit CDMA code for sender 2 is 1, 1, 1, -1, 1, 1, -1, -1. (See figure below.)
- Sender 1 has two data bits to send: a 1 followed by a -1; sender 2 also has two data bits to send: a -1 followed by a 1. The figure below shows the first two mini-slot bits sent by each sender, and the first two mini-slot combined bits values in the channel. Compute the remaining sequence of mini-slot bits sent into the channel by sender 1 and by sender 2, and the remaining combined bit values on the channel—i.e. fill in the grey-shaded regions in the figure to the right. [3 marks]
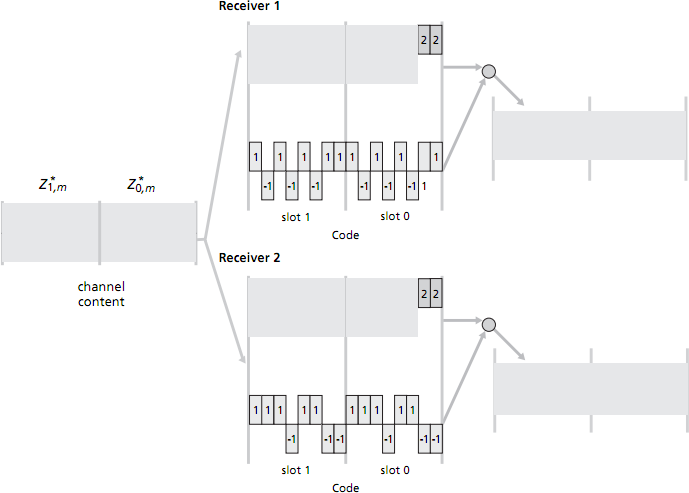
- Assume now that there are two receivers. Receiver 1 wants to obtain the two data bits sent from sender 1 and knows sender 1's CDMA code; similarly, receiver 2 wants to receive the two data bits sent from sender 2 and knows sender 2's CDMA code. Both receivers receive the 16 mini-slotted bits in the combined channel (which you calculcated earlier). Show how each receiver performs the CDMA decoding operation in order to fill in the right-hand grey-shaded regions. [3 marks]
(Computer Networking, 3rd ed, review questions 6.2 & 6.3)
2.3. Internet design philosophy
- The Internet's standards body, the IETF (Internet Engineering Task Force), has a philosophy which was summarised by David Clark, one of the Internet's pioneers, as follows:
"We reject kings, presidents and voting. We believe in rough consensus and running code.
This suggests an approach which is open, dynamic and lead by implementation. By contrast, other standards bodies such as the ITU are closed, slow-moving and led by specification. Using examples, discuss ways in which the IETF's approach has enabled innovation in the Internet, and ways in which it has caused problems. [6 marks] - Prior to the Internet, wide-area networks were joined together at the level of application protocols, using application-layer gateways (the precursors to HTTP proxy servers). Explain ahy this approach limited application development. [1 mark]
- TCP is a connection-oriented reliable byte-stream protocol designed to run over IP, an unreliable connectionless datagram protocol.
- Where is the state of a TCP connection held? [1 mark]
- Why did TCP's designers choose to store the state there? [1 mark]
- How does this constrain the set of guarantees offered by a TCP connection? [2 marks]
2.4. Modern applications vs. the hourglass model
The Internet was designed according to an "hourglass model" in which IP acts as a lowest-common-denominator network layer protocol, underneath a variety of transport layer protocols and countless application layers. However, modern Internet applications have moved the neck of the hourglass upwards, often using HTTP (or HTTPS) as a lowest-common-denominator protocol, despite HTTP being originally intended only for the transfer of web pages. For example, YouTube serves recorded video over HTTP, Twitch.tv streams realtime live video over HTTP, Facebook uses HTTP for text chat, RapidShare uses HTTP for file transfer, Gmail provides a HTTP(S) interface to email and Skype will in some circumstances tunnel its realtime audio/video calls over HTTPS.
- What failure modes might you observe which arise as a result of the application's use of HTTP? [2 marks]
- Suggest an application-layer protocol for each of the example applications above which might have been more appropriate than HTTP. For each of those alternative application-layer protocols, give the corresponding transport-layer protocol. [6 marks]
- Why did the designers of these and other applications choose to use HTTP for a purpose other than that for which it was designed? [4 marks]
- What problems might the ubiquity of HTTP cause for future users, developers and/or network engineers? [6 marks]
2.5. Cross-layer effects
Suppose you enter a café with your laptop to find many independent open wi-fi networks run by nearby establishments to which your laptop can connect. Each network has two wireless access points connected to the same router; none of the networks require authentication. Your laptop initially associates with the access point with the strongest signal—but the signal strengths of the access points vary over time, so your association will also change over time (every few minutes). We are interested in the effects of a changing link-level association, and the consequent change of IP address when an association changes.
- Suppose you are browsing the web using HTTP/1.0, and only occasionally downloading web pages. Is the changing link-layer association likely to be a problem for you? [2 marks]
- Now suppose that you start a large file transfer over TCP that takes half an hour to complete, and your laptop's link-layer association changes during the file transfer. Is the changing association likely to be an issue for you? [4 marks]
- If you identified any potential problems, suggest a few ways in which you might work around them. [3 marks]
(Adapted from Computer Networking, 3rd ed, review question 6.4)
Supervision 3
3.0. Network layer protocols
- Draw the structure of an IPv4 packet and an IPv6 packet. Briefly describe the purpose of each IP header field. (You might want to make use of Wireshark to examine some real-life IP headers.) [10 marks]
- Where in this structure would you look to find a link-layer header (e.g. Ethernet) and a transport-layer header (e.g. TCP)? [2 marks]
- Automatic configuration is the process by which a host obtains an IP address and other details necessary to communicate at the network layer.
- IPv4 autoconfiguration is handled by DHCP. Describe the configuration parameters which DHCP typically provides to hosts. [4 marks]
- Compare and contrast DHCP with two different IPv6 autoconfiguration mechanisms, in terms of
- the configuration parameters provided to hosts,
- the interactions between hosts and the configuration server, and
- the design motivation
- Describe the evolution of IPv4 addressing (class-based networks, subnetting, CIDR) including, for each:
- the basic operation
- the motivation for this scheme's introduction
- how a router looks up the next hop for a packet
- During the last few years, almost all of the remaining IPv4 address space has been allocated. State a few consequences this could have on the efficiency of IPv4 addressing and routing. [3 marks]
3.1. IPv6 transition mechanisms
IPv6 transition mechanisms exist to enable hosts to communicate using IPv6 over an infrastructure which is still partially IPv4-based. They generally involve encapsulating or tunnelling an IPv6 packet inside an IPv4 packet for part of its journey.
- During the initial rollout of IPv6, network support for IPv4 remains ubiquitous. So why might two dual-stacked (i.e. both IPv6- and IPv4-capable) hosts want to communicate using IPv6 if they could continue to do so using IPv4? [3 marks]
- Compare and contrast the operation of two different IPv6 transition mechanisms. [8 marks]
- Transition mechanisms are considered to be less reliable than native IPv6 connectivity. Explain why, with examples. [4 marks]
3.2. Routing protocols
- State the purpose of routing protocols and routing tables. [2 marks]
- What is an Autonomous System (AS)? Contrast interior and exterior routing without describing in detail specific routing algorithms or protocols. [6 marks]
- What are the pros and cons of distance vector versus link state routing protocols? Give examples from protocols in use today. [10 marks]
- Where are hybrid schemes employed and why? [5 marks]
- Find out how to view the IPv4 routing table on your computer. How might this differ (in ways other than size) to the routing table on a router on the college or university network, and to that on a router connected to an Internet Exchange Point (e.g. LINX)? [3 marks]
Note: you can obtain the current routing table from some ISPs' core internet routers via a looking glass or route server which is sometimes made available to the public as a debugging aid. For example, Hurricane Electric's route server offers this feature; open a Telnet connection (using the telnet command if you have one, or PuTTY) to route-server.he.net and type the command show bgp ipv4 unicast. Bear in mind that this command may take a while to return, and formatting the output can be quite taxing on the router's CPU, so be gentle!
(First part of question is loosely adapted from 2008 Paper 8 Question 3)
Supervision 4
4.0. UDP
- UDP provides very few features above those provided by IP, and is used by applications which do not require TCP's reliability and flow control (e.g. live video streaming). Why could such an application not just use IP directly without a transport layer protocol? (State a feature provided by UDP but not by IP.) [2 marks]
- DNS (the Domain Name System, an application layer protocol used to look up the corresponding IP addresses of host names such as www.cl.cam.ac.uk) originally only used UDP. Suggest reasons why DNS might have been designed based on UDP rather than TCP. [5 marks]
- Recently the internet has started to deploy DNSSEC (DNS Security extensions), which involves transmitting cryptographic signatures along with DNS data. These signatures are sometimes multiple kilobytes in size. Why might this motivate the use of TCP rather than UDP for DNS? (No specific knowledge of DNSSEC is required to answer this question.) [3 marks]
4.1. Simplified TCP flow control
This question is adapted from 2002 Paper 9 Question 3, which is actually a Digital Communication II question. You should still be able to answer it, but you may give less detail than a Part II student might!
TCP incurs loss to discover the available capacity.
- Why does it do this? [1 mark]
- How can packet loss usually be detected without the sender waiting for an ACK timeout? How quickly can an overflowing buffer be detected? [2 marks]
- Describe the AIMD (Additive Increase, Multiplicative Decrease) mechanism, and fast retransmit, and show how this leads to the characteristic "saw tooth" throughput behaviour of TCP over time. [5 marks]
- Consider a TCP connection operating in steady-state whereby each time the congestion window increases to W segments a single packet loss occurs (i.e. fast retransmit is working as intended, the congestion window is oscillating around the maximum capacity of the channel, and there is no other traffic competing for the channel). In terms of W and the round trip time (R), derive a simple formula for the time between the minimum and maximum data rates achieved. In this optimal scenario, how many packets are sent between each loss event? [4 marks]
- Derive the connection's average throughput in terms of the fraction of packets lost (p), the connection's round trip time (R), and the segment size (B). [4 marks]
- Under what conditions is this very simplistic model likely to be accurate? [3 marks]
4.2. Less-ideal TCP flow control
-
Consider this plot of CWND versus time for a TCP connection.
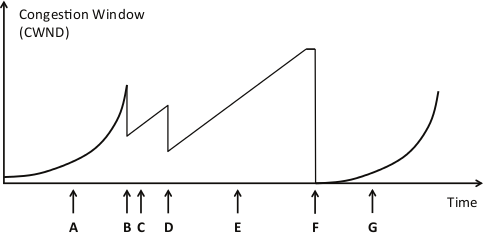
At each of the marked points A through G along the timeline, indicate what event has happened, or what phase of congestion control TCP is in (as appropriate), from the following options: Slow-Start, Congestion-Avoidance, Fast-Retransmit and Timeout. [7 marks]
- What happens if one or more ACK packets are lost? [8 marks]
4.3. TCP performance
Use the approximate equation for throughput as a function of drop rate:
throughput = (√1.5 × MSS) / (RTT × √p)
Assume RTT, the round trip time, is 40 ms and MSS, the maximum segment size, is 1000 bytes. p is the proportion of packets which are dropped: one packet is dropped in every p packets. In the following questions ignore packet headers in your calculations.
- What drop rate p would lead to a throughput of 1 Gbps (1 Gigabit per second)? [1 mark]
- What drop rate p would lead to a throughput of 10 Gbps? [1 mark]
- If the connection is sending data at a rate of 10 Gbps, how long on average is the time interval between drops? [1 mark]
- What window size W (measured in multiples of the MSS) would be required to maintain a sending rate of 10 Gbps? [1 mark]
- If a connection suffered a packet drop on reaching 10 Gbps, how long would it take for it to return to 10 Gbps after undergoing a fast retransmit? [1 mark]
- What can you conclude about TCP's performance on high-capacity links? [4 marks]
4.4. TCP and buffers
Take a look at this video demonstration of TCP rate control from a previous version of the lectures (and see also the notes about the video).
- If two hosts are connected by a 100 Mbps link with a round-trip time of 200 ms, how big (in bytes) should the buffer be to maximise link utilisation? How long does it take for a packet to traverse an almost-full buffer? [2 mark]
- Suppose the link shown were shared with a UDP-based telephone call. What would be the effect on this call? How might this effect be avoided? [4 marks]
- What might happen if you were to make the buffer much smaller (e.g. 1-2 packets)? [4 marks]
Supervision 5
5.0. More DNS—practical
A tool called "DiG" is used to interrogate DNS servers for debugging purposes. It's fairly commonly available on UNIX systems (including linux.ds.cam.ac.uk which you can probably SSH to). Familiarise yourself with the dig command, and in particular its +trace option which performs an iterative DNS query starting at the root servers and tells you the steps involved. (The manual page, also viewable with the command man dig, provides documentation; Paul Heinlein has also provided a quick tutorial.) If you don't have access to a machine with dig installed, there is a web-based version available (the "Trace" checkbox corresponds to the +trace command-line option).
- Explain the difference between a recursive and an authoritative DNS server. Which is responsible for performing iterative queries like those done by dig +trace? Which should maintain a cache?
- Find at least five different types of DNS record via dig and briefly explain their purpose.
- Obtain a trace of the DNS delegation path for a host name of your choice (e.g. www.cl.cam.ac.uk). Explain what the output means.
- Briefly explain how you might obtain a similar trace of an iterative query by hand without using the +trace option.
5.1. Client/server vs. peer-to-peer
- Compare (briefly) the relative merits of client/server and peer-to-peer application models. [4 marks]
- Classify each of the systems below as client/server, peer-to-peer or hybrid, and explain why the designers may have decided to implement the system in that way:
- eBay
- Skype
- BitTorrent
- Telnet
- DNS
- The Cambridge supervision system can be thought of as a peer-to-peer network. The department or your college acts as a rendezvous point or tracker, keeping lists of students and supervisors and enabling them to communicate directly, with the intention that the supervisor will (in theory!) pass knowledge data to the student. Furthermore a student who has taken the course may then choose to become a graduate student and rejoin the network as a supervisor in order to reshare the data. Comment on the durability and scalability of this system. [2 marks]
5.2. HTTP performance
A quick glossary:
- In traditional non-persistent HTTP, each TCP / HTTP connection can only transfer one file. To transfer multiple files, the browser must close and re-open the TCP connection between each file.
- In persistent HTTP (part of HTTP/1.1), the browser can keep the TCP / HTTP connection open after downloading a file in order to download subsequent files.
- Persistent HTTP can also optionally use pipelining which means that a server can make a second (or subsequent) request before the first response has finished (the second file will be sent immediately as soon as the first download has finished, without waiting).
- Recent browsers also use parallel HTTP connections to download multiple files simultaneously.
- By response time I mean the time from the user requesting a URL to the page and all its components (images, etc.) being completely downloaded.
Here, we consider the performance of HTTP, comparing non-persistent HTTP with persistent HTTP. Suppose the page your browser wants to download is 100K bits long, and contains 10 embedded images (with file names img01.jpg, img02.jpg, … img10.jpg), each of which is also 100K bits long. The page and the 10 images are stored on the same server, which has a 300 msec roundtrip time (RTT) from your browser. We will abstract the network path between your browser and the Web server as a 100 Mbps link. You can assume that the time it takes to transmit a GET message into the link is zero, but you should account for the time it takes to transmit the base file and the embedded objects into the "link." This means that the server-to-client "link" has both a 150 msec one-way propagation delay, as well as a transmission delay associated with it. In your answer, be sure to account for the time needed to set up a TCP connection (1 RTT).
- Assuming non-persistent, non-parallel HTTP, how long is the response time for this page? Be sure to describe the various components that contribute to this delay.
- Again, assume non-persistent HTTP, but now assume that the browser can open as many parallel TCP connections to the server as it wants. What is the response time in this case?
- Now assume persistent HTTP (HTTP/1.1). What is the response time, assuming no pipelining?
- Now suppose persistent HTTP with pipelining is used. What is the response time?
[4 marks]—Computer Networking, 3rd ed, review question 2.8
5.3. Other application-layer protocols—practical
- Describe the main protocol messages exchanged and actions taken in a SMTP transaction (in which a client sends email to a server). Try interacting with a SMTP server yourself.
On the University network, you can use the Computing Service's SMTP relay, ppsw.cam.ac.uk port 25. You can interact with it using the Telnet command on any Linux system and some Windows systems – telnet ppsw.cam.ac.uk 25 – or use PuTTY in Telnet mode.
See if you can successfully deliver a syntactically-valid email message using handcrafted SMTP to my address. - Would this method of using a Telnet client to manually enter protocol messages be possible for other application layer protocols?
- Pick some other unencrypted application-layer protocol (not SMTP or HTTP as we've already talked about those).
- Use Wireshark to capture a single transaction of that protocol; use a capture filter to exclude packets of other protocols.
- Select one particular packet which shows something interesting happening in this protocol, and view the dissection of this packet (the panel between the packet list and the raw hexadecimal data). Describe the purpose of this packet and label on a screenshot some important fields.
- How would you go about reimplementing Wireshark's packet dissector, i.e. writing code to turn the raw packet data into a human-readable inventory of the contents of the packet?
Supervision 6
There are no supervision questions on multimedia networking or data centres. I think we've adequately covered the penultimate topic's very brief look at multimedia networking in previous supervisions, but feel freek to ask if you are unsure of anything. We'll talk about data centre networking in the supervision, but since it's not examinable I won't ask you to prepare work on this.
So, for your final supervision I suggest you answer a few past exam questions. Here's a selection for you to choose from.
Bear in mind that the course was substantially refactored in 2011; several of these are from older courses but have been selected to roughly align with the material you have covered. Digital Communication II is actually a closer match for parts of the new course than Digital Communication I is.
Please tell me at least 2 working days before the supervision which exam questions you will be attempting / have attempted (some of the examiner's notes need digging out of a locked filing cabinet stuck in a disused lavatory with a sign on the door saying 'Beware of the Leopard').
TCP
- 2011 Paper 5 Question 6 (TCP and IP fragmentation)
- 2010 Paper 5 Question 8 parts (b), (c) from Digital Communication I (TCP/IP packet processing on hosts)
- 1998 Paper 8 Question 2 from Digital Communication II (interesting high-level question on TCP)
- 2004 Paper 7 Question 2 from Digital Communication II (TCP)
- 2003 Paper 8 Question 3 from Digital Communication II (TCP)
Generic flow control
- 2012 Paper 5 Question 5 part (a) (latency, capacity and layer interactions)—don't bother answering part (b) as you've already done a superset of this question
- 2006 Paper 7 Question 2 from Digital Communication II (flow control)—possibly uses terminology not covered in this course, but you can probably work out what it means
Generic error control
- 2011 Paper 5 Question 5 (design a transport layer protocol)
- 1998 Paper 5 Question 3 from Digital Communication I (packet loss and error control)—note that "ARQ" is a somewhat old term for "error control" i.e. retransmission of lost packets; in the case of TCP, this is tied somewhat to flow control but is logically separate
Layering
- 2010 Paper 5 Question 8 part (a) from Digital Communication I (TCP/IP packet processing on hosts)
- 2007 Paper 5 Question 3 from Digital Communication I (layering and multiplexing)
- 1996 Paper 6 Question 3 from Digital Communication I (layers / protocol design)
- 2008 Paper 7 Question 3 from Digital Communication II (OSI model bookwork, and layer violations)
- 1995 Paper 5 Question 3 from Digital Communication I (layering + routing/addressing)—note that a "MAC level bridge" would these days more usually be called a switch
Routing, forwarding and addressing
- 2013 Paper 5 Question 6 parts (b)-(f) (routing loop avoidance in Ethernet and IP)
- 2008 Paper 6 Question 3 from Digital Communication I (addressing and routing)
- 2010 Paper 9 Question 6 from Digital Communication II (routing protocols)—note that part (c) is not covered by this course, but I have mentioned it in supervisions
- 1998 Paper 6 Question 3 from Digital Communication I (protocol design)
- 1995 Paper 5 Question 3 from Digital Communication I (layering + routing/addressing)—note that a "MAC level bridge" would these days more usually be called a switch
Media access control
- 2012 Paper 5 Question 6 part (b) (multiplexing)
- 2009 Paper 8 Question 5 from Digital Communication II (media access control and QoS)
Application Layer
- 2013 Paper 5 Question 5 (HTTP, caching and Content Distribution Networks)
- 2012 Paper 5 Question 6 part (a) (DNS)
- 2010 Paper 5 Question 7 from Digital Communication I (Skype; protocol design and tradeoffs)
Miscellanea
- 2011 Paper 5 Question 4 (essay question on whether the Internet has been a "success"—exactly the kind of question you shouldn't touch with a barge-pole in the exam, but try it if you like!)
- 2007 Paper 8 Question 4 from Digital Communication II (routing protocols + impact on other protocols)