Adaptation of the DAN workstation to allow experimentation with cacheing streams and processing multimedia data is still in its initial stages. Both hardware and especially operating systems software enhancements need to be made to support the mechanism. These are being carried out as part of the ``Operating System Support for the Desk Area Network'' project (usually referred to as DANOS) which has just started. However, some preliminary results showing the use of an input stream cache are reported on in this section.
The existing DAN CPU node is capable of a limited form of input stream caching. The incoming stream must use a specialised ATM Adaptation Layer (AAL), and there is no mechanism for handling data loss. For an initial demonstration and exploration of the ideas, this presents no problem, since the stream can be generated in the correct format (or reformatted) by another node on the same DAN. In addition there is insufficient status information from the hardware to allow the operating system to become fully ``cache aware'', but there is sufficient for a limited form of the sliding VM window mechanism to be used.
For the stream cache experiments the CPU secondary cache was divided
into two parts. The bottom 128Kbytes was used in the conventional
manner as a 2 way set associative cache of the 1Mbyte of main memory
of the machine. The upper 128Kbytes of the cache held the stream.
All the experiments made use of a memory server that was implemented
in software on one of the other nodes of the DAN. This takes
8 cell times (33.6 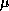 s) for a cache line fetch, rather than 2 using
the hardware server, but it permits information on miss address and
time to be recorded.
s) for a cache line fetch, rather than 2 using
the hardware server, but it permits information on miss address and
time to be recorded.
A version of the Wanda microkernel was extended to provide minimal support for the stream cache. An extra Quality of Service (QoS) type ``Cache Stream'' was added to the ATM connection establishment protocol stack, to cause the circuit to be setup so that incoming data would flow into the cache hardware rather than being delivered through the kernel I/O buffers. In addition use was made of the MMU to provide the sliding VM window. Page table entries were setup for the region of address space used for the virtual array of incoming frames to map them onto the stream cache hardware. All the addresses were initially marked invalid. Thus the sliding window starts with zero length. As stream data arrives it expands to 128kbytes to match the cache size before it starts to slide through the address space. A signal should be provided by the stream cache hardware to match movement of the window to data arrival, unfortunately limitations in the hardware prevented this from being used and software emulation was necessary.
A traffic generator was used as the source of the stream. This made
simulated video frames of 64 64 pixels each of 32bits, making a
whole frame 16kbytes. This frame was packed into cells using the
special cache AAL. The rate of delivery of the data (both the
inter-cell and inter-frame delay) could be varied.
64 pixels each of 32bits, making a
whole frame 16kbytes. This frame was packed into cells using the
special cache AAL. The rate of delivery of the data (both the
inter-cell and inter-frame delay) could be varied.
As an example load on the CPU a PAL compiler was used. This consists of three distinct phases: reading and parsing the input equations; optimising them and forming the sum of products form; and writing the output file. To understand the memory behaviour of this application the cache was set to be small (256 lines, direct mapped) and the memory server set to record all addresses fetched. Figure 4 shows the trace for the operating system startup and the execution of the compiler. The three vertical lines indicate the changes between the phases of the example program. Using a dump of the kernel segment map the use of the various areas of memory was determined, and is shown on the right of the figure.

Figure 4: Address of Cache Miss vs Miss Number
The first 10000 misses show the kernel copying the user process to its
execution address, and clearing both the user and kernel uninitialised
data segments![]() (bss). Then the kernel
performs various initialisations before starting the user process.
During the input stage of the compiler the parser code is frequently
fetched. In the optimise phase the process has to expand its memory
heap (malloc) space, and a new segment is seen in use. The
kernel activity seen is the timer interrupt code, and the running of
the network connection timeout thread at about miss number 50000.
(bss). Then the kernel
performs various initialisations before starting the user process.
During the input stage of the compiler the parser code is frequently
fetched. In the optimise phase the process has to expand its memory
heap (malloc) space, and a new segment is seen in use. The
kernel activity seen is the timer interrupt code, and the running of
the network connection timeout thread at about miss number 50000.
Whenever a cell on a stream VCI arrives at the CPU node the processor has to be stopped while the stream data is inserted into the cache. This time could be reduced or even removed with a fancier design of the cache (dual porting for example). In practice, as shown below, the increase in running time of processes not using the stream cache is relatively small - certainly a lot smaller than the delays caused if the kernel had to process data with similar arrival rates.
The PAL compiler was then run with the cache setup in stream mode as described above. Data streams at various rates was sent into the s-cache region, while the kernel and PAL compiler used the other region as a combined i&-cache. Table 1 shows the running time of the three main phases of the PAL compiler, executing on the CPU node with various data rate streams arriving. The input and output of the compiler were done to memory buffers so network and disc latencies are not included.
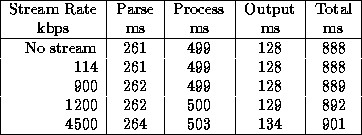
Table 1: Pal Compiler Execution Time with Cache Stream
A demonstration was used to investigate the use of the stream cache. ``Spot the Ball'' receives a stream of frames and follows a ``ball'' as it moves around between successive frames. The ``ball'' consists of a 3x3 grid of pixels of a well defined value, other pixels in the frame are randomly coloured. A very simple algorithm is used for the search; it was specifically designed to show up some of the characteristics of the stream cache mechanism.
This application is clearly of no practical use, but it is closely related to tasks that might be performed in a multimedia machine. If a seminar were being relayed, for example, the machine could automatically track the speaker moving around the podium permitting both a centred view of the speaker (which would have to pan smoothly to avoid making the viewer sea-sick) and an unobstructed view of, say, the blackboard being pointed at. In this example the matching algorithm would be more complex but the principles remain the same.
The stream generator assembles the frames and transmits them a line at a time. Each frame is given a different random background, and between frames the ball is moved randomly in both dimensions. Each line is sent through a standard system call, which results in the most likely shape of the stream entering the fabric to be bursts of eight back-to-back cells.
The spotter program, running on the CPU node, defines a frame structure and treats the virtual memory range into which the stream is being received as an array of these frames. This is a very natural way to address the stream - it is simply indexed by frame number. Some care has to be taken to ensure that when the VM range is exhausted the addresses are adjusted. The incoming stream will simply wrap round and begin again at the start of the region, so all the receiving process needs to do is subtract the size of the region from the base address it uses for its ``array''. A ``cache-aware'' operating system will have to provide a mechanism for informing the process when to do this.
The algorithm used by the spotting process is to start from the location found for the ball in the previous frame and spiral outwards checking individual pixels until one of the correct colour is found. This is then used as a centre point about which the surrounding pixels are checked. Clearly this is inefficient, but it is very easy to follow the behaviour of the program and hence the system. Provided it is not trapped by the kernel for using an address outside the VM window, the system will stall if the data accessed has not arrived. For the purposes of the experiment, rather than stalling the CPU, it was made to execute a loop in which it spins checking the cache tags for the arrival of the data and incrementing a counter. Since the loop is executing from the CPU internal cache and interrupts are disabled this count gives a measure of the time spent waiting for the data.
The frame size was set to 6464 with 32 bit pixels, giving
16kbytes per frame. The sliding VM window was thus set to move in
16kbyte blocks, causing a ``future access'' address fault to occur
only the first time a frame was touched. The source was set to
generate 10 frames per second, giving a data rate of 1Mbit/s. In one
sampled frame the search followed the path shown in figure
5. The start point was (32,32) and the ball, shaded in
the figure, had moved to (30,36). In each square the dally count of
the first access to that location is shown. The delay waiting for the
first location (marked `X') includes the interframe gap and ``future
access'' trap, so is not comparable, and is not shown.
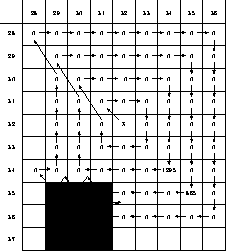
Figure 5: Time (in CPU loops) for Search Access
The results give a clear picture of the operation of the stream cache. All lines prior to the first location (i.e. with a y component less than 32) will have arrived before it so the access delays to pixels in those lines are zero. The time spent searching round the first turn of the spiral is sufficient for the data in the line below the `X' to have arrived so the CPU does not stop. By the second turn of the spiral the CPU is beginning to get ahead of the stream and it is seen to stall for a while waiting for the lower right pixel (34,34). The same effect is seen on the third turn, but the stall at (35,35) is shorter because the CPU has done more work traversing the longer path. Just after this the ball is encountered for the first time and a defect of the algorithm becomes clear-it searches in locations that the ball cannot possibly occupy. This extra work and the fourth cycle round the spiral take long enough that the CPU is not stalled in the lower right access to (36,36). The ball is then discovered, with a final stall when checking for its lower left corner (29,37).
Once the ball has been located the program has no interest in the rest of the data for that frame and it will progress to the next frame. It is at this point that it is trapped for doing an access far enough into the future to warrant rescheduling the process. The simple handler just adjusts the sliding window and returns control to the user process dally loop. Despite this simplicity, control is given to the kernel and it is clear where an improved scheduler would fit in. The trapping of past accesses was also observed, by making an access more than eight frames into the past.