The Desk Area Network (DAN) is an architecture for a multimedia workstation. Its main feature is the use of an ATM interconnect between the parts of the machine. The architecture was proposed in [6] and has been developed by a series of research projects [8][5][2]. The aim is to provide improved system performance by the use of a device and processor interconnect which:
Similar work is in progress in the ViewStation project [1], and [9], where again ATM is used as the basis for a multimedia machine. The assumption that future high speed networks will be packet based [3] has led to an approach like the DAN but using packet switching internally [4].
Since it is intended for use within a machine the architecture specifies a reliability requirement - when a cell is sent across the DAN, either it reaches its destination or the source is informed that it did not. This allows great simplification of internal protocols. All devices in the system communicate using ATM cells, both for control and data transfers. Devices are designed to support streams flowing into, out of, or through them. The use of ATM within the machine as well as in the local and wide area networks greatly simplifies the network interface. The connection oriented nature of all the data flows is used both to provide routeing information from source (possibly over a LAN/WAN) to destination, and to provide context at the end-point; for example the virtual circuit carrying video stream may have routeing and quality of service information attached to it as it traverses the network, and window co-ordinates in the framestore.
The Desk Area Network project has developed a multimedia workstation as a demonstrator of the architecture. A typical configuration is shown in figure 3. The machine has video and audio capture and presentation nodes and a DSP node in addition to processors and memory. The interconnect of the machine is provided by the ATM switch fabric designed for the Fairisle project [7]. Further details of the demonstrator may be found in [2] and [5].
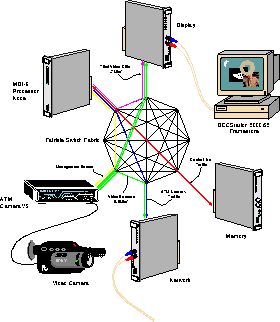
Figure 3: The experimental configuration
A CPU node was developed to allow investigation of the DAN as a
processor to memory interconnect. It also permitted the stream cache
ideas to be explored. The node consists of an ARM600 RISC
microprocessor (which includes an internal MMU and 4K of primary
cache) and 256k of secondary cache. The secondary cache controller
provides the connection to the ATM fabric and in the event of a cache
miss will exchange an ATM cell with one of the memory nodes. The cache
is write-back, so the exchange may need to flush a dirty cache line as
well as fetch the new one. The request cell therefore contains the
requested address and optionally, the data to be written back and
write address. The reply consists of the requested data and its
address![]() . Using a cache line of 32
bytes allows room for the header and address information to be
conveniently fitted into a single ATM cell.
. Using a cache line of 32
bytes allows room for the header and address information to be
conveniently fitted into a single ATM cell.
The use of the DAN for both multimedia and cache traffic has been investigated using the demonstrator. The main problems found were in the implementation rather than the architecture, in particular the re-use of the Fairisle switch fabric (which was built as the core for a LAN ATM switch) provided a performance bottleneck. Cache service was shown to be possible in the minimum 2 cell times required for a request-reply exchange between the CPU node and memory. Interference between cache traffic and high bandwidth streams was minimal, and careful interconnect scheduling could further reduce this.
The cache controller on the DAN CPU node currently only supports division of the cache into fixed size regions. In fact both the region of the cache is fixed and the range of remote memory addresses (normally 1Mbyte). Use of the local MMU and a second mapping at the memory node prevents the fixed address range being a problem; however it would be preferable if the size of cache memory for each region were variable. The controller is connected to the DAN interconnect, and is geared to moving ATM cells between the cache and the interconnect. This is exactly what is required for an s-cache, and regions may be marked as an end-point for an incoming data stream. Physical constraints on the current version of the CPU node have prevented regions of the cache also being used as a stream source.