The principle behind cacheing in computer systems is to keep information that is likely to be used in the near future in a store that can be rapidly accessed. This is true on many scales, from retaining information in the sense amplifiers of a DRAM, up to keeping copies of World Wide Web pages in the local server. In this paper we are concerned with the CPU cache, that is the place where the processor keeps data and instructions that it is probably likely to use soon. In many existing systems the cache is divided into sections, possibly of differing sizes, for instructions (i-cache) and data (d-cache). This division is made both because of the observed differences in the access patterns and to prevent interference between the two types. We propose a third portion of the cache, the stream cache (s-cache), for holding stream based data. Both processing of an incoming stream of data and producing output can benefit from this technique; these themes are developed in the next two sections.
A second method for dividing the cache is to force different areas of memory to be separately cached. This can be especially useful in a system where tasks have processing guarantees associated with them - in the same way as in a network switch guaranteed and best-effort traffic may be separated, the operating system may wish to allocate a region of the cache for exclusive use by a process with guarantees, and the rest to the best-effort processes. The operating system will certainly want to be able to dynamically alter this split based on the characteristics of the workload, to enable the most effective use of the cache memory. This desire for this form of dynamic allocation of cache memory applies equally to i-cache, d-cache and and s-cache. Furthermore, once the operating system starts becoming aware of the cache as a machine resource, the next step is to consider if the ratio of the service time of the cache to the processor performance is such as to make it attractive to invoke the processor scheduler when the resource is unavailable (i.e. on a cache miss).
Normally the basis of cacheing is locality - the idea that if some data is used then it is likely that the same or nearby data will also be accessed soon. Therefore when an area of memory is referenced it is retained in the cache and old data may be discarded (or flushed). When processing a stream it is likely that the data that will be accessed is amongst that which has most recently arrived. Hence, the s-cache should hold the most recent data from the stream and new data should cause old to be thrown out. With an s-cache architecture, data arriving from the stream is placed directly into the cache; it does not pass through main memory which avoids unnecessary buffering and a further traversal of the interconnect. A section of the cache effectively becomes a circular buffer holding the latest stream information; update of the cache is asynchronous rather than triggered by a CPU cache miss.
When the CPU tries to access stream data there are three possible outcomes:
The first two cases have the cache behaving in a fairly standard way, though being updated rather than invalidated by the network traffic. The third is more complicated. The data from the stream has been discarded from the cache and is now lost - there was no main memory behind the cache entry. This is not considered a problem, as in the case of a traditional data stream (for example coming from a fileserver) the process can generally perform some rewind operation, while in the case of a real-time stream, the need to access the lost data suggests that processing is getting so far behind the stream that re-evaluation of the processing task and then resynchronisation is required.
To allow an application to use a cached stream the operating system
needs to present an abstraction of the low level behaviour. The stream
data will need to be addressed in some way. Most streams will have
some frame or temporal structure that the application will wish to
use; this can be conveniently mapped onto a range of the process'
virtual address space![]() . Thus the process may access the stream as an array indexed by
frame number.
. Thus the process may access the stream as an array indexed by
frame number.
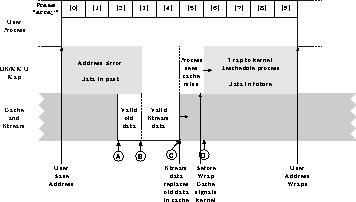
Figure 1 illustrates how the address mapping may be done. User addresses will span some space, possibly having to wrap after a large time has passed. As shown, the operating system will set up the memory management unit (or a more specialised cache address management unit (CAMU)) to trap some of the range and allow other addresses to access the cache. Below point B, accesses are trapped as being too far into the past to be in the cache. This boundary will move in discrete steps (probably some multiple of the page size, though with a CAMU these may be made appropriate to the stream parameters), so that some valid data will be inaccessible (from point A to B) - this is the next data that will be overwritten. Addresses between points B and D are mapped through to the cache. The stream is arriving into this range, so for the lower addresses the processor sees a cache hit and retrieves the data rapidly. Above the stream arrival point (C) the processor is blocked by a cache miss until the data arrives. Past point D the OS considers the data will be long enough arriving that it is worth suspending the process and rescheduling the CPU.
To implement this mechanism the operating system will need to alter the virtual memory mappings to reflect the arrival of data on the stream. Therefore the cache controller needs to inform the OS after some amount of data has arrived. The block size after which the mappings are modified is one of the parameters that can be used to tune the system. If it is too big, a lot of valid data becomes concealed (i.e. the gap between A and B becomes large); if too small, the system will be constantly dealing with cache interrupts and moving the window. A specialised CAMU could automate this process and relieve the OS. Similarly the application will need to know when to wrap round its virtual address range; this may be signalled by an event from the operating system, or be explicitly written into the program.
The second main problem is managing data loss. This is not a problem
for streams originating on the same machine, since the communication
is reliable; however, the majority of traffic may experience some
loss![]() . Loss of data that is accessed should be
treated as an addressing exception, with the operating system and
therefore user process being signalled. Loss of data that is not
accessed need not be signalled, though event statistics may be
useful. However, the hardware has to be able to recover and ensure
addressing consistency - for example, when data loss is noticed the
corresponding cache line could be marked as ``missing'', resulting in
a memory error being raised if it is accessed. The details of noticing
data loss depend on the transport mechanism used on the stream, in the
worst case buffering of a complete block would be required - in the
DAN demonstrator built, this would be done by some other node of the
machine, such as the network interface.
. Loss of data that is accessed should be
treated as an addressing exception, with the operating system and
therefore user process being signalled. Loss of data that is not
accessed need not be signalled, though event statistics may be
useful. However, the hardware has to be able to recover and ensure
addressing consistency - for example, when data loss is noticed the
corresponding cache line could be marked as ``missing'', resulting in
a memory error being raised if it is accessed. The details of noticing
data loss depend on the transport mechanism used on the stream, in the
worst case buffering of a complete block would be required - in the
DAN demonstrator built, this would be done by some other node of the
machine, such as the network interface.
There are two major advantages to the stream cache system. Firstly, the data from the stream is placed where it is going to be used, namely in the CPU cache. Hence, even if data is not accessed in strictly temporal order, recent information will still be found in the cache. Secondly, the hardware manages the fine grained resynchronisation with the stream, imposing no overhead other than that necessary to wait for the data to arrive. If the window size and advance step parameters are carefully chosen there should be a large performance improvement over traditional stream reception systems. This may be compared with the technique of dallying in an interrupt routine or prior to rescheduling on a semaphore block.
A similar argument to that in the previous section applies in the case of stream output. It is quite likely that output streams will be built up in a random access fashion, and are therefore best formed in the CPU cache. It is commonly believed that network protocol code behaves badly with write-through caches because of the random bit field accesses that tend to be done when building headers.
Output from the cache differs in two important respects from input. In the input case there was no necessity for arriving data to actually be used, but on output the data sent must come from somewhere. This could be achieved by using the data from the previous frame if new values have not been written. Applications which are producing frames by applying inter-frame differences would benefit, but merging of the old and new data could cause unwanted complexity. A second method would be to insist that cache lines for the whole block exist in the cache, written either by the CPU or an input cache stream. In either case the CPU must not be able to alter the cached value of data that has been sent on the stream, or it would be attempting to change the past.
The second choice is how and when the data gets sent. This is in many ways similar to the problem experienced in operating systems with have an integrated VM and IO system such as Multics and Mach. A simple system would be for the CPU to force a ``flush'' operation on every line, or set of lines, to be sent. This has the disadvantage that it may tie up the CPU for the entire transmit time. A rather more satisfying scheme would be for the data to be transmitted from the cache without processor intervention, in much the same way as incoming stream data arrives. Once a block has been marked to be sent the CPU would be free to continue work, though it should not be permitted to modify the data being sent. Transmission could be done automatically by the hardware to achieve the desired outgoing stream characteristics; or, rather more practically, by the processor issuing an explicit send on the data block.
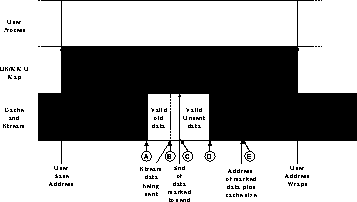
Figure 2: Addressing an Output Stream
Operating system support via the MMU is again required both to ensure that the CPU may read but not alter data that it has sent, and to provide the address range for overlaying the stream. The address map structure will be something like that shown in figure 2. The same sort of sliding virtual memory window could be used as for the incoming case. Again accesses too far into the past (before point A) are trapped. The read-only region (A-C), protects history and contains the data that is currently being sent (point B which moves to meet C). In addition the operating system will need to keep track of the furthest point (D) into the future touched by the user process. As there is only limited cache space, when new stream information is written to the cache, some data from the past must be lost. When a new largest address access is trapped the system must compare it with the current send point plus the cache buffer size (point E). Accesses before this point will cause the window to slide, discarding old data. However, if the window were to move past this point then data that has not been sent would be overwritten corrupting the outgoing stream. These accesses need to be trapped and signalled as an exception. The process will inform the operating system when data is to be sent, so the read-only region can be extended.