spEEDO2: Energy Efficiency through Debug suppOrt 2
WEB PAGE UNDER CONSTRUCTION - Sept/Oct 2015 ... ... but never finished!
Local Industry - Can you help ?For spEEDO2 we need to get buy-in from chip houses. Can you help? We are making an 'IP package' to assit you getting started and this may be contributed to Accellera. Link not ready yet. You can help by
Please get in touch if you can help. |
spEEDO2 --- Summary
In this project we will continue the themes from spEEDO1 that combine ongoing simulation, compiler and measurement work at the University of Cambridge Computer Laboratory with existing debug infrastructure from UltraSoC (and elsewhere). Specifically, we will make the next steps in developing a methodology that enables energy conserving decisions to be made at three places in the design flow and tool chain:
- at the architectural design stage,
- at the compiler code generation stage and
- at the operating system and power management task scheduling stage.
Energy use figures from calibrated models and live measurements will be combined both online and offline to provide design insight and assist in scheduling decisions. The debug infrastructure will export this information for viewing and offline processing and combine this with instrumented measurements and models beyond those built-in to the chip. It will also download or recalibrate model digests into the SoC or its boot ROM. A digest is composed of architectural descriptions and weighting coefficients that summarise per-design and per-chip calibration factors for low-overhead and localised energy accounting. These then expedite the dynamic energy accounting onboard the chip
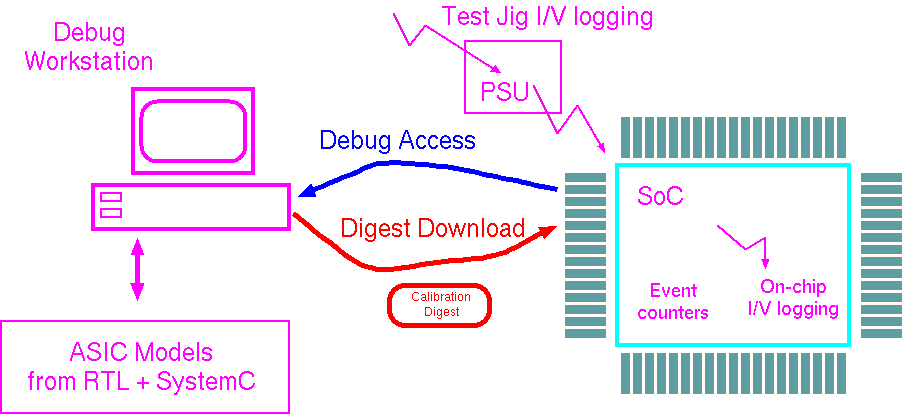
Debug infrastructure typically collects trace information and stores it in buffers with a high-throughput channel between on-chip and workstation tracing resources. It also consists of triggering systems based around watchpoints. Power tracing, like other statistics gathering operations, requires summing, averaging and other statistical analysis. Accurate measurement of current consumption for multiple subsystems is not feasible in the final product, so our approach will most likely use just a few analogue measurements from the system power regulators. These are combined with event counts at strategic subsystem boundaries and projected through a detailed weighting matrix that was mostly computed offline or on the debug host. Such analysis can be done over various time windows, compressing a detailed trace to a trace of statistical variations. Our technology will allow migration of calibration operations between embedded and external implementations, between hardwired and software implementations and through different parts of the system, all within a common framework. Ultimately, the information is exposed through the operating system and run-time system to the compiler (e.g. with an extension of the Android virtual machine) and the application writer / design engineer both at pre- and post silicon design time.
We will develop and disseminate technology concepts and make available some downloadable examples. We will promote the work through various meetings, trade associations and online services.
One Possible Component of the project
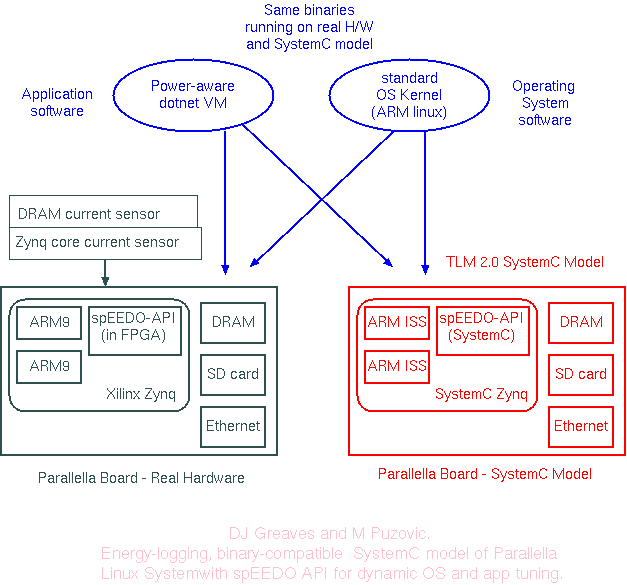
Calibration and Prototyping on Instrumented Parallella
DJ and MP have a SystemC model of the Parallella card that can run the same linux kernel, disk images and applications as the real card. The real card has had current monitors connected and an implementation of the spEEDO1 API placed in its FPGA:
 |
spEEDO2 --- Objectives
The objective is to further develop a new software/hardware interface standard to be adopted by developers of software and hardware for embedded systems, such as mobile phones. Recent advances in computer architecture have added a complete new dimension to the programming exercise: a program should be able to state how fast it would like to run and find out how much power it is using. Integrating this dimension requires exposure of existing low-level hardware infrastructure to the software and the programmer. This infrastructure consists of decisions over how many processing cores should be turned on, what clock frequency (and power supply voltage) to run at and how much of the cache should be turned on. In many systems, such as ARM's big/little approach, there is also a choice over what type of core to run on.
This project will conduct industrial research to develop tools and techniques to realise the potential to increase energy efficiency in electronic systems using detailed information about the specific behaviour and energy use of the system. It has been shown in the (Innovate UK EEC funded) precursor spEEDO1 project, that it is feasible to achieve this by leveraging the capability of debug support interfaces, which are used to identify and fix malfunctions and bugs in the software that defines the systems functionality. The project will research hardware that can utilise the lead partner’s unique debug support interface technology and provide energy data for systems models and higher-level tools that generate dedicated software, energy profiles and control policies in order to optimise the energy use while maintaining the desired functionality of the system. The project will research and design specific hardware interfaces to facilitate dynamic and tools-based optimisation for energy efficiency, in an extended collaboration with several large industrial manufacturers of embedded electronics, that brings a highly-relevant industrial context, which will serve to inform subsequent commercial development of the technology.
Specifically, as stated above, the project will make the next steps in developing a methodology that enables energy conserving decisions to be made at three places in the design flow and tool chain:
- at the architectural design stage,
- at the compiler code generation stage and
- at the operating system and power management task scheduling stage.
Energy use figures from calibrated models and live measurements will be combined both online and offline to provide design insight and assist in schedulling decisions. The debug infrastructure will export this information for viewing and offline processing. It will also install or edit model digests back into the SoC. A digest is composed of architectural descriptions and weighting coefficients that summarise per-design and per-chip calibration factors for low-overhead and localised energy accounting.
University of Cambridge role in spEEDO-2
Draft ideas subject to change before proposal submission...
The performance and energy use of an embedded system is largely determined by its hardware and software architecture. Sometimes these are designed together and sometimes the hardware is mostly or completely designed before the software is coded. The major design decisions are the hardest to change during the development of a project, but they have frequently had the most impact. (A lot of previous work on energy-efficient design has concentrated on small aspects of the system that only have small effects, like compiler flags.) The major choices are on the number and form of the CPU cores, how work is allocated across them, the associativity of caches and the layout of data in DRAM.) In the future, systems will be built on increasingly flexible and general purpose hardware platforms where much of the logic on a particular chip is normally switched off or, indeed, always switched off and never used in that product’s lifetime. (Parameters include : caches can be adjusted in size and associativity; branch predictors can be turned on and off; an out-of-order core is swapped for a simple 5-stage pipeline; etc..) This project will augment standard embedded system design flows so that, at each stage, the designer is able to get rapid feedback on the likely performance and energy costs associated with each design decision. It builds on the work of spEEDO-1 that proposed and tested energy control and monitoring extensions to standard System-on-Chip architectures.
For hardware design, the standard approach for performance estimation is to count the simulation cycles used by a cycle-accurate model of the system. For energy estimation, the standard approach is either to measure the power supply to the actual hardware or to use switching activity records from a layout-accurate simulation where detailed track capacitances are known. These approaches are accurate yet heavyweight. Measurements collected in the spEEDO1 approach enable model calibrations and provide greater insight into the details of energy use. They also enable extrapolation to other software programs running on the same hardware or variant hardware platforms that differ in width of busses or number of instantiated cores, caches and memories. But further work is required to make these insights rapidly available to the hardware or software engineer as they implement their design. Although the compiler tools used by hardware and software engineers are disjoint, the techniques required for performance and energy modelling are the same. The basic (linear form) work estimate is a sum of products where each product is the resource use of a component multiplied by the component’s activity. This must be augmented with communication and stall overheads.
In this project we will take the combined hardware and software components of several recent designs from a corporate embedded system house in RTL and C/ARM assembler respectively. We will use existing homebrew RTL and C compilers at the University of Cambridge (using front ends from Verilator and LLVM) to recompile the designs. We also need the subsystem silicon area and supply current measurements from the corporate. We will augment the existing designs with some spEEDO1 energy instrumentation. We will calibrate our performance and energy flow such that the measurements agree. We will generate scripts or IDE plugins that can be used at the corporate alongside their current tool flow for active designs that gives rapid indication of performance and energy use. We will aim to do it for both hardware and software engineers...
High-level Estimator Tools
Sketch showing rough structure for a tentative, very-high level energy and performance prediction flow based on the abstract syntax trees of the source code:
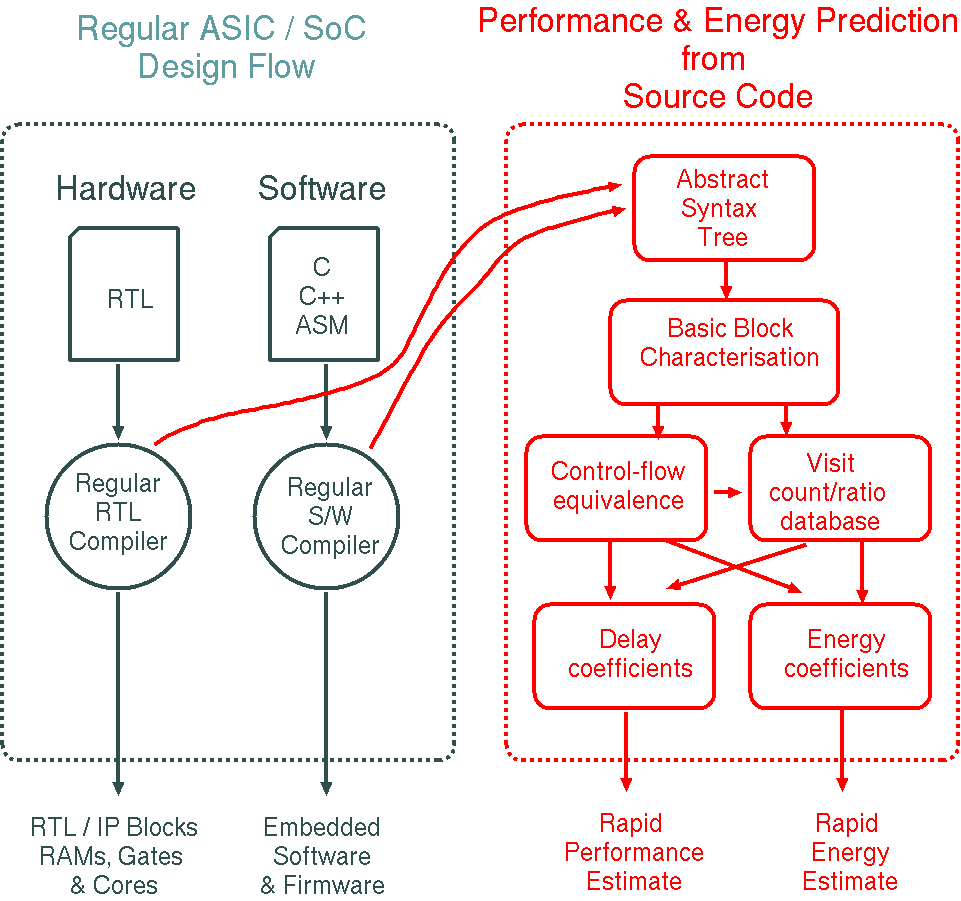
Static analysis can work out which blocks are control-flow equivalent, meaning that if one is run so are all the others in the same equivalence class. Knowing the visit count for one block
therefore gives the counts for all others in the same class. Typically there are only a few (less then 5) blocks where the visit count has an impact and needs to be determined (from external simulation or rough guesses) to get the first guiding result.
We will also explore extrapolation from instruction traces to assist with datacentre design and configuration.
These new performance prediction ideas are currently being worked out in detail in DJG's Kiwi project (scientific acceleration on FPGA)
where, owing to the 3-hour main FPGA compile turn around, it is handy to get rapid feedback
on performance from a preliminary compilation or even interactively inside the IDE as the source code or
quantity of data is edited. (Job run time can then be hours or days for big datasets but this is typically factor of 10 to 50 times faster
than conventional processing so the
investment in the main compile step pays off. Electricity bills are also considerably lower.)
References
The following recent papers cite our spEEDO1 and TLM POWER3 work.
VPPET: Virtual platform power and energy estimation tool for heterogeneous MPSoC based FPGA platforms Rethinagiri, Santhosh Kumar ; Barcelona Supercomputing Center (BSC), Spain, et al. PDF.
Advanced SoC virtual prototyping for system-level power planning and validation Mischkalla, Fabian ; University of Paderborn, C-LAB, Fuerstenallee 11, D-33102, Germany. PDF.
An ESL Timing & Power Estimation and Simulation Framework for Heterogeneous SoCs Kim Gruttner et al. PDF.
...