What is Musketeer?
Musketeer is a workflow manager that dynamically maps high-level workflow descriptions to a broad range of data processing systems.
For more details and our upcoming open-source release, visit the Musketeer page.
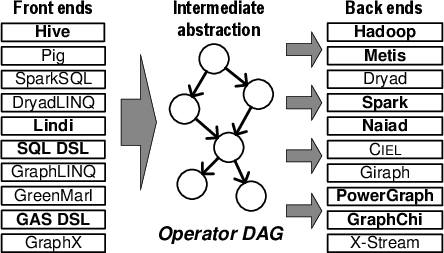
Front-end languages and back-end systems in bold are supported in our current prototype implementation.
Key features
- Multiple front-end languages: complex workflows can be expressed in a variety of ways.
- Automatic translator: automatically translates workflows into seven back-end data processing systems: Hadoop, Spark, Naiad, PowerGraph, GraphChi, Metis and serial C code.
- Performance: up to 9x runtime speedup without user intervention.
- Smart scheduler: automatically decides at runtime which systems to use for a given workflow.
- Cost reduction: by mapping workflows to the most efficient system, Musketeer reduces resource utilization by up to 10x in exchange for slightly increased runtime.
State of the art
Many big data systems have been developed in recent years, but it is hard to decide which one is "best" for a particular workflow. In fact, sometimes a combination of systems performs best or uses resources most efficiently.
Few users can tell the precise trade-offs by intuition; and in addition, porting workflows between systems is tedious, making experimentation time consuming. Hence, users often become "locked into" a system after implementing workflows, despite faster or more efficient systems being (or becoming) available.
This problem is a consequence of the tight coupling between user-facing front-ends (e.g. Hive, Lindi, GraphLINQ) and back-end execution engines (e.g. MapReduce, Spark, PowerGraph, Naiad).
We have evaluated a range of contemporary data processing systems – Hadoop, Spark, Naiad, PowerGraph, Metis and GraphChi under controlled conditions and found that their performance can vary widely depending on the workflow. Interestingly, no single system consistently outperforms the others, and almost every system performs best under some circumstances.
With Musketeer, we make it easier for users to experiment with different systems by automatically translating their workflows. In fact, Musketeer can even take decision off their shoulders entirely and guess a suitable system automatically. Users simply write their workflow in one of the support front-end languages and a smart scheduler chooses the best back-end execution system, or combination of systems, at execution time and translates the workflow appropriately.
Advantages of using Musketeer
- Dynamic systems binding: Musketeer chooses the right data processing system at runtime, depending on data volume, workflow iterativity and composition, reducing the runtime or resource utilisation.
- Dynamic job boundaries: Musketeer places job boundaries within a workflow at runtime, adding the opportunity to dynamically decompose the workflow differently depending on the data and the availability of different processing systems.
- Flexible adaptation: Musketeer's runtime mapping to data processing systems allows workflows that change over time to adapt dynamically: workflows can be partitioned and mapped differently if they change, or if the properties of data processing systems change (e.g. because of additional optimisations made in new versions of a system).
- Easy job migration: Musketeer makes it easy to port workflows to new systems. Once support for the new system has been added to Musketeer, it can translate workflows onto the new system and schedule them.