Next: Expert and Hardware-level User Up: Kiwi / KiwiC Compiler Previous: Installation and Easy Get Contents Index
Kiwi aims to support a very broad subset of the C# language and so be suitable for a wide variety of High-Performance Computing (HPC) applications. However, the user is expected to write in a parallel/concurrent style using threads to exploit the parallelism available in the FPGA hardware. However, conventional high-level synthesis (HLS) benefits should be realised even for a single-threaded program.
This chapter will explain the synthesisable subset of C# supported by KiwiC, but currently much work is needed in this section of the manual ...
In general, for Kiwi 1, all recursion must be to a compile-time determinable depth. The heap and stack must have the same shape at each point of each iteration of every loop this is not unwound at compile time. In other words, dynamic storage allocation is supported in KiwiC, provided it is called only from constructors or once and for all on the main (lasso stems of) threads before they enter an infinite loop. If called inside a non-unwound loop, the heap must be the same shape at each point on each iteration.
KiwiC implements a form of garbage collection called 'autodispose'.
This can currently (October 2016) be enabled with
-autodispose=enable. It will be turned on by default in the near future when further escape analysis is completed. Currently it disposes of a little too much
and when that memory is reused we have a nasty aliasing problem since that store was still live with other data. This will crop up with linked-list and tree examples
or where the address of a field in a heap object is taken.
When autodispose fails to free something (or is turned off)
you can explicitly free such store with a call to obj.Dispose() or Kiwi.Dispose(Object obj).
WRONG: Dynamic storage regions cannot currently be shared between Kiwi threads. Currently, KiwiC implements different heap spaces for each thread ... really ? If so this needs fixing ... TODO ... maybe they are only different AFTER a fork but resources allocated before Thread.Start are ok.
Floating point is being provided for the standard 32 and 64-bit IEEE precisions, but FPGAs really shine with custom precision floating point so we will add support for that while maintaining bit-accurate compatiblity between the execution environments.
Atomic operations: Kiwi supports the CLR Enter, Exit and Wait calls by mapping them on to the hpr_testandset primitive supported by the rest of the toolchain. Ed: The rest of this paragraph should be in the `internal operation' section. Although RTL target languages, such as Verilog, are highly-concurrent, they do not have native support for mutexes. The bevelab recipe stage correctly supports testandset calls implemented by its own threads, but KiwiC does not use these threads: instead it makes a different HPR virtual machine for each thread and these invoke bevelab once each instead of once and for all with bevelab threads within that invokation. Hence the the testandset primitives dissappear inside bevelab. ... TODO explain further.
Kiwi supports custom integer widths for hardware applications alongside the standard integer widths of dotnet 8, 16, 32 and 64.
Char is a tagged form of the 16-bit signed integer form.
Single and double-precision floating point are supported.
Enumerations are supported with custom code points. MSDN says the approved underyling types for an enum are byte, sbyte, short, ushort, int, uint, long, or ulong, but Kiwi uses a suitable custom width of any number of bits.
One-dimension arrays are supported natively by Kiwi since they are part of the dot net virtual machine. The Length attribute does not always work at the moment since its implementation is fully at compile time and it fails where this varies at a given call site at run time. This can be fixed by the user using a wrapper class as per the higher-dimensional arrays.
Higher-dimensional arrays, including jagged arrays, are implemented in the Kiwic.cs file as wrappers around the native one-dimensional array. This is the same as for other dot net uses of higher-dimensional arrays. In theory, the standard dot net version of these wrappers should work well with Kiwi but we have not tried it. The Kiwi-supplied wrappers have various and properties and methods missing that should be available. Feel free to add them or paste the code from the standard implementations.
Classes and structs are supported. These are different from each other in C# (unlike C++). Although having much in common, C# treats structs and classess differently. C# passes structs by value to a method, meaning local modifications to contents do not commit to original instance. C# assigns structs by value, so all fields in the destination are updated by the assigment, rather than the handle just being redirected. Support for C# structs is being added.
Static and dynamic instances of classes and structs work. There is also some support for static arrays, as used in the C++ gcc4cil front end, but arrays are normally dynamically-allocated in C#. Certain restrictions regarding dynamic storage allocation and automatic garbage collection apply (§III).
Kiwi supports static, instance, local and formal parameter variables.
Variables may be classes or built-in primitive types and arrays of such variables. An array may contain a class and a class may contain an array, to any nesting depth. Multi-dimensional arrays (as opposed to jagged arrays) are supported with a little syntactic sugar in the C# compiler but mostly via library class code provided in Kiwic.dll.
Signed and unsigned integer and floating point primitive variables are fully supported.
Verilog and SystemC have 8-bit chars but C# and dotnet have 16-bit chars. KiwiC maps all 16-bit chars to the closest 8-bit char. UTF-8 escapes could easily be supported in this process but are missing at the moment.
Strings are supported a little, but there is currently no run-time concatenation or creation of new strings, so all such string creation operations must be elaborated at KiwiC compile time and hence be applied to constant strings.
All standard arithmetic and logical operators are supported. Some operators, especially floating-point converts and floating-point arithmetic result in components being instantiated from the cvgates.v library. Integer mod, divide and larger multiplies also result in ALU instantiation, unless arguments are constant identity values or powers of two that are easily converted to shifts. Divide and multiply by a constant may result in adders being generated.
Classes can be statically and dynamically allocated. Constructor code is executed.
Static classes have their constructor code called at compile time (although it is perhaps possible for the lasoo stem to end partly through the last one one of them.) The same goes for dynamic classes that are converted to static within the lasoo stem.
Class and array instance handles can be manipulated at run time. KiwiC (repack stage) will allocate a small integer for each one in each equivalence group where handles are interchanged or shared. KiwiC checks whether the null value requires a code point in each group. Run-time null dereference errors will be reported in the abend code register at some point soon.
Many class and array handles are never changed (the group has just one member) and hence are merely an artefact of the C# language. Such handles are optimised away inside KiwiC and have no run-time overhead. Class and array instance handles can be manipulated at run time. KiwiC (repack stage) will allocate a small integer for each one in each equivalence class where handles are interchanged. KiwiC checks whether the null value requires a code point. Run-time null de-reference errors will be reported in the abend code register at some point soon.
Kiwi supports a number of forms of I/O:
To achieve high performance from any computer system the programmer must think about their data structures and have a basic knowledge of cache and DRAM behaviour. Otherwise they will hit memory bandwidth limitations with any algorithm that is not truly CPU bound.
As in most programming languages, C# variables and structures are static or dynamic. Dynamic variables are allocated on the heap or stack. All are converted to static form during compilation using the version 1 Kiwi compiler. Support for truly dynamic variables will perhaps be added in a future release.
Kiwi does not (currently) support taking the address of local variables or static variables in fields (except when pass by reference is being compiled). All pointers and object handles need to refer to heap-allocated items.
It is helpful to define the following two terms for pointer variables. Pointers generally point to dynamic data but their pattern of use falls into two classes. We will call a static pointer one whose value is initially set but which is then not changed. A dynamic pointer is manipulated at run time. Some dynamic pointers range over the value null. (As with all C# variables, such pointers can be declared as static or instance in C# program files -- this is orthogonal to the current discussion.)
Every C# array and object is associated with at least one pointer because all arrays and objects are created using a call to 'new'. Also, some valuetypes become associated with a pointer, either by being passed-by-reference or by application of the ampersand operator in unsafe code. The KiwiC compiler will `subsume' nearly all static pointers in its front end constant propagation and any remaining static pointers will be trimmed by later stages in the KiwiC compiler or in the vendor-specific FPGA/ASIC tools applied to the output RTL.
KiwiC maps data structures to hardware resources in two stages. In the first stage (known as repack §29), every C# form (that did not disappear entirely in the front end) is converted to either scalars of some bit width or 1-D arrays (also known as vectors) of such scalars. In the second stage (known as restructure §30), mapping to physical resource decisions are made as to which vectors and scalars to place in what type of component (flip-flops, unregistered SRAM, registered SRAM, DP SRAM or off-chip in DRAM) and which structural instance thereof to use. The first stage behaviour is influenced mainly by C# programming style. Second stage behaviour is controlled by heuristic rules parametrised by command-line flags and recipe file values.
Two-dimensional arrays are a good example to start with. Although there is syntactic sugar in C# for 2-D arrays, with current C# compilers this is just replaced with operations supplied by a library dll. The dotnet runtime and KiwiC support just 1-D arrays called vectors. There are two possible implementations of a 2-D array library: jagged and packed. The packed form subscript is computed using a multiply of the first co-ordinate with the arity of the second co-ordinate and then adding on the second co-ordinate. The jagged form uses a vector of static pointers to vectors that contain the data; the first co-ordinate is the subscript to the pointer vector and the second co-ordinate is the subscript to the selected vector. We use the term jagged to encompass their smooth form where all data vectors are the same length.
KiwiC inlines the subscript computation for a packed array as though the programmer had inlined such an expression in his C# code. Additionally, there is only one vector created. Therefore packed 2-D arrays first become 1-D vectors. However, such vectors are then subject to unpacking in first stage operation. For instance, if all subscripts are constant values, the array is replaced with a set of scalars. Of if the subscripts fall into clearly disjoint regions, the vector is split into multiple, separately-addressed regions. Or if all the subscripts have a common factor or common offset then these are divided and subtracted off respectively. This unpacking into multiple vectors removes structural hazards that would prevent parallelism.
For a jagged array, initially a number of separate vectors are created and a potentially large number of multiplexing expressions (that appear as the ?: construct in Verilog RTL) are created to direct reads to the correct vector. For writes, an equivalent demultiplexor is created to select the correct vector for writing. (The pointer vector is normally static and becomes subsumed, but we will later discuss what happens if the C# code writes to it, making it dynamic.)
Implementation note: if a jagged array is created by allocating a large 1-D array and storing references to offsets in that vector in the pointer array, it is possible to generate a structure that is identical to the packed array. KiwiC happens to detect this pattern and the behaviour would be as per the packed array: however this style of programming is not allowed in safe C#, but could be encountered in unsafe code or other dotnet input form, say, C++.
If we create an array of objects do we expect the fields of the objects to be placed in vectors? Yes, certainly if the object pointers are subsumed.
If we take the parfir example, there's one initialise place where empty flags are written from a non-unwound loop and hence with dynamic subscript, but elsewhere they are updated only with constant subscripts and so should be simple scalar flags.
Kiwi on Loop Unwinding: Loop-carried dependencies in data or control form limit the amount of parallelism that can be achieved with unwinding.
The hard cbg algorithm unwinds all loops without event control. The soft algorithm allocates cycles based on greedy or searching strategies based on complexity and structural hazards. Consider 1: Hoisting of exit condition computation, or hoisting of data dependency computation: this should preferably be applied? So the post-dependent tail of each loop can be forked off
For statically-allocated object instances, KiwiC packs them into flip-flops, B-RAM or DRAM according to thresholds configured in the recipe or command line. This includes objects and structs allocated on the C# heap before the end of static elaboration.
For dynamically-allocated instances, KiwiC cannot easily tell how much memory may be needed and so defaults to DRAM channel 0 if present. But we can switch manually between B-RAM and DRAM for dynamic storage allocation using C# attributes.
We make the following interesting observation: Once data structures are placed in DRAM there is no real need to have their number statically determined at compile time: instead they can be truely dynamically allocated at run time (DJ Greaves 2015). Indeed, if an application becomes overly dependant on DRAM data then the FPGA advantage will disappear and a Von Neumann (e.g. x86) implemenation may likely have better performance. But, there remains some good FPGA mid ground where a lot of dynamic store is needed but where the access bandwidth required is not excessive.
The Kiwi.MemSpace("spacename") attribute can be added to a struct or class definition to take manual control of the DRAM bank its instances are placed in... Spacename is either a user name or a logical name for a memory bank. ... examples needed ...
Kiwi.HeapManager
Physical memories used for dynamic storage require a freespace manager. We can allocate a HeapManager for each physical memory and the user can direct requests to an appropriate instance. Typically there could be one for each separate DRAM bank and one for each separate on-chip B-RAM.
Also, arrays with dynamic sizes ...
handleArith pointer arithmetic
Kiwi.ObjectHandler<T>
The object handler provides backdoors to certain unsafe code for pointer arithmetic that are banned even in unsafe C# code. Implementation in CIL assembler would be possible but having hardcoded support in the KiwiC compiler accessed via this object manager is easier.
With Kiwi 1, the stack and heap must have same shape at each run-time iteration of non-unwound loops. In other words, every allocation made in the outer loop of the compiled program must be matched with an equivalent dispose or garbage generation event in the same loop.
Where a heap object is allocated inside a loop that is not compile-time, it will potentially consume fresh memory on each iteration. There are two basic senarios associated with such a condition: either the fresh memory is useful, such as when adding items to a linked-list datastructure, or else it is not needed because the previous allocation is no longer live and the same heap space could be simply reused. This second case is fully served by converting to static allocation at compile time.
KiwiC V2 is implementing a more easy to use, run-time storage allocator, but without garbage collection.
KiwiC V1 does not support genuine dynamic storage allocation inside an execution-time loop. Bit it provides two mechanisms to support dynamic to static reduction where dynamic store is not really needed. The first uses an explicit dispose and the second uses an implicit dispose. Either way, when the loop iterates, the active heap has shrunk and KiwiC makes sure to reuse the previously allocated heap record at the allocation site (call to C# new).
See the linked list example ... http://www.cl.cam.ac.uk/research/srg/han/hprls/orangepath/kiwic-demos/linkedlists.html
KiwiC V1 arrays - Array sizes must all be statically determinable (i.e. at compile time).
System.BitConverter provides a typical use case that involves a lot of temporary byte arrays. The F# compiler also uses a lot of temporary structures and the KiwiC has a chance of compiling F# bytecode by exploiting the implicit disposal approach.
Arrays in .NETdo not have a Dispose() method. Instead an
array can be disposed of with Kiwi.Dispose<T>(T [] array).
This is a nop when running on mono/dotnet.
System.BitConverter returns char arrays when destructing native types and the arrays returned by BitConverter should be explicitly disposed of inside a non-unwound loop if KiwiC is failing to spot an implicit manifest garbage creating event, as reported with the an error like:
System.BitConverter returns char arrays when destructing native types. The arrays returned by BitConverter should be explicitly disposed of inside a non-unwound loop if KiwiC is failing to spot an implicit manifest garbage removal opportunity, as reported with the an error like
KiwiC +++ Error exit: BitConverterTest.exe: constant_fold_meets entry_point=5:: Bad form heap pointer for obj_alloc of type CT_arr(CTL_net(false, 32, Signed, native), 8) post end of elaboration point (or have already allocated a runtime variable sized object ?). Unless you are geninuely making a dynamic linked list or tree, this can generally be fixed using a manual call to Kiwi.Dispose() in your source code at the point where your allocation could be safely garbage collected.
Unless you are geninuely making a dynamic linked list or tree, the failed
implicit garbage collector can generally be worked around
using a manual call to Kiwi.Dispose() in your
source code at the point where your allocation could be safely
garbage collected.
For making trees and lists, see the linked list example ... http://www.cl.cam.ac.uk/research/srg/han/hprls/orangepath/kiwic-demos/linkedlists.html
... field-arrays and spatial locality
We need sometimes to achieve different behaviour, for debugging and scaling reasons, in the three execution environments.
Kiwi.inHardware() and find that it returns false. The Kiwi.dll file returns false when run as a normal dotnet program, but KiwiC has a hardcoded bypass that makes it hold (return true).
Kiwi.InputBitPort("FPGA")] static bool FPGA; returns false. You should tie this net low in your simulator top-level instantiation.
Call the function Kiwi.inHardware() for this purpose.
Since this is a compile-time constant, it is useful for removing development and debugging code from the final
implementation. KiwiC will ignore code that is inside if (false) { } constructs so write
if (!Kiwi.inHardware()) { ... test/debug code ... }.
[KiwiSystem.Kiwi.HprPrimitiveFunction()]
public static bool inHardware()
{
return false; // This is the returned value when running on the workstation.
// An alternative overriding implementation is hardcoded inside KiwiC and will
//return 'true' for FPGA and RTL simulation.
}
Clone of arrays and objects ....
not there yet ... The varargs support is also pretty trivial to implement inside KiwiC under the current technique of fully inlining method calls during KiwiC compilation - it's just a matter of a few lines of simple interpretative code in the elaborator...
Dynamic method dispatch is where which function body that gets called from a callsite is potentially data-dependent. Computed function calls occur with action and function delegates and dynamic object polymorphism.
In C++ there are restrictions that higher-order programming is only possible within a class hierarchy. This arises from the C compatibility issues where the higher-order function passing does not have to manage an object pointer. These issues are neatly wrapped up in C# using delegates. An action delegate has void return type whereas a function delegate returns a value.
Kiwi supports the function and action delegates of C#.
KiwiC partitions dynamically-callable method bodies into equivalence classes and gives each body within a class an integer. These classes typically contain only a very few members each. It then uses constant folding on the entire system control-flow graph as a general optimisation. This may often turn a dynamic dispatch into a static dispatch, hence these integers will not appear in the output hardware unless truly dynamic dispatch is being used, such as in
Action<int, string> boz_green = delegate(int var1, string var2)
{ Console.WriteLine(" {1} {0} boz green", var1, var2);
};
Action<int, string> boz_red = delegate(int var1, string var2)
{ Console.WriteLine(" {1} {0} boz red", var1, var2);
};
for(int pp=0; pp<3; pp++)
{ Kiwi.Pause(); // Pause makes this loop unwind at run time.
boz_red(pp+100, "site1");
boz_green(pp+200, "site2");
var x = boz_red; boz_red = boz_green; boz_green = x; //swap
}
C# 3.0 onwards supports proper closures. These are implemented inside the C# compiler and compile fine under Kiwi provided the static allocation restrictions are obeyed.
Test55 of the regression suite contains the following demo.
public static Func<int,int> GetAFunc()
{
var myVar = 1;
Func<int, int> inc = delegate(int var1)
{ myVar = myVar + 1;
return var1 + myVar;
};
return inc;
}
[Kiwi.HardwareEntryPoint()] static void Main()
{ var inc = GetAFunc();
Console.WriteLine(inc(5));
Console.WriteLine(inc(6));
}
This compiles and works fine. But, there is a Kiwi 1 resriction that the GetAFunc call must be before the end of static elaboration since this creates the closure that is allocated on the heap.
If no closure is needed, Action and Function delegates suffer from no static allocation restriction.
Kiwi implements a basic version of the ToString method. It will give output that is rather dependent on which version of the compiler is being used, but it is better than nothing. Enumerations print as integers.
IntPtr types.
Clearly, the addresses used on the FPGA have little relationship when run on the mono VM, but it is possible to display class pointer value on the hardware platform. One method is to use the default ToString method on an object handle. This will generate a Kiwi-specific output.
For example
Console.WriteLine(" Ntest14w line0 : pointer={0}", ha.ToString());
Console.WriteLine(" Ntest14w line1 : left={0}", ha.left);
Might give:
Ntest14w line0 : pointer=Var(test14w/T401/Main/T401/Main/V_0%$star1$/test14w/
dc_cls%30008%4, &(CTL_record(test14w/dc_cls,...)), ..., )
Ntest14w line1 : left=32
Ah - this has printed the variable not its value!
The Kiwi.dll library declares a static variable called Kiwi.tnow. During compilation reads of this are replaced with references to the appropriate runtime mechanism for access to the current simulation time. For instance, the following line
Console.WriteLine("Start compute CRC of result at {0}\n", Kiwi.tnow);
becomes
$display("Start compute CRC of result at %t\n", $time);
when output as Verilog RTL.
The substrate has a tick counter that is instantiated when tnow is used for FPGA execution and so the RTL_SIM
code is a now a shim and not a direct call to the non-synthesisable $time infact... TODO fix.
The following paragraphs are an introduction that should contain links the relevant manual parts.
The user requires various indications of whether an FPGA card is actively running an application. Some applications have a natural finish or exception halt state. Others run eternally using NaN-like schemes to convey errors.
Nearly all FPGA blade have LED outputs controlled by GPIO pins that are useful for basic status monitoring. FPGA substrates can `virtualise' these LEDs so that host management software can see them. Some FPGAs have LCD or VGA framestore outputs that are also relatively easy to use for monitoring and results.
The Kiwi user may freely connect up LEDs and other I/O devices as part of their application-specific design, but the Kiwi system defines some standard techniques should preferably be used. These are conveyed through the substrate gateway for FP execution and are also implemented in the standard WD and RTL_SIM templates.
The Kiwi system also defines a `WayPoint' progress indication framework that is used both for progress indication (debugging) and performance monitoring and prediction (§10.2). This is augmented with the abend syndrome register (§10.4).
... The sequencer index and waypoint for each thread can be remotely monitored via the substrate gateway. This provides ... abend syndrome register ... logs thread id, waypoint, pc value and abend reason.
An HLS run can generate a client or a server. A server is an accelerator or AFU that will be used by a client: it does nothing by itself. A client, on the other hand, starts work by itself, either straightaway or when given a start command. A client can be software running on a host that invokes accelerators via the Kiwi Substrate, or it may be an HLS design that starts from a Kiwi.HardwareEntryPoint attribute.
A client that performs DMA into a host must be told the DMA address before it starts.
The ksubsRunStop two-bit field is used to control hardware clients.
ksubsRunStop settings
0 0 Assert synchronous reset
0 1 Normal running
1 0 Pause (deassert clock enable)
1 1 (reserved for single step)
[Kiwi.InputWordPort(``ksubsRunStop'')] static int ksubsRunStop could be polled from C# as a potentially
sensible design point. But we do not use that. Instead, where the client is instantiated by the substrate, its
reset and clock enable inputs are connected to a hardware circuit that interprets the run stop
field and which can allow just one single clock cycle of progress in some variants.
The Pause setting requires the client to have a clock enable input. The command line flag that ensures
clock enables are present is -kiwife-directorate-style=advanced .
The clock enable is called hpr_ext_run_enable.
An AbendSyndrome register is also created in that mode.
This external clock enable is ANDed inside the KiwiC-generated code with a local clock enable so
that the client system stops (the clock enable is de-asserted) when abending or exiting.
The HPR L/S framework allows an RTL module to select one of three forms of standarised error output:
The Kiwi substrate gateway will log the thread identifier, waypoint and sequencer index for threads that finish or abort. The user can reverse-engineer these via the KiwiC report file. An XML variant of that file for import into IDE needs to be provided in the future.
Sources of runtime error: It is possible to get a run-time null pointer exception.
The CSharp language supports arithmetic both with overflow ignored (as in C/C++) and checked. It is possible to get a run-time checked overflow exception. (But not yet supported in KwiC as of January 2017.)
It is possible to get a run-time divide-by-zero exception.
It is possible to get a run-time array bounds exception.
It is possible to get a run-time sub-component exception.
It is possible to get a run-time unhandled C# exception exception.
(Floating point exceptions are normally handled with via NaN propagation.)
For RTL_SIM execution of the KiwiC-generated RTL, it is sometimes convenient to have the simulator automatically exit when the program has completed.
NB: We replaced -kiwic-finish with -kiwife-directorate-endmode
When the main thread of Kiwi program exits (return from Main), the generated code may include a Verilog $finish statement if the (OLD FLAG-TODO EDIT THIS) flag "-kiwic-finish=enable" is supplied on the command line or in the recipe file. The equivalent is generated for C++ output. Otherwise a new implicit sequencer state is created with no successors and the thread sits in that state forever. Hanging forever is the default behaviour for forked threads.
The argument to the $finish statement, if present, is also written to the abend syndrome register when present (see directorate styles). RTL designs also stop (clock-enable forced deasserted) when a syndrome is stored.
For use with a standard execution substrate, having a $finish statement in the generated design makes no sense,
Environment.Exit(int syndrome) can also be invoked within C# to cause the same effect as main thread return. The integer value is stored in the abend syndrome register and the RTL hardware design halts until next reset.
(Pipelined accelerators cannot exit since they have no sequencer (§15 and are permanently ready to compute. )
C# try-except blocks are supported as is exception handling. But no exceptions can currently be caught and all lead to either a compile-time or run-time abend.
In other words, the contents of a C# catch block are ignored in the current KiwiC compiler.
The contents of a C# finally block are executed under Kiwi as normal.
The following fragment shows how to throw a runtime exception that will cause execution to stop with an abend syndrome readable by the director shim.
Please follow the coding conventions in table XXX and note that the specific error code 128 is not an error and will not stop execution if thrown: it is the default aok code.
class myDemoExn: System.Exception
{
// Note KiwiC latches onto an integer field name in uncaught exceptions containing the string 'code'
int ecode = 129;
public int error_code //
{
set { ecode = value; }
}
}
class UncaughtExceptionTest
{
// Steer away from Kiwi-1 dynamic storage complexity by
// making the thrown exception a static.
static myDemoExn my_faulter = new myDemoExn();
public void runner(int roger)
{ for (int pp=0; pp<10;pp++)
{
Kiwi.Pause();
Console.WriteLine(" runner {0}", pp);
my_faulter.error_code = 101 + pp;
if (pp == 5) throw my_faulter;
}
}
}
System.Diagnostics.Debug.Assert(bool cond) and friends ...
We can raise a run-time assertion problem that is logged in the abend syndrome register with code 0x20.
There is a compile-time variant called - not reached - or something ...
Kiwi supports several major HLS modes, but the default, sequencer major HLS mode, generates a sequencer for each thread. When creating a sequencer, the number of states can be fully automatic, completely manual, or somewhere in between, according to the pause mode setting.
The mapping of logic operations to clock cycles is one of the main tasks automated by high-level synthesis tools, but sometimes manual control is also needed. Control can be needed for compatibility with existing net-level protocols or as a means to move the design along the latency/area Pareto frontier.
KiwiC supports several approaches according to the pause mode selected. Pause modes are listed Table 1. The number of ALUs and RAM ports available also makes a big difference owing to structural hazards. Fewer resources means more clock cycles needed.
The pause mode can, most simply, be set once and for all on the command line with, for examples
-bevelab-bevelab-default-pause-mode=soft.
When in soft mode, the
bevelab-soft-pause-threshold parameter is one of the main guiding metrics.
But it has no effect on regions of the program compiled in hard-pause or other non-soft modes.
Typical values for the soft pause threshold are intended to be in the range 0 to 100, with values of 100 or above leading to potentially very large, massively-parallel designs, and with values around 15 or lower giving a design similar to the `maximal' pause mode.
The Kiwi.cs file defines an enumeration for locally changing the pause mode for the next part of a thread's trajectory.
enum PauseControl
{ autoPauseEnable, hardPauseEnable, softPauseEnable,
maximalPauseEnable, blockbPauseEnable };
The idea is that you can change it locally within various parts of a thread's control flow graph by calling
Kiwi.PauseControlSet(mode) where the mode is a member of the PauseControl enumeration. Also, this can be
passed as an argument to a Kiwi.Pause call to set the mode for just that pause. However, dynamic pause mode changing may not work at the moment ... owing to minor bugs.
For example, you can invoke Kiwi.PauseControlSet(Kiwi.PauseControl.softPauseEnable).
|
Nearly all net-level hardware protocols are intolerant to clock dilation. In other words, their semantics are defined in terms of the number of clock cycles for which a condition holds. A thread being compiled by KiwiC to a sequencer defaults to bblock or soft pause control, meaning that KiwiC is free to stall the progress of a thread at any point, such as when it needs to use extra clock cycles to overcome structural hazards. These two approaches are incompatible. Therefore, for a region of code where clock cycle allocation is important, KiwiC must be instructed to use hard pause control.
The recipe file kiwic00.rcp sets the following as the default pause mode now
<option> bevelab-bevelab-default-pause-mode bblock </option>
This is not suitable for net-level interfaces but does lead to quick compile of scientific code which is what we are targeting at the moment.
For compiling net-level input and output, give KiwiC -bevelab-bevelab-default-pause-mode=hard as a command line option to override the recipe.
Maximal and blockb are considered just `debug' modes where pauses are inserted at every semicolon and every basic block boundary respectively.
For a thread in hard-pause mode that executes loops with no Pause() calls in them will, KiwiC will attempt to unwind all of the work of that loop and perform it in a single run-time clock cycle. (There are some exceptions to this, such as when there are undecidable name aliases in array operations or structural hazards on RAMs but these are flagged as warnings at compile time and run time hardware monitors can also be generated that flag the error).
TODO: describe the way KiwiC resolves structural hazards or variable-latency if the user has specified hard pause mode. Currently, KiwiC essentially tacitly takes and consumes any further clock cycles it needs to do the work.

The example main_unwound_leader will unwind the first loop at compile time and execute the first 16 print statements in the first clock tick and q will be loaded with 116 on the first clock tick.

The example main_complex_state_mc has a loop with run-time iteration count that is not unwound because it contains a Pause call. This is accepted by KiwiC. However, it could not be compiled without the Pause statement in the inner loop because this loop body is not idempotent. In soft-pause mode the pause call would be automatically added by KiwiC if missing.
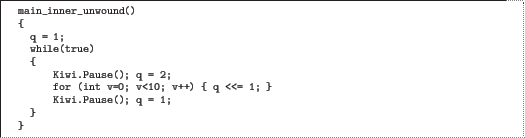
In main_inner_unwound the inner loop will be unwound at compile time because it has constant bounds and no Pause call in its body. (This unwind will be performed in the bevelab recipe stage, not KiwiC front end.)
A top-level entry point with formal parameters, such as
![\begin{quoze}[Kiwi.HardwareEntryPoint()]
main_withparam(int x)
{
...
}
\end{quoze}](img8.png)
is currently not allowed in normal sequencer mode, although in future it would be reasonable for these to be treated as additional inputs. This will be relaxed soon.
Top-level arguments are allowed in RPC (§7.1) and Accelerator major HLS modes (§15).
In Kiwi, roots may instead or also be specified using dot net attributes similar to Kiwi.Hardware.
When you want only a single thread to be compiled to hardware, either add a Kiwi.Hardware attribute or use a root command line flag. if you have both the result is that two threads are started doing the same operations in parallel.
Flag -root rootname specifies the root facet for the current run. A number of items can be listed, separated by semicolons. The ones before the last one are scanned for static and initialisation code whereas the last one is treated as an entry point.
The -root command line flag is an alternative to the HardwareEntryPoint marker. Supplying this information on the command line is compatible with multiple compilation appoaches where a given source file needs to be processed in different ways on different compilation runs.
The KiwiC front end unwinds certain loops such as those that peform storage allocation and fork threads. The main behavioural elaborate stage of the KiwiC flow also unwinds other loops. Because of the behaviour of the former, the latter operates on a finite-state system and it makes its decisions based on space and performance requirements typical in high-level synthesis flows. Therefore, the loop unwinding performed in the KiwiC front end can be restricted just to loops that perform structural elaboration. These are known as generate loops in Verilog and VHDL. It is a typical Kiwi programming style to spawn threads and allocate arrays and other objects in such loops. Such elaboration that allocates new heap items, in Kiwi 1, must be done in the KiwiC front end since the rest of the HPR recipe deals only with statically-allocated variables.
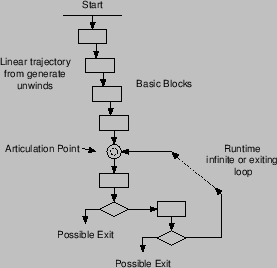
Since threads both describe compile-time and run-time behaviour a means is needed to distinguish the two forms of loop. The approach adopted is that every thread in the source code is treated as generally having a lasso shape, consisting of code that is executed exactly once before entering any non-unwound, potentially-infinite loop.
The front-end algorithm used selects an articulation point in the control graph of a thread where all loops before this point have been unwound and all code reachable after that point has its control graph preserved in the program output to the next stage. Figure 3 illustrates the general pattern. The articulation point is called the end of static elaboration point. The point selected is the first branch target that is the subject of a conditional branch during an interpreted run of the thread or the entry point to the last basic block encountered that does not contain a Kiwi.Pause() call.
The branch will be conditional either because it depends on some
run-time input data or because it is after at least one Kiwi.Pause()
call. The semantics of Kiwi.Pause() imply that all code executed after
the call are in a new run-time clock cycle. Apparently-conditional
branches may be unconditional because of constant folding/propagation during
the interpreted run. This is the basis of generate-style loop
unwinding in the lasso stem.
Some programming styles require the heap changes shape at run time. A simple example occurs when an array or other object is allocated after the first call to Kiwi.Pause. We have found that programmers quite often write in this style, perhaps not allways intenionally, so it is useful if KiwiC supports it.
![\begin{quoze}
main_runtime_malloc()
{
...
Kiwi.Pause();
int [] a = new Int[10];
for (int i=0; i<10; i++) a[i] = i;
while (true) { ... }
}
\end{quoze}](img10.png)
Provided the heap allocator internal state is modelled in the same way as other variables, no further special attention is required. In this fragment the heap values are compile-time constants.
![\begin{quoze}
main_runtime_dyn_malloc()
{
...
Kiwi.Pause();
if (e)
{ int ...
...10];
for (int i=0; i<10; i++) a[i] = i;
}
while (true) { ... }
}
\end{quoze}](img11.png)
If the value of `e' in runtime_dyn_malloc is not a compile-time constant, KiwiC cannot compile this since there would be two possible shapes for the heap on the exit for the if statement. A solution is to call a.Dispose() before exit, but KiwiC currently does not support Dispose calls.
There's also the matter of saved thread forks ....
Here the outer loop is non-unwound loop yet has a compile-time constant value on each read if the inner loop is unwound
![\begin{quoze}
while(true) // not unwound
{
for (int i=0;i<3;i++) foo[i].bar(f);
...
}
\end{quoze}](img12.png)
We have started documenting our library coverage in this section.
Currently (August 2016), none of the standard collection types, such as Dictionary, are provided in the distro. They are now arriving ... Summer 2017.
Implementations of double-precision square-root, log, exp, sine, cos and tan are all being added Summer 2017 now that incremental compilation is working. These components are in the ip0 library in Verilog RTL form with IP-XACT wrappers. You may substitute your own if you wish. A single-precision set might be useful. Dotnet perhaps does not have them in single-precision form?
// Execute N copies of f in parallel. Parallel.For(0, N, i => f(i));
See ParFor1 example
The CSharp compiler maps Parallel.For to a call of System.Threading.Tasks.ParallelLoopResult.
An implementation of this in Kiwic.cs maps it via CSharp backdoors to the Xfork Xjoin forms supported by bevelab as part of the synthesisable HPR imperative language subset. They are turned into XRTL by bevelab along with everything else. Note diosim cannot currently (3Q17) support Fork and Join so a recipe that bypases bevelab on the way to diosim will fail.
For many standard dot net libraries, the normal (mono or MS) release of them is not suitable for use with KiwiC. So KiwiC needs to substitute alternate versions. There are two main forms of alternative: they may be implemented in C# (or CIL assembler) themselves, or may be RTL modules from an IP library. So, on a case-by-case basis, the decision for either a high-level (C#) swap or a low-level (RTL) swap needs to be made.
There are three ways a stateless FU (IP-block) such as Math.Sqrt can be deployed:
1. Inlined. The C# src code for the sqrt is inlined by KiwiC and the ALUs it uses are borrowed from or shared with other parts of the application.
2. Fenced. The square-root FU is compiled to an RTL module containing its own private resources, the FU is instantiated one or more times and these FU instances are shared as per other stateless FUs and and ALUs.
3. Swapped. Again an RTL module is instantiated and ringfenced, but a back-end substitution is made where the body of the C# implementation is ignored and a foreign RTL implementation of the SQRT FU is deployed and sharable.
System.Random is automatically mapped in the library-substitutions to KiwiSystem.Random. Since this is a different generator the sequence of numbers created is different. So you will get different sequences of random numbers under WD from RTL_SIM and FP.
To get the same behaviour for all of WD, RTL_SIM and FP, please directly use KiwiSystem.Random instead of System.Random.
KiwiSystem.Random dg = new KiwiSystem.Random();
The redirect can be disabled using -kiwic-library-redirects=disable.
The search path for redirected libraries is based on the HPRLS environment variable, but if this is not set, it relative paths names with respect to the lib folder where the kiwic.exe binary is executing from.
Describe kdistro/support ... which was generated from kiwipro/kiwi/userlib and which is dynamically searched for autoloaded libraries whose names have often redirected names ...
The Write and WriteLine methods are the standard means
for printing to the console in C# and Kiwi. They can
also print to open file descriptors. They embody
printf like functionality using numbered parameters in
braces.
Overloads are provided for used with up to four arguments. Beyond this, the C# compiler allocates a heap array, fills this in and passes it to WriteLine, after which it requires garbage collection. This should provide no problem for Kiwi's algorithm that converts such dynamic use to static use but if there is a problem then please split a large WriteLine into several smaller ones with fewer than five arguments (beyond the format string).
Argument formats supported are
{n} -- display arg {n:x} -- display arg
Kiwi will convert console writes to Verilog's
$display and
$write
PLI calls with appropriate munging of the format strings. These will come out
during RTL simulation of the generated design. They can also
be rendered on the substrate console during FPGA execution.
On important choice is whether this console output is preserved for the FPGA implementation. By default it is, with the argument strings compiled to hardware and copied character by character over the console port.
Sometimes two other behaviours are selectively wanted:
To achieve item 1, do not call Console.Write or Console.WriteLine. Instead call Kiwi.Write or Kiwi.WriteLine.
To achieve item 2, alter the recipe file or add the following command line argument to KiwiC
-kiwic-fpgaconsole-default=disable
... text missing ...
int tid = Thread.CurrentThread.ManagedThreadId;
Console.WriteLine("Receiver process started. Tid={0}", tid);
// OLD Console.WriteLine("Receiver process started. Tid={0}", System.Threading.ManagedThreadId);
One novel feature of Kiwi that sets it apart from other HLS systems is its support for concurrency.
Threads can be spawned in the static lasso stem but Kiwi does not support thread creation at runtime.
Kiwi supports Thread.Create() and Thread.Start().
To run a method of the current object on its own thread use code like this:
public static void IProc()
{
while (true) { ... }
}
...
Thread IProcThread = new Thread(new ThreadStart(IProc));
IProcThread.Start();
Or use delegates to pass arguments to a spawned thread running a method of perhaps another object:
Thread filterChannel = new Thread(delegate() { ZProc(1, 2, 3); });
filterChannel.Start();
Exiting threads can be joined with code like this:
... missing ... Thread.Join(); // not tested currently.
The lock statement of C# is supported (but as per C#, not in static methods). This is a convenient paradigm for where the flow control of the critical region has pre and post dominating points. It wraps code in Monitor.Enter(this) and Monitor.Exit(this).
For more-complex control flow we must use the lower-level primitives, as per posix. These are Monitor.Wait() , Monitor.Enter() , Monitor.Exit() , Monitor.Pulse() and Monitor.PulseAll() .
Mutual exclusion is provided with the lock primitive of C#. Its argument must be the object handle of any instance (not a static class).
The Monitor.Wait and Monitor.PulseAll are supported for interprocess events.
lock (this)
{
while (!emptyflag) { /* Kiwi.NoUnroll(); */ Monitor.Wait(this); }
datum = v;
emptyflag = false;
Monitor.PulseAll(this);
}
System.Threading.Interlocked.Exchange and System.Threading.Interlocked.CompareExchange ...
The atomic add operating System.Threading.Interlocked.Add, is ...
The atomic increment and decrement operators System.Threading.Interlocked.Increment and System.Threading.Interlocked.Decrement are implemented on top of the add primitive.
The NoUnroll directive to KiwiC can decrease compilation time by avoiding unrolling exploration.
KiwiC does not currently support fine-grained store ordering. Where a number of writes are generated in one major cycle (delimited by hard or soft pauses) the writes within that major cycle are freely reordered by the restructure recipe stage to maximimse memory port throughput. However, KiwiC already maintains ordering in PLI and other system calls, so extending this preservation to remotely-visible writes can easily be added in the near future.
Write buffers and copy-back caches may also be instantiated outside the KiwiC-generated code in uncore structures that are part of the substrate for a given FPGA blade. KiwiC has no control over these.
We are writing a paper that explores this space.
C# provides the Thread.MemoryBarrier() call to control memory read and write re-ordering between threads... but in the meantime
you have to use Kiwi.Pause() to ensure write ordering.
Variables that are shared between threads may need to be marked as volatile. The normal semantics are that memory fences are inferred from lock block boundaries and other concurrency primitives such as PulseAll. However, if shared variables are used without such fences they should be declared as volatile. Otherwise a process spinning on a change written by another thread may never see it change.
The C# language does not support volatile declarations of some types. You may get an error such as
//tinytest0.cs(16,26): error CS0677: `tinytest0.shared': A volatile field
cannot be of the type `ulong'
To overcome this, you can try to use the Kiwi-provided custom volatile attribute instead for now. For instance:
[Kiwi.Volatile()] static ulong shared_var;
This technique will not stop the C# compiler from optimising away a spin on a shared variable, but the C# compiler may not do a lot of optimisation, based on the idea that backend (jitting) runtimes will implement all required optimisations. Ideally KiwiC works out which variables need to be volatile since all threads sharing a variable are compiled to FPGA at once.
The KiwiC compiler understands various .NETassembly language custom attributes that the user has added to the source code. In this section we present the attributes available. These control thinks such as I/O net widths and assertions and to mark up I/O nets and embed assertions that control unwinding.
C# definitions of the attributes can be taken from the file
support/Kiwi.cs in the distribution.
The Kiwi attributes can be used by referencing their dll during the C# compiler.
gmcs /target:library mytest.dll /r:Kiwi.dll
Many attributes are copied into the resulting .dll file by the
gmcs compiler. Other code from such libraries is not copied
and must be supplied separately to KiwiC. To do this, list the
libraries along with the main executable on the KiwiC command line.
WARNING: THE ATTRIBUTE LIST IS CURRENTLY NOT STABLE AND THIS LIST IS NOT COMPLETE. For the most up-to-date listing, see hprls/kiwi/Kiwi.cs.
The C# language provides a mechanism for defining declarative tags, called attributes, that the programmer may place on certain entities in the source code to specify additional information. An attribute is specified by placing the name of the attribute, enclosed in square brackets, in front of the declaration of the entity to which it applies. We present design decisions regarding attributes that allow a C# program to be marked up for synthesis to hardware using the KiwiC compiler that we are developing [3]. This compiler accepts CIL (common intermediate language) output from either the .NETor Mono C# compilers and generates Verilog RTL.
Purposes:
Methods marked as remote can be used in two different ways by a parent compilation. They may either be called anonymously (in the same way that a floating-point adder will be instantiated and used without any high-level view of the FU instance name) or else a shared-resource name (or indicator: SRI) may be used that identifies a particular instance and an OO (aka TLM) call is made. (In the HPR L/S back end, the first argument to a TLM call is an instance identifier (SRI) in the same way that the first argument in a C++ or CSharp method call is the object handle.)
The argument to Kiwi.Remote("...") is a string that contains a list of semicolon-separated key/value pairs.
Keys avaliable include all of the so-called fsems and these specific ones:
[Kiwi.Remote("protocol=HFAST1;externally-instantiated=true)]
public return_type entry_point(int a1, bool a2, ...)
{ ... }
If fs_inhold is specified, the caller will maintain the input values throughout the operation, but the default is that the input data is likely to be removed straight a fter the input handshake (fs_inhold=false).
Fsems are [ ``NONREF''; ``EIS''; ``YIELDING''; ``MIRRORABLE''; ``INHOLD''; ``OUTHOLD''; ``ASYNCH'' ]
The instance that provides the remote method may be internally or externally instantiated in the generated RTL. External mode requires the system integrator to instantiate the component and to wire it to additional formals to the current module. Internal mode has the instance generated inside the current module and wired up as part of the current module synthesis.
When an implemented or up-called method is marked as `Remote', a protocol is given and KiwiC generates additional I/O terminals on the generated RTL that implement a stub for the call. The originally implemented protocol, HSIMPLE, was asynchronous, using a four-phase handshake and a wide bus that carries all of the arguments in parallel. Another bus, of the reverse direction, conveys the result where non-void. Further protocols can be added to the compiler in future, but we would like to instead lift them so they can be specified with assertions in C# itself. Today we use HFAST1 mainly (which can be a form of AXI-3 streaming when all 4 handshake nets are used).
Over two runs, KiwiC will generate hardware both for the client and the server as separate RTL files. In more-realistic examples, there will be multiple files, with one being the top-level that contains client calls to some of the others which in turn make client calls to others, with the leaf modules in the design hierarchy being servers only.
Where a design contains Remote-marked methods, KiwiC must be invoked more than once. For each run KiwiC must deduce or be instructed the root for the compilation: i.e. whether to compile the remote method body/bodies or the caller. This can either be done explicitly with the -root command-line flag or else inferred depending on whether there is HardwareEntryPoint as part of the current compilation. The explicit method must be used when there are three or more layers of incrementatal compilation.
Deduced compilation root procedure (text needs revising...):
One can also envision leaf modules in the design hierarchy making upcalls to parents, but this is not currently implemented in Kiwi. Yes it is, sort of, via `externally-instantiated' markup, where the callee is outside the generated RTL module structurally. Please explain further.
class test10
{
static int limit = 10;
static int jvar;
// Note four-phase is old, predating HSIMPLE - we should now be
// using HFAST1 connection to NoC etc..
[Kiwi.Remote("protocol=HFAST")]
public static int bumper(int delta)
{
jvar += delta;
return jvar;
}
[Kiwi.HardwareEntryPoint()]
public static void Main()
{
Console.WriteLine(``Test 10 Limit='' + limit);
for (jvar=1;jvar<=limit;jvar+=2)
{
Console.Write(jvar + `` ``);
}
Console.WriteLine(`` Test 10 finished.'');
}
}
See test19 and test67 in the regression suite and the demo on this link
http://www.cl.cam.ac.uk/research/srg/han/hprls/orangepath/timestable-demo/rpc.html
The following two attributes are commonly used together when a simple library function such as sqrt is declared.
The 'reftran=true' designation is an assertion to the Kiwi toolchain that the method is referentially transparent. This strictly means that the method will always give the same result for the same argument. To KiwiC it is an assertion that the method does not have to be called if the result is not needed and that calling it more times than would happen in the WD execution environment.
The 'mirrorable=true' designation is an assertion to the Kiwi toolchain that more than one instance of the called component can be deployed by the restructure and/or HPR System Integrator parts of the tool chain.
As well as overrides, OO languages like C# support method overloading. KiwiC supports method overloading in general. Alternative definitions of an overloaded method differ in terms of their arity and argument types. They may also have method-generic type variables that can be instantiated with different types.
Invokation of an overloaded method defined and called within a single compilation is handled by the lookup methods that match the C# types as normal. No unexpected behaviour needs to be considered.
But an issue related to method overloading arises with incremental compilation under KiwiC. The problem is akin to the C++ linking problem with method overloads: a separate low-level identifier is needed for each overloaded definition in the generated object code. The solution is to squirrel the arity and argument types into the name of the generated object. For instance, a separately-compiled RTL module providing mathematical functions such as sqrt() and exp() will most likely provide definitions for several precisions. Each definition needs a separate name.
Where a method is to be remotely called and more than one definition of it is to be provided. The overloaded=true setting must be added to the Kiwi.Remote() markup in both the actual definition of the method and any stub that is used as a proxy by the caller. This causes the generated method's name to be extended with an argument type squirrel. The modified name will be visible in the IP-XACT metafiles and concrete outputs in RTL and SystemC etc..
Alternative overloads of the same method must be provided in a common CIL assembly (a single .dll file). (All parts of a C# partial class definition must be within the one assembly). Currently KiwiC compiles all Remote marked overloads and puts them in the same RTL file which will contain one RTL module for tha assembly with disjoint terminals for the different methods. If not all of the methods are used in a given application, which is typically the case, the unused variants will be removed outside the Kiwi toolchain by subsequent RTL tools owing to their output terminals being disconnected.
Note: methods of the same name in different classes have unique hierarchic and flattened names and are not affected by overloading considerations.
Invoking a remote method in blocking style stalls the sequencer of the calling thread. Parallelism is thereby lost. Asynchronous dispatch using Kiwi.Remote() provides a non-blocking interface but the result must be void at the moment. TODO: notes on integrating with the C# asynchronous delegates and await ...
C# now has the `await keyword. We have done some experiments with support for this ... whitepaper in preparation ...
Kiwi.NeverReached("This code is not reached under KiwiC compilation.");
This call can be inserted in user code to create a compile-time error if elaborated by KiwiC. If a thread of control that is being expanded by KiwiC encounters this call, it is a compile-time error.
For flagging invalid run-time problems, please use System.Diagnostics.Debug.Assert within Kiwi code.
This section needs joining up with the repeated copy elsewhere in this manual!
Many net-level hardware protocols are intolerant to clock dilation. In other words, their semantics are defined in terms of the number of clock cycles for which a condition holds. A thread being compiled by KiwiC defaults to soft pause control (or other default set in the recipe or command line), meaning that KiwiC is free to stall the progress of a thread at any point, such as when it needs to use extra clock cycles to overcome structural hazards. These two approaches are incompatible. Therefore, for a region of code where clock cycle allocation is important, KiwiC must be instructed to use hard pause control.
The Kiwi.Pause() primitive may be called without an argument, when it will pause according to the current pause control mode of the calling thread. It may also be called with the explicit argument ` soft' or `hard'.
The current pause control mode of the current thread can be updated by calling
`Kiwi.SetPauseControl'.
When a thread calls Kiwi.SetPauseControl(hardPauseControl) its subsequent actions will not be split over runtime clock cycles except at places where that thread makes explicit calls to Kiwi.Pause() or makes a blocking primitive call.
The default schedulling mode for a thread can be restored
by making the thread calls
Kiwi.SetPauseControl(autoPauseControl).
Finally, blockb pause control places a clock pause at every basic block
and maximal pause control turns every statement into a separately-clocked operation
Kiwi.SetPauseControl(maximalPauseControl).
The Kiwi.Pause() primitive may be called with an argument that is an integer denoting a combination of built-in flags. This enables per-call-site override of the default pause mode.
public static void EndOfElaborate()
{
// Every thread compiled by KiwiC has its control flow partitioned
// between compile time and run time. The division is the end
// of elaboration point.
// Although KiwiC will spot the end of elaboration point for itself,
// the user can make a manual call to this at the place where they
// think elaboration should end for confirmation.
// This will be just before the first Pause in hard-pause mode or
// undecidable name alias or sensitivity to a run-time input etc..
}
Put a call to `Kiwi.NoUnroll(loopvar)' in the body of a loop that is NOT to be unrolled by KiwiC. Pass in the loop control variable.
If there is a `KiwiC.Pause()' in the loop, that's the default anyway, so the addition of a NoUnroll makes no difference.
The number of unwinding steps attempted by the CIL front end can be set with the `-cil-uwind-budget N' command line flag. This is different from the ubudget command line flag used by the FSM/RTL generation phase.
Because a subsume attribute cannot be placed on a local variable in C#, an alternative syntax based on dummy calls to Unroll is provided.
OLD: Ignore this paragraph from 2015 onwards.
This manual control was used in early versions of KiwiC but has not been needed recently.
KiwiC implements an elaboration decision algorithm. It decides which variables to subsume at compile time and which to elaborate into concrete variables in the output RTL design.
The decisions it made can be examined by grepping for the word `decided' in the obj/h1.log file.
The algorithm sometimes makes the wrong decision. This is being improved on in future releases.
For variables that can take attributes in C# (i.e. not all variables), it can be forced one way or the other by instantiating one of the pair of attributes, Elaborate or Subsume.
For example, to force a variable to be elaborated, use:
![]()
Examples of variables that cannot be attributed is the implied index variable used in a foreach loop, or the explicit local defined inside a for loop using the for (int i=...;... ; ...) syntax.
The force of an elab can also be made using the -fecontrol command line option. For instance, one might put -fecontrol 'elab=var1;elab=var2';
See §8.
Integer variables of width 1, 8, 16, 32 and 64 bits are native in C# and CIL
but hardware designers frequently use other widths. We support declaration
of registers with width up to 64 bits that are not a native width using
an `HwWidth' attribute. For example, a five-bit register is defined
as follows.
![]()
When running the generated C# natively as a software program (as opposed to compiling to
hardware), the width attribute is ignored and wrapping behaviour is
governed by the underlying type, which in the example is a byte.
We took this approach, rather than implementing a genuine
implementation of specific-precision arithmetic by overloading every
operator, as done in OSCI SystemC [1], because it results in much more
efficient simulation, i.e. when the C# program is run natively.
Although differences between simulation and synthesis can arise, we expect static analysis in KiwiC to report the vast majority of differences likely to be encountered in practice. Current development of KiwiC is addressing finding the reachable state space, not only so that these warnings can be generated, but also so that efficient output RTL can be generated, such that tests that always hold (or always fail) in the reachable state space are eliminated from the code.
The following code produces a KiwiC compile-time error because the wrapping behaviour in hardware and software is different.
![\begin{quoze}[Kiwi.HwWidth(5)]byte fivebits;
void f()
{
fivebits = (byte)(fivebits + 1);
}
\end{quoze}](img17.png)
The cast of the rhs to a byte is needed by normal C# semantics.
Compiling this example gives an error:
![]()
Q. Can I pass constant expressions into my attributes, such as Kiwi.HwWidth(), to make highly-parameterisable code? When do the constant expressions get evaluated?
Can values set via Kiwi.RtlParameter() be used within hardware width expressions attributes?
Input and Output Ports can arise and be defined in a number of ways.
Net-level I/O ports are inferred from static variables in top-most class being compiled.
These are suitable for GPIO applications such as simple LED displays and push buttons etc..
The following three examples show input and output port declarations, where
the first two have their input and output have their width specified by the underlying type and
the last by an explicit width attribute.
![]()
KiwiC can create obscure names if these I/O declarations are not in a top-level class.
So, the contents of the string are a friendly name used in output files.
For designers used to the VDHL concept of a bit vector, we also allow
arrays of bools to be designated as I/O ports. This can generate more
efficient circuits when a lot of bitwise operations are performed on an I/O port.
![]()
Although it makes sense to denote bitwise outputs using booleans, this may require
castings, so ints are also allowed, but only the least significant bit will be an I/O port
in Verilog output forms.
Currently we are extending the associated Kiwi library so that abstract data types can be used as ports, containing a mixture of data and control wires of various directions. Rather than the final direction attribute being added to each individual net of the port, we expect to instantiate the same abstract datatype on both the master and slave sides of the interface and use a master attribute, such as `forwards' or `reverse', to determine the detailed signal directions for the complete instance.
The following examples work
![\begin{quoze}
// four bit input port
[Kiwi.HwWidth(4)]
[Kiwi.InputPort('''')]...
... din;
\par
// six bit local var
[Kiwi.HwWidth(6)] static int j = 0;
\end{quoze}](img21.png)
A short-cut form for declaring input and output ports
![\begin{quoze}[Kiwi.OutputIntPort('''')]
public static int result;
\par
[Kiwi.OutputWordPort(31, 0)]
public static int bitvec_result;
\end{quoze}](img22.png)
The C# language supports primitive data word lengths up to 64 bits. Sometimes, for high-performance interfaces, we require net-level I/O busses that are wider than this.
C# structs are valuetypes that may contain more bits and, being valuetypes, they are passed by value.
This can be achieved by attaching the net-level attribute markups to arrays.
Coding style `lostio'. See test51 in the regression deck.
Note: this style stopped working in about 2010 but is just being made to work again (Dec 2016).
![\begin{quoze}
// Wide input and output, net-level I/O.
[Kiwi.InputWordPort(''w...
...or (int p=0; p<widein.Length; p++)
{
wideout[p] = widein[p];
}
}
\end{quoze}](img23.png)
Coding style using structs ... being fixed ...

You do not need to worry about clock domains for general scientific computing: they are only
a concern for hardware interfacing to new devices.
KiwiC generates synchronous logic. By default the output circuit
has one clock domain and requires just one master clock and reset input. The allocation of work to clock cycles in the generated
hardware depends on the current `pause mode' and the bevelab-soft-pause-threshold unwind budget described in [3]
and the user's call to built-in functions such as `Kiwi.Pause'.
Terminal names clk and reset are automatically generated for the default clock domain.
To change the default names, or when more than one clock domain is used, a `Kiwi.ClockDom()'
attributes is used to mark up a method, giving the clock and reset nets
to be used for activity generated by the process loop of that method.
![]()
A negative edge clock is generated if the third argument is provided "clockPolarity=neg".
Mechanisms for clock enables, overring the default reset synchronicity and clock enable guard will be supported soon, using further colon-separated properties inside the third argument.
Each thread, hardware entry point or remote-callable method has its own, so-called `directorate' and the clock domain properties are part of a directorate. Only one directorate is allowed for a thread, but that thread may call methods called from (shared with) other threads: their bodies get in-lined in the elaboration of the thread..
Object-oriented software sends threads between compilation units to perform
actions. Synthesisable Verilog and VHDL do not allow threads to be passed between
separately compiled circuits: instead, additional I/O ports must be added to
each circuit and then wired together at the top level. Accordingly, we mark up
methods that are to be called from separate compilations with a remote attribute.
![]()
When an implemented or up-called method is marked as `Remote', a
protocol is given (or implied) and KiwiC generates additional I/O terminals on the
generated RTL that implement a stub for the call. The originally implemented
protocol, HSIMPLE, was synchronous (using the current clock domain - TODO explain how to wire up), using a four-phase handshake and a wide bus
that carries all of the arguments in parallel. Another bus, of the
reverse direction, conveys the result where non-void. Further protocols
have now been added to the compiler.
A remote-marked method is either an entry point or a stub for the current compilation. This is inferred depending on whether it is called from other hardware entry points (roots).
If it is called, then it is treated as a stub and its body is ignored. Call sites will initiate communication on the external nets. The directions of the external nets is such as to send arguments and receive results (if any).
If it is not called from within the current compilation, then it is treated as a remote-callable entity. The directions of the external nets is such as to receive arguments and return results (if any).
In the regression suite, test19 is an old example and new examples calling to maths modules are being added...
public static int KPragma(bool fatalFlag, string cmd_or_message)
public static int KPragma(bool fatalFlag, string cmd_or_message, int arg0)
public static int KPragma(bool fatalFlag, string cmd_or_message, int arg0, int arg1)
Kiwi.KPragma with first argument as Boolean true can be used to conditionally abend elaboration.
This behaves the same way as System.Diagnostics.Debug.Assert described in §7.15 except that a
user-defined error code can be passed in arg0.
Note, you may want to use Trace.Assert instead and to 'export MONO_TRACE_LISTENER=Console.Error'
With the Bool false, it is used to log user progress messages during elaboration.
Kiwi.KPragma calls present in run-time loops can be emitted at runtime using the Console.WriteLine mechanisms (in the future - current release ignores them beyond elaboration).
Kiwi.KPragma calls with magic string values will be used to instruct the compiler, but no magic words are currently implemented.
Sometimes it is convenient to generate compile-time errors or warnings. Othertimes we want to flag a run-time abend, as per §2.2.
Typically you might want to direct flow of control differently using the function Kiwi.inHardware()
and to abort the compilation if it has gone wrong. Call the function Kiwi.KPragma(true/false, ``my message'') to generate
compile time messages. If the first arg holds, the compilation stops, otherwise this serves as a warning message.
You can make use of System.Diagnostics.Debug.Assert within Kiwi code.
In KiwiC 1.0 you have to re-code dynamic arrays with static sizes and this is needed for all on-chip arrays in Kiwi 2.0. The code below originally inspected the fileStream Length attribute and created a dynamic array. But it had to be modified for Kiwi 1.0 use as follows
int length = (int)fileStream.Length; // get file length - will be known at runtime only
System.Console.WriteLine("DNA file length is {0} bytes.", length);
const int max_length = 1000 * 1000 * 10; // Arrays need to be constant length for Kiwi use.
System.Diagnostics.Debug.Assert(length <= max_length, "DNA file length exceeds static buffer size");
buffer = new byte[max_length]; // create buffer to read the file
int count; // actual number of bytes read
int sum = 0; // total number of bytes read
// read until Read method returns 0 (end of the stream has been reached)
while ((count = fileStream.Read(buffer, sum, length - sum)) > 0)
{
sum += count; // sum is a buffer offset for next reading
}
System.Console.WriteLine("All read, length={0}", sum);
The C# compiler may/will ignore the Assert calls unless some flag is passed ...
Universal assertions about a design can be expressed with a combination of a predicate
method (i.e. one that returns a bool) and a temporal logic quantifier embedded
in an attribute. For instance, to assert that whenever the following method
is called, it will return true, one can put
![]()
where the string AG is a computational tree logic (CTL)
universal path quantifier and the second argument is a message that
can be printed should the assertion be violated. Although the
function `pred1' is not called by any C# code, KiwiC
generates an RTL monitor for the condition and Verilog $display
statements are executed should the assertion be violated. In order to
nest one CTL quantifier in another, the code of the former can simply
call the latter's method. Since this is rather cumbersome for the
commonly used AX and EX quantifiers that denote behaviour
in the next state, an alternative designation is provided by
passing the predicate to a function called `Kiwi.next'. A
second argument is an optional number of cycles to wait, defaulting to one if
not given. Other temporal shorthands are provided by
`Kiwi.rose', `Kiwi.fell', `Kiwi.prev', `Kiwi.until' and `Kiwi.wunitl'. These
all have the same meaning as in PSL.
We are currently exploring the use of assertions to describe the complete protocol of an I/O port. Such a description, when compiled to a monitor, serves as an interface automaton. To automatically synthesise glue logic between I/O ports, the method of [4] can be used, which implements all non-blocking paths through the product of a pair of such interface automata.
Sometimes it is helpful to generate an RTL file from a single run of KiwiC that is to be instantiated many times. Each time will use a different run of the FPGA logic synthesiser tools. It is handy to be able to pass in a constant at the logic synthesis time that might be different for each instance.
A good use-case example is when link editing a number of components into a single entity that will use a shared memory bank. Each component wants its datastructures at a different address in the memory bank. The HPR System Integrator computes base addresses and provides a parameter overide for the KiwiC-generated logic.
Within C#, in order to read in a logic-synthesis constant we use the Kiwi RtlParamter attribute as in:
class RTLprams1
{
[Kiwi.RtlParameter("rtl_pram1", 1001)] public static int rtl_pram1 = 1001;
[Kiwi.RtlParameter("rtl_pram2")] public static int rtl_pram2;
...
}
Parameters of this nature should generally have the type int. For well-formed RTL, those with default values should preceed those without.
This leads finally to an RTL module with signature such as
module DUT #(parameter rtl_pram1=32'sd1001,
parameter rtl_pram2)
(input clk,
input reset,
...);
...
Arrays allocated by the C# code must be allocated hardware resources. Small arrays are commonly converted directly into Verilog array definitions that compile to on-chip RAMs using today's FPGA tools. There are a number of (adjustable) threshold values that select what sort of RAM to target. Larger arrays are placed off-chip by default. Arrays that are only written at each location precisely once with a constant value for each location are treated as read-only look-up tables (ROMs).
Sometimes there are multiple ports to a given memory space/bank for bandwidth reasons. For instance, on the Xilinx Zynq, it is common to use two high-performance AXI bus connections to the same DRAM bank. In addition, there can be multiple memory controllers each with its own channel. We prefer the term channel to the older term bank since bank now refers to an internal bank within a DRAM chip that can have up to one row open in each bank. Kiwi does not currently support multiple channels.
Terminology summary: we use the following hierarchy of terms to describe the off-chip memory architecture: bit, lane, word, row, col, bank, rank, channel.
Explanation: A word is addressed with a binary address. The row, col, bank and rank are all fields in the address. Ordering between col and bank may vary. Channels potentially have disjoint address spaces. Mapping the channel number into the address would eliminate spatial reuse and simply be an extension of the rank. Within the word there are multiple lanes that are separately writable and each lane has some number of bits. In today's CPUs from Intel and ARM, the lane size is 8 (a byte lane) and the word size is also 8, making it a 64-bit word. On FPGAs, where clock frequencies are lower than DRAM speeds, word sizes of 512 can commonly be used with a correspondingly larger number of lanes.
In this documentation, we use the term `off-chip' to denote resources that are not instantiated by KiwiC and which, instead, are provided by the substrate platform. In reality, the resources might physically be on the same silicon chip as the FPGA programmable logic.
Each array with off-chip status is allocated a base address in one of some number of off-chip memory channels and accessed via one or more off-chip load/store ports.
Overall, these thresholds and attributes map each RAM instance to a specific level in a four-level memory technology hierarchy:
The number of ports is unlimited for type 1 (register file) and the FPGA tools will typically implement such a register file if the number of operations per clock cycle is more than one. This depends on the number of subscription operators in the generated RTL, the number of different address expressions in use and whether the tools can infer disjointness in their use.
For types 2 through 4, the number of ports is decided by KiwiC and it generates that number of read, write and address busses. By default, KiwiC uses one port per clock domain, but this can be influenced in the future with PortsPerThread and ThreadsPerPort attributes.
In the current version of Kiwi, the bondout-loadstore-port-count recipe setting configures the number of load/store ports available per thread Also, each thread that makes off-chip loads and stores must have its own port since KiwiC does not automatically instantiate the DRAM (HFAST) arbiters: instead the substrate top-level needs to instantiate the arbiters when KiwiC generates more DRAM ports than physically exist on the FPGA.
The three thresholds set in the command line or recipe that distinguish between the four memory types are :
In addition to comparing sizes against compilation thresholds, the user can add CSharp attributes to instances to force a given technology choice on a per-RAM basis.
The SynchSRAM(n) attribute indicates that an array is to be mapped to an on-chip RAM type that may not be the default for its size. The argument is the number of clock cycles of latency for read. When the argument is omitted it defaults to unity - the standard value for FPGA BRAM.
The CombSRAM(n) attribute indicates that an array is to be mapped to an on-chip RAM type that may not be the default for its size. Only small RAMs are mapped to register files or LUT RAM with combinational (zero cycle) read, but this attribute will force any sized RAM to be mapped that way. Note that LUT RAM is very inefficient in FPGA area terms and should be avoided for larger structures of 32 words or more.
TODO: describe PortsPerThread and so on... these control multi-port RAMS and how the number of external ports is configured.
Kiwi has a scheduller in its restructure phase that runs at compile time to sequence operations on scarce resources such as complex ALUs and memory resources. Kiwi supposedly implements run-time arbitration for resources that are contended between threads, but the reality is currently different. It follows three policies: 1. For 'on-chip' RAMs like FPGA B-RAM it allocates one port per thread so, with Xilinx and Altera that support up to two ports only two threads can access an 'on-chip' B-RAM. 2. For ALUs it does not share them between threads and starts the ALU budgeting freshly for each thread, just as though the threads had been separately compiled. 3. For `off-chip RAM' like DRAM, it generates one (more are possible via the command line) HFAST port per thread. The user must currently manually instantiate arbiters that mux this collection of ports onto the DRAM banks that are available.
However, Kiwi does not care whether `off-chip' resources are actually off-chip and instead one can use the off-chip technique to multiplex and arbitrate multiple threads onto on-chip resources, such as a large, manually instantiated B-RAM.
External instantiation is when a component that could logically be an instance within the current module is instead instantiated outside the current module and the current module thereby gets additional I/O nets for connecting to the external instance. Those nets would normally just be local to the current module.
To increase memory performance, three techniques are generally available (these techniques may not all be sensible for off-chip RAM resources). All of these increase the number of data bus wires to RAMs, thereby increasing available throughput.
Kiwi.Mirror(n) directive applied to a C# array instructs KiwiC
to make multiple copies of the RAM or ROM. This is most sensible for ROMs since all copies of a RAM must be updated with every write.
Kiwi.Widen(n) directive applied to a C# array instructs KiwiC to pack
Kiwi.Stripe(n) directive applied to a C# array instructs KiwiC to allocate
(In order to pack multiple user arrays into a single RAM on the FPGA, additional directives are needed. Not described here currently.)
res2-combrom-threshold.
ROM inference in KiwiC can be turned off
with flag repack-to-rom=disable in which case RAMs are commonly generated and initialised with the ROM contents
after the run-time reset. But, when ROMs are present, they are manifest in the generated Verilog RTL as arrays that have
their only write operations embodied in Verilog initial statements that install the fixed data.
ROMs can sometimes usefully be mirrored. The Kiwi.Mirror(4) attribute can be applied to
individual array instances to mirror them.
[Kiwi.Mirror(4)]
static readonly uint[] htab4 =
{ 0x51f4a750, 0x7e416553, 0x1a17a4c3, 0x3a275e96,
... many more entries ...
};
Or else the command line flag repack-to-rom=4 can be added, which would replicate all ROMs up to a factor
of 4, but the additional copies would not be generated if they cannot usefully be used.
The Kiwi.OutboardArray() attribute forces that an array is to be mapped
to a region of external memory instead of being allocated a private
array (BRAM memory) inside the current compilation. Large arrays are placed off chip in this way by default without using an attribute. (Large is determined
by comparing res2-offchip-threshold).
It is up to the substrate architect what sort of memory to
attach to the resulting port: it could range from simple large SRAM bank to multiple DRAM banks with caches.
With a string argument provided, this is the name of a load/store port name or DRAM bank name (user or logical name). This provides a manual load-balancing override for the memory subsytem allocator.
OLD: The fullest version of this attribute takes two arguments: a bank name and an offset in that bank.
OLD: Pre performance profiling: In general, arrays can be mapped to a specific bank by giving the bank name and leaving out the base address. KiwiC will then allocate the base addresses for each memory to avoid overlaps. If no bank name is given, (unit arg Kiwi.OutboardArray()) then a default of 'bondbank0' is automatically supplied. Therefore, without using any attributes, all large arrays are mapped into consecutive locations of a memory space called 'bondbank0'.
Note: the older bondbank0 is now renamed as bondbank0.
TODO: profile-directed feedback will balance up the ports in the future.
Using the special argument `-onchip-' the Kiwi.OutboardArray("-onchip-") attribute forces that an array is not offboard regardless of size. Clearly this may result in a design that is unsuitable for the target technology.
KiwiC generates load/store ports to access off-chip memory. (Off-chip means not instantiated by KiwiC, so the addressed resource can be on the same die in reality). With more load/store ports in use, greater memory access bandwidth is available AND greater opportunities for out-of-order memory service exist.
The off-chip port architecture is defined in recipe/command line settings. It is also written as a report file in every KiwiC run. The Off-chip Memory Physical Ports/Banks report looks something like this:
*-----------+----------+--------+--------+-------+-----------* | Name | No Words | Awidth | Dwidth | Lanes | LaneWidth | *-----------+----------+--------+--------+-------+-----------* | loadstor1 | 4194304 | 22 | 256 | 32 | 8 | *-----------+----------+--------+--------+-------+-----------*
Total load/store port width = bits per lane * number of lanes.
Default -bondout-loadstore-port-count=1
Number of LOADSTORE ports for automatic off-chipping of large RAMs.
bondout-loadstore-port-lanes 32 LOADSTORE ports - number of write lanes.
bondout-loadstore-lane-width 8 LOADSTORE lane width
A lane is normally 8 bits wide. But whatever width a lane is, we have a 'lane-addressed' address bus. The bottom (log2 no_lanes) address bits will then always be ignored (and stripped by logic synthesiser tool).
When the number of lanes is 1 no lane write enables are used and the memory is word addressed always.
A suitable behavioural Verilog fragment to connect to them for simulation test purposes is available as part of the distro in the rams folder.
Typical DRAM controllers run much faster than the FPGA user logic and hence a wide word is presented to the KiwiC-generated code of 256 bits or so.
The user's wanted data width is either rounded up to some integer multiple number of external words, or some fraction of a word where the fraction is rounded up to a bounding power of 2 number of lanes.
The restructure log file will explain, somewhat cryptically, how each DRAM bank is being used with a table that contains interleaved entries covering all the banks (portnames). The lines in this report can be decoded with experience: D16 means sixteen bits wide. AX means an array. etc..
Off-chip Memory Map *-----------------+-----------+-------+-----------+-----------* | Resource | Base | Width | Length | Portname | *-----------------+-----------+-------+-----------+-----------* | D8US_AX/CC/SOL | 0x1312d02 | 32 | 0x989680 | bondbank0 | | D16SS_AX/CC/SOL | 0x0 | 32 | 0x1312d02 | bondbank0 | *-----------------+-----------+-------+-----------+-----------*
Performance generally needs to be enhanced above this baseline by packing data sensibly into DRAM words. Also, support of multiple in-flight requests is preferable for the highest performance.
The KiwiC-generated code should be connected to an externally-provided memory controller that will often also also include some sort of cache.
Three off-chip protocols are supported BVCI, HSIMPLE and HFAST. HFAST is most commonly used. BVCI allows multiple transactions to be in flight. AXI is now being added shortly to KiwiC, replacing BVCI, but there are also some AXI components in the support and subtrates library. Including an HFAST to AXI protocol bridge and AXI master and slave shims for the Zynq substrate for CPU interaction and DRAM access.
When we say `off-chip' we simply mean outside the generated hardware circuit - the substrate configuration may put various items on the same Physical chip.
KiwiC will shortly be enhanced to issue prefetch bus cycles on off-chip RAMs. These are appropriate for cached DRAM and sometimes appropriate for uncached off-chip RAMs. They serve no useful function for SRAM (static RAM), whether on-chip or off-chip, owing to its uniform access latency.
The implementation of HSIMPLE within KiwiC was a low performance. It will be deleted soon as we converge to HFAST and AXI protocols for everything.
Low-performance HSIMPLE uses four-phase handshake and only transfers data once every four clock cycles. It is more suitable for connecting to simple peripherals than DRAM. The following nets will require connection to the synthesis output when the DRAM is in use with the default, simple, 4/P HSIMPLE protocol.
output reg hs_dram0bank_req,
input hs_dram0bank_ack,
output reg hs_dram0bank_rwbar,
output reg [255:0] hs_dram0bank_wdata,
output reg [21:0] hs_dram0bank_addr,
input [255:0] hs_dram0bank_rdata,
output reg [31:0] hs_dram0bank_lanes,
When the number of lanes is one, there are no lane outputs.
HFAST1 is our primary protocol for load/store ports to DRAM. It has half-duplex and simplex variants. Protocol adapators to AXI4 and AXI4-Lite are in the distribution.
HFAST1 offers one cycle read latency and back-to-back operations, achieving 100 percent throughput. It is ideal for front-side cache connections where prefetch is not used.
The signature for HFAST is typically as follows (the total width and number of lanes and address bus width are all parameterisable).
output reg hf1_dram0bank_OPREQ, input hf1_dram0bank_OPRDY, // Any posedge clk with overlap of opreq and opack starts a new request. input hf1_dram0bank_ACK, // Ack acknowledges the last request is complete. output reg hf1_dram0bank_RWBAR, // 1=read, 0=write on request active clock edge. output reg [255:0] hf1_dram0bank_WDATA, // For write, data to be written, valid on request active clock edge. output reg [21:0] hf1_dram0bank_ADDR // Address, valid on request active clock edge. input [255:0] hf1_dram0bank_RDATA, // Read result, valid on ack cycle. output reg [31:0] hf1_dram0bank_LANES, // Byte lane qualifiers.
A half-duplex port has RWBAR. A storeport has no RDATA and a loadport has no WDATA or LANES. LANES are only present if there is more than one lane per word. There is no full-duplex port: instead one uses a pair of simplex ports.
IP-XACT definitions for all variants are in the Kiwi distribution. Their names follow a scheme such as HFAST1_M_RONLY which denotes an outstanding transaction count of 1, master side interface, (simplex) write only.
When the number of lanes is 1 no lane write enables are used and the memory is word addressed always.
A DDRAM2 controller is available in the file kiwi/rams/ddr2-models. This can be used for high-level simulations. It instantiates the DDR_DRAM_BANK underneath itself.
A behavioural model of a DDRAM2 is available in the file kiwi/rams/ddr2-models. It has signature:
// (C) 2010-14 DJ Greaves.
// Verilog RTL DDR2 behavioural model - fairly high level.
// The SIMM or DIMM (all the chips of the bank) is modelled with one RTL module.
module DDR_DRAM_BANK(
input clk, // DDR Clock - 800 MHz typically. We use one edge only and double the datapath width.
input reset, // Active high synchronous reset
input ddr_ras, // Active low row address strobe
input ddr_cas, // Active low col address strobe
input [log2_internal_banks-1:0] ddr_ibank,// Internal bank select
input ddr_rwbar,// On CAS: 1=read, 0=write. On RAS 1=precharge, 0=activate.
input [2*dwidth-1:0] ddr_wdata, // The wdata and rdata busses are here twice their width in reality owing to DDR.
input [awidth-1:0] ddr_mux_addr, // Multiplexed address bus
input [2*dwidth/8-1:0] ddr_dm, // Lanes: Separate nets here for +ve and -ve edges instead of combined.
output reg [2*dwidth-1:0] ddr_rdata); // Read data bus.
parameter log2_dwidth = 5;
parameter dwidth = (1<<log2_dwidth); // Word width in bits - we actually have twice this to achieve/simulate double data rate.
// FOR DRAM style
// E.g. MT41K256M32-125 DDR3 @ 800 MHz/1.25ns RCD-RP-CL=11-11-11 Arch=32M x 32 bits x 8 banks = 8Gb = 1GB. Row bits=15, Col=10, Bank=3.
parameter LOG2_ROW_SIZE = 15; // Log_2 number of words per RAS
parameter LOG2_COL_SIZE = 10; // Log_2 number of words per CAS
parameter PRECHARGE_LATENCY = 11;
parameter ACTIVATE_LATENCY = 11;
parameter CAS_LATENCY = 11;
parameter log2_internal_banks = 3;
parameter awidth = LOG2_ROW_SIZE; // Address width in bits - word addressed.
// DRAM burst size - can be dynamically encoded in high-order CAS address. Currently fixed at 32 bytes.
With a 32 bit data bus (64 after doubling for DDR) this requires 4 clocks to transfer the burst.
parameter burstSize = 4;
HFAST2 is the same as HFAST1 but uses a two-cycle, fully-pipelined read latency.
A simple cache is provided. Its signature is:
module cache256_hf1 (input clk, input reset, // synchronous, active high. // Front-side interface input fs_rwbar, output reg [noLanes*laneSize-1:0] fs_rdata, input [noLanes*laneSize-1:0] fs_wdata, input [addrSize-1:0] fs_wordAddr, output fs_oprdy, input fs_opreq, output reg fs_ack, input [noLanes-1:0] fs_lanes, // Back-side interface output reg bs_rwbar, input [noLanes*laneSize-1:0] bs_rdata, output reg [noLanes*laneSize-1:0] bs_wdata, output reg [addrSize-1:0] bs_wordAddr, input bs_oprdy, output reg bs_opreq, input bs_ack, output reg [noLanes-1:0] bs_lanes ); parameter dram_dwidth = 256; // 32 byte DRAM burst size or cache line. parameter laneSize = 8; parameter noLanes = dram_dwidth / laneSize; // Bytelanes.
The cache must be manually instantiated by the substrate designer.
HFAST arbiters can be instantiated on the front or back side of the cache, so that multiple synthesised load/store ports can share one cache or multiple caches can share one DRAM bank. Sharing would be inconsistent.
The default substrate runs the DRAM and DRAM controller at 800 MHz and the Cache and KiwiC generated code at 133 Mhz which is 1/6th of this.
Text missing. Not being used.
AXI has become the most prevalent SoC and FPGA bus interface standard. AXI supports burst transactions and out-of-order service. Such AXI service discipline is well-suited to a high-performance DRAM bank controller. (Such a bank controller typically has 8 internal banks, all of which can be concurrently open on a DRAM row.)
Today's CPUs use multiple load/store stations per core that are pari passu with that core's ALUs. KiwiC-generated hardware is no different. Each load/store station is busy with at most one scalar load/store request and this can only be served in order.
As with CPUs, there are two techniques that adapt between single-issue load/store stations: multiplexing and caching.
KiwiC load/store stations are served with HFAST interfaces. In the fullness of time, KiwiC will provide automated support for HFAST to AXI adaptation but currently a substrate that manually matches the number of load/store ports is required. Currently they must be instantiated manually (but the new recipe stage that inokes HPR System Integrator should fix that soon). The easiest way is to import the Kiwi design into a GUI-based schematic editor that understands IP-XACT and use a few mouse clicks to instantiate the required protocol convertors and so on. However, the SoC Render extension can soon replace this.
The main substrate shim is boiler-plate RTL code that connects to the M_AXI_GP0 programmed I/O bus for simple start/stop control and parameter exchange. It is recommended that every design compiled has a serial number hard-coded in the C# source code and that this is modified on every design iteration. The first function of the substrate shim is to provide readback of this value.
The other features of the shim are starting and stopping the design and collecting abend codes. Sources of abend are null-pointer de-reference, out-of-memory, divide-by-zero, user assertion failure, and so on.
A Kiwi design that makes access to main memory will have a number of load/store ports. These can be half-duplex or simplex. Simplex is preferred when main memory is served over the AXI bus, as in the Zynq design. (Of course there may be a lot of BRAM memory in the synthesised design itself, but that does not appear on this figure.) Simplex works well with AXI since each AXI port itself consists of two independent simplex ports, one for reading and one for writing.
In the illustrated example, the design used three simplex load/store ports. These need connecting to the available AXI busses hardened on the Zynq design and made available to the FPGA programmable logic. The user has the choice of a cache-coherent, 64-bit AXI bus that will compete with the ARM cores for the L2 cache front-side bandwidth, or four other high-performance 64-bit AXI busses that offer high DRAM bandwidth. These four are not used in the example figure.
Each KiwiC-generated load-store port is an in-order unit, like a load or store station in an out-of-order processor. By multiplexing their traffic onto AXI-4 busses, bus bandwidths are matched and out-of-order service from the DRAM system is exploited.
Each load/store port in the generated RTL has is properly described in the IP-XACT rendered by KiwiC that describes the resulting design. When this IP-XACT is imported into a design suite, manual wiring of the load/store ports to the AXI switch ports can be done in a schematic editor. (Approaches to automate this stage are ongoing.)
Note that KiwiC as of December 2016 generates so-called HFAST ports, that are either half-duplex, loadonly or storeonly. These are what was described in the IP-XACT. The user also has to manually instantiate, in the schematic editor, little protocol convertors that come with KiwiC and which convert HFAST variants to AXI variants for connection to the vendor-provided AXI switch blocks.
The substrate typically converts the KiwiC-generated HFAST interfaces to AXI or other off-chip protocols not currently supported by KiwiC. The substrate provider writes RTL transactors to convert protocols.
KiwiC assumes it can use address zero upwards in the off-chip space. The substrate must offset the address bus to address available SoC regions if this is not the case.
KiwiC accepts a recipe parameter to bound the amount of off-chip memory it can use in its one channel. Where a design attempts to use more memory, a compile-time error is raised.
`bondout-loadstore-lane-addr-size' gives the off-chip address bus width in bits. In other words, this is the log2 no of words of memory available in each address space. Providing different limits for different off-chip spaces will be enabled in future. The word size and lane structure is defined with `bondout-loadstore-port-lanes' and `bondout-loadstore-lane-width' where the first of these is typically 4, 8, 16 or 32 and the second nearly always 8 (ie byte-sized lanes).
B-RAM instantiation is normally automatic in FPGA tools. B-RAMs with an access latency of one clock cycle are normally used although KiwiC can support zero and two cycle reads (but how to access them is not described here! TODO).
A B-RAM is inferred from a structure following one of several paradigms based on all addresses passing through a single register or all read data being passed through a single register. These can be mapped onto the same underlying technology by posting the writes as necessary but the effects of read while writing to the same location differ.
KiwiC generates on-chip RAMs as explicit instances in the generated RTL. It uses 'read before' coding style. The FPGA Vendor 'read after' forms, where newly written data is read out are not explicitly found in the generated RTL: KiwiC will forward the data for itself when needed, either at compile or run time.
// (C) Xilinx 2009. Single-Port B-RAM with Byte-wide Write Enable: Read-First mode
// Download: ftp://ftp.xilinx.com/pub/documentation/misc/xstug_examples.zip
// File: HDL_Coding_Techniques/rams/bytewrite_ram_1b.v
//
module v_bytewrite_ram_1b #(
parameter SIZE = 1024,
parameter ADDR_WIDTH = 10,
parameter COL_WIDTH = 9,
parameter NB_COL = 4)
(
input clk,
input [NB_COL-1:0] we,
input [ADDR_WIDTH-1:0] addr,
input [NB_COL*COL_WIDTH-1:0] di,
output reg [NB_COL*COL_WIDTH-1:0] do);
reg [NB_COL*COL_WIDTH-1:0] RAM [SIZE-1:0];
always @(posedge clk) begin
do <= RAM[addr];
end
generate
genvar i;
for (i = 0; i < NB_COL; i = i+1) begin
always @(posedge clk)
if (we[i]) RAM[addr][(i+1)*COL_WIDTH-1:i*COL_WIDTH] <=
di[(i+1)*COL_WIDTH-1:i*COL_WIDTH];
end
endgenerate
endmodule
// Single-Ported Block RAM with registered output Option
// Please note that XST infers distributed RAM or B-RAM based on the size.
// For small RAMs, you may need to use ram_style constraint to fore the use
of B-RAM.
module TWO_CYCLE_READ_BRAM(
input clk,
input wen,
input [6:0] a,
input [15:0] di,
output reg [15:0] do);
reg [15:0] ram [0:127];
reg [15:0] do0;
always @(posedge clk) begin
if (wen) ram[a] <= di;
do0 <= ram[a];
do <= do0;
end
endmodule
Style 1:
always @(posedge clk) begin
addr_reg <= addr ... ;
if (wen ...) data[addr_reg] <= (wdata ...);
rdata = data[addr_reg]; // Note blocking assign used or
// else the rhs freely used elsewhere.
end
Style 2:
always @(posedge clk) begin
if (wen ...) data[addr] <= (wdata ...);
rdata_reg <= data[addr]; // No other reads elsewhere
end
There are also the dual-ported equivalents of these styles, supported by both Xilinx and Altera.
See demo test50.
The FPGA libraries contain (typically) dual-port BRAMs. Where an array is small enough to instantiated as an FPGA on-chip BRAM (block RAM), and overrides are not applied, then such a BRAM will be used. Both Xilinx and Altera provided FPGAs with on-chip, dual-ported BRAMs with synchronous read latency of one cycle.
Such BRAMS are atomatically used for sharing data between up to two threads. Threads can also shared data via a scalar variables. Kiwi supports any number of threads reading or writing shared scalar variables but for BRAMs there are technology restrictions.
What if I want to get increased RAM bandwidth by allocating both ports of a BRAM to the same thread?
By default, KiwiC will use one port on an SRAM for each thread that operates on it.
However, by setting the PortsPerThread parameter or attribute to greater than one then
greater access bandwidth per clock cycle for each thread is possible. Example needed.
If three threads operated on the shared memory, KiwiC could generate an instance of a triple-ported SRAM module but this would likely not be found in a technology library when logic synthesis tools were applied.
Instead, the `off-chip' approach needs to be used. This works efficiently even for small BRAM subsystems, but additional wiring is needed outside the KiwiC-generated RTL. The HPR System Integrator aims to provide this service.
The approach is
PortsPerThread mechanism.
... we need to add a little more explanation or forward reference here please ...
There is some basic information on the Zynq substrate here: urlhttp://www.cl.cam.ac.uk/research/srg/han/hprls/orangepath/kiwic-demos/zynq-pio-dma
The substrate gateway is a hardware/software boundary for use on platforms such as Zynq or others that run embedded linux with a console, network and filesystem. It has an associated protocol for providing operating system access.
This section will explain how to do console I/O via the substrate gateway.
We also need to explain the ReadKey situation. Windows users often put a readkey call on the end of their programs to stop Windows deleting the output straightaway ...
// Keep the console window open in debug mode.
Console.WriteLine(``Press any key to exit.'');
Console.ReadKey();
The basic dotnet classes for StreamReader, StreamWriter, TextReader and TextWriter are provided via the substrate gateway. Random access using fseek is also supported.
documentation incomplete ... add KiwiFilesystemStubs.dll to your compilation ... documentation for Zynq use will be added here... Satnam's windows version ... It works fine under RTL_SIM with verilator.
The following nets will require connection to the synthesis output when the Kiwi file system is in use.
For high performance computing applications the filesystem is part of the Kiwi Substrate (alongside the DRAM).
output reg KiwiFiles_KiwiRemoteStreamServices_perform_op_req,
input KiwiFiles_KiwiRemoteStreamServices_perform_op_ack,
input [63:0] KiwiFiles_KiwiRemoteStreamServices_perform_op_return,
output reg [63:0] KiwiFiles_KiwiRemoteStreamServices_perform_op_a2,
output reg [31:0] KiwiFiles_KiwiRemoteStreamServices_perform_op_cmd,
A suitable behavioural Verilog fragment to connect to them for simulation test purposes is
/kiwi/filesystem/kiwifs_bev.v
that provides the basic console and file stat/exists/open/close/read/write calls required
by the dotnet Stream and File.IO classes.
The remainder of this part of the user manual is missing, but please check the Bowtie Geneome Sequencer demo for an example of file system use.
The Server attribute indicates that a method and the methods it calls in turn are to be allocated to a separate RTL module that is instantiated once and shared over all calling threads.
An HLS system can be set to optimise for
The main parameters for tuning the Kiwi Area/Performance tradeoff, folding space over time are:
bevelab-soft-pause-threshold parameter. The nominal range is 0 to 100 with useful values currently being between 5 and 40. A lower value tends towards more clock cycles and possibly less area. Values above 40 may lead to very long KiwiC compile time.
Kiwi.Unroll("COUNT~=4", lvar); attribute added to the C# source code
suggests that the loop whose control variable is called `lvar' is unwound by a factor of 4.
res2-offchip-threshold alter the amount of block RAM allocated. This is faster than external (off-chip) SRAM or DRAM but uses more FPGA resources.
bondout-loadstore-port-lanes alters the number of external memory ports used. These each operate in order, so if you have
more of them and mux them externally onto separate resources or an out-of-order bus then you get more parallelism and external RAM bandwidth.
fp_fl_dp_div describe the type of divider to generate. For such components you can provide
your own implementations, alongside those provided in the Kiwi libraries like cvgates.v, and specifiy whether they are fixed
or variable latency, fully-pipelined and what the fixed or expected latency in clocks cycles is.
kiwic-colour-enable setting alters the amount to which KiwiC reuses registers. With it disabled, the hardware is easier to inspect/debug, but many more registers are generated. An experimental, spatially-aware binder is being added to Kiwi at the moment. This will handle both registers and ALUs and gives a floorplan plot.
Commonly, the system DRAM will run at a hardwired clock frequency, such as 800 MHz. This is too fast for most current FPGA logic, Kiwi-generated or otherwise. An integer divisor of 4 or 5 typically needs to be applied to bring the logic speed below 200 MHz. Getting KiwiC to hit a target clock frequency is a common requirement ... TBC ...
In 2015 a performance predictor was added to Kiwi so that estimates of run-time performance can be rapidly provided without having to do an FPGA place-and-route or even a complete pre-FPGA RTL simulation. The performance predictor is based on basic block visit ratios stored in a database that is updated with the results from short runs. When the application is edited and recompiled with KiwiC, a new prediction is generated, straightaway, based on the contents of the database generated by previous versions. Short profile runs of the new design can then be run to improve prediction accuracy. Every prediction is reported with confidence limits. The reported confidence is reduced (wider error bars) both by certain design edits and by extrapolating to runs that are much longer than those used for profiling.
... Kiwi also uses the simple performance predictor from the HRP L/S library to estimate run time for a thread. This is used as a source for PlanOpt metric, when exploring the implementation space ...
Performance prediction is based on accurate knowledge of control flow branching ratios: the percentage of time a conditional branch is taken or not taken. This enables execution counts for each basic block to be estimated. Profile information from previous runs is the default basis for this knowledge. To ensure the information stored in the profile database is robust against program edits, it cannot be indexed by fragile tags such as a basic block number in global syntax-directed enumeration. Instead, performance prediction uses the method names occurring naturally in the application program as timing markers. Every method has a clear entry point as well as potentially several exit points (return statements are numbered in their textual order in the CIL byte code... branches to the exit). With loops that contain no method calls in their bodies, the user must add a method call to a dummy method (null body) and that method should be (preferably?) annotated with a KppMarker attribute. Conditional branches and basic block names are then taken in a syntax-directed way from the code between the named control-flow points and discrepancies in the control flow graph between named points is used to flag warnings and discard profile information no longer usable.
All call strings for a method can either be considered separately or in common. The call string is the concatenation of the call site textual names from the thread or program entry point. If the call strings are considered in common, they are being disregarded and the average over all call strings is used.
These attributes also enable the user to control the way the performance estimation report is presented. They also enable the user to provide a substitute loop or visit count that overrides the stored profile. This provides the basis for extrapolating the run time from a small test or profiling data set to the envisioned real date size that will be processed on the FPGA.
Where the performance predictor cannot find profile information for a branch it assumes a 50/50 division and the number of such assumptions and their effect on the confidence in the result is included in the report.
Profiles for performance prediction can be sourced from various places, including diosim, but RTL simulation is used in the following, step-by-step, example.
Kiwi.KppMark().
$finish() calls with the -kiwic-finish=disable command line flag.
NEW: We replace -kiwic-finish with -kiwife-directorate-endmode.
kpp_testbench_mon_onethread.v in the testbench using an RTL include statement.
A waypoint is a marker or milestone that shows a program has reached a certain point in its execution path. Where a program is remotely started and ultimately exits, a given waypoint should only be encountered once. For eternal servers with an outermost dispatch loop, a given waypoint should be encountered at most once per dispatched command.
Waypoints can be used in Kiwi Sequencer Mode for the main thread. They should not be used for child threads. In Pipelined Accelerator mode there is no control flow when II=1 and generally no signficant control flow, so waypoints should not be used.
Hardware itself does not have a start and end time. Instead, performance metrics are always comprise a START/FINISH pair of named events. A typical program is structured with a time-domain series of internal phases, such as `startup', `load', `compute' and `report'. Each of these should be a waypoint.
The performance predictor makes separate predictions for each phase and sums them. The confidence for different phases may be different, typically according to which part of the program was most recently edited.
A marker at a phase boundary is called a waypoint.
Kiwi.KppMark() dummy calls and/or Kiwi.KppMarker attributes are used to define waypoints. Each waypoint has a manually-allocated number and
name and all but the last start a phase that optionally is given a name via the third argument. The numbers must be disjoint but their ordering is unimportant.
The entry and exit waypoints should conventionally be called START and FINISH respectively.
The program's control flow should not loop around a waypoint (except for eternal servers as mentioned above).
If a KppMarker is found in a loop body, or a method body where that method is called more than once, the provided labels are `code-point' markers (explained below).
// Typical pattern of waypoint markup. Kiwi.KppMark(1, "START", "subsequent-phase-name1"); ... Kiwi.KppMark(2, "waypoint-name2", "subsequent-phase-name2"); ... Kiwi.KppMark(3, "waypoint-name3", "subsequent-phase-name3"); ... Kiwi.KppMarker(0, "FINISH"); // Note - only first two arguments are compulsory, which should be a disjoint natural // number and needs not be strictly ascending.
A waypoint is a special form of code point marker. The use of code point markers adds robustness to the information stored in the profile database against program edits, allowing it to be safely applied to edited programs. The markers provide index points that can be associated with loop heads and other control-flow points, to assist in robustness of the profile for complex method bodies. Basic block names are then named in a syntax-directed way with respect to, and as textual extensions of, the previous and next labelled control point.
KppMark has no innate multi-threaded capabilities and so should generally be set by an application's master/controlling thread, assuming it has one.
An exiting application has precisely one entry point. It has one exit point if other exits are are routed to a singleton exit point. Way points should appear once. Given expected visit ratios for each basic block, the problem is overconstrained and the frequency of visiting each way point and the singleton exit point can be inspected as a confidence indicator: they are all nominally visited once.
Note: many older designs have defined a net-level output called done or finished and assigned to it at the end of the main thread. Today we prefer to use Kiwi.ReportNormalCompletion() which also counts as a waypoint. We need to direct exit and so on to it...
C# attributes also enable the user to provide a substitute loop or visit count that overrides the stored profile. This provides the basis for extrapolating the run time from a small test or profiling data set to the envisioned real data set size that will be processed on the FPGA. Also, hardware itself does not have a start and end time - it is static/eternal. Instead, performance metrics are always quoted between a start/end pair of named code lables, again specified with C# attributes. Times for various phases within a program, such as `load', `process' and `write out', can also be predicted by inserting appropriate further control-graph delineations with an attribute that denotes a way point.
There is no explict support for hardware debug currently in Kiwi, other than single stepping and PC value collection when the abend syndrome is non-zero. User logic can readily provide PIO access to major state holding RAMs [LINK TO EXAMPLE NEEDED]. Note that user variable mappings to RTL registers is typically many to one and the mapping is reported in the KiwiC.rpt file generated on each run.
The directorate interface adds the following features to the generated RTL that can be hooked up to a management CPU via the substrate gateway. They each add hardware overhead but this can be trimmed out mostly by FPGA tools when reporting resources are left disconnected.
Nearly all FPGA blades have a some simple LED indicators connected to I/O pads. Kiwi has the concept of the `generic unary LEDs' for each FPGA. Kiwi defines a uniform way to drive these and the substrate makes their values available to the host CPU, which is useful when the LEDs are in a different room or continent from the application user. They will commonly be used as a user-defined mirror of the Waypoint code (§10.2).
The directorate complexity is controlled with the recipe/command-line flag -kiwife-directorate-style
The single-step and breakpoint registers are/will be present with directorate style advanced -kiwife-directorate-style=advanced in the future. Single-step can be achieved with suitable user logic connected to the clock-enable input for a thread. Note that clock enable is not a simple synchronous clock gate owing to the presence of pipelined components that cannot be freely stopped (such as BRAM).
Watchpoints are currently best implemented by the user in the C# source code and recompiled, or else use vendor tools like ChipScope etc..
The abend syndrome register is present with directorate styles normal and advanced -kiwife-directorate-style=normal.
When a component is compiled as a module to be instantiated in later KiwiC runs, it needs to have an HFAST interface (when in classical HLS major mode). The HFAST interface is generated with the command line flags
-kiwife-directorate-startmode=wait-start -kiwife-directorate-endmode=auto-restart -kiwife-directorate-ready-flag=present
A top-level HFAST interface can be wrapped as an AXI-S interface with an externally-instantiated adaptor (from the HPRSHIMS library) that itself can be instantiated by HPR System Integrator.
The abend syndrome codes used by Kiwi in classical HLS major mode are:
System.Environment.Exit(int code)
hpr_abend()
An experimental, spatially-aware binder is being added to Kiwi at the moment. This will handle both registers and ALUs and gives a floorplan plot.
Register colouring, RAM binding with memory maps and ALU binding is reported in the KiwiC report file. Only a static mapping, generated at KiwiC compile time, is used.
Kiwi generates Verilog RTL for synthesis to FPGAby vendor tools. It can also generate SystemC and CSharp but we do not commonly use those flows at the moment and their will be some regressions.
KiwiC will assume the presence of various IP blocks in Verilog. These include RAMs and fixed and floating point ALUs. It will instantiate instances of them.
The libary blocks are generally provided in the following source files:
CV_FP_ARITH_LIB=$(HPRLS)/hpr/cv_fparith.v CV_INT_ARITH_LIB=$(HPRLS)/hpr/cvgates.v CVLIBS=$(CV_INT_ARITH_LIB) $(CV_FP_ARITH_LIB)
Fixed-latency RAMs are provided in the cvgates.v. They have names such as CV_SP_SSRAM_FL1 which denotes a synchronous RAM with fixed
read latency of one clock cycle (FL1) and one port (SP). The cvgates implementations are intended to by synthesisable by FPGA tools.
Parameter overrides set the address range and word and lane width.
These blocks are found in cv_fparith.v
Example: CV_FP_FL5_DP_ADDER - floating point, fixed latency of 5 clock cycles, double precision,
CV_FP_FL_SP_MULTIPLIER
Key: FLASH=combinational.
FLn = fixed latency of $n$ clock cycles, VL variable latency with handshake wires,
blocking while busy,
DP=double precision,
SP=single precision.
The IP-XACT-based incremental compilation features are being released 2Q2017.
This section of the KiwiC manual is going out of date now -- please see §39 for up-to-date information.
Compiling everything monolithically does not scale to large projects. Separate and incremental compilation is needed in large projects to handle scale, component reuse, unit testing, revision control and is the basis for project management. It can also be a basis for parallelism. So, for larger designs, to manage complexity, it is always desirable to designate subsystems for separate compilation.
Also, the classical HLS approach embodied in the normal KiwiC compilation mode, in-lines all method calls made by a thread into one flat control-flow graph. KiwiC reuses ALUs and local variable registers in both the spatial and time domains, but tends to generate the largest and fastest circuit it can, subject to ALU instance count limits per thread set in the recipe. Even though FPGA/ASIC logic synthesiser tools typically re-encode the resulting state machine so that the output function is simple to decode, having more than a few thousand states becomes impractical. It makes sense for complex subsystems to be synthesised separately so that a call to them takes one state in the caller's sequencer. Any sequencer in the called component has its states shared over all calls. All standard library functions of any complexity are better handled in this way. Prime examples are trig and log functions and I/O marshalling such as ASCII to/from floating point. When these components are referentially transparent, KiwiC can deploy as many instances as it likes, guided by metrics.
Multi-FPGA designs require the logic to be partitioned between logic synthesis runs using separate RTL files. Again this requires incremental compilation and established protocols between the FPGAs. The approach is to use HPR System Integrator to instantiate SERDES links at the FPGA boundaries, potentially multiplexing a number of services onto the available links.
The ability to use separately-compiled components also forms the basis of a black box import mechanism for third-party IP blocks. In principle, instantiating a black box containing third-party IP is no different from instantiating a separately synthesised Kiwi module. Example Kiwi modules are standard trig and log functions, random number generators and subsystems from user designs. The CAMs on the NetFPGA boards and the new Xilinx hardened FIFOs are typical third-party black-box componenets. See test72.
Third-party IP blocks and existing hardware interfaces are typically described in terms of net-level timing waveforms or formal specifications thereof. To exploit these components from a high-level language via HLS, wrappers need to be manually written.
class blackbox_wrapper_tx_demo
{
[Kiwi.OutputWordPort("wdata")] static byte wdata;
[Kiwi.OutputWordPort("n_wstrobe")] static bool n_wstrobe;
[Kiwi.InputWordPort("n_rdy")] static bool n_rdy;
[Kiwi.OutputWordPort("n_sop")] static bool n_sop;
[Kiwi.OutputWordPort("n_eop")] static bool n_eop;
[Kiwi.Remote("protocol=HFAST")]
public static void SendPacket(byte [] darray, int len)
{
Kiwi.PauseControlSet(Kiwi.PauseControl.hardPauseEnable);
for (int i=0; i<len; i++)
{
n_wstrobe = !true;
n_sop = !(i==0);
n_eop = !(i==len-1);
wdata = darray[i];
while (!n_rdy) Kiwi.Pause();
Kiwi.Pause();
}
n_wstrobe = !false;
}
}
In some design styles, subsystems can also best be placed in a server pool with dynamic load balancing. Design-time manual control sets the number of instances generated. KiwiC will share such server instances in the time domain rather than instantiate as many as it needs (subject to ALU count limits). Note: Server pools are not currently automated within Kiwi but should involve little more than a C# library that the current KiwiC can compile.
Method designated as top-level entry points must be static. But for incremental compilation, entry points are commonly not static.
There are several cut points in the Kiwi design flow where separately-compiled modules can be combined:
.dll or .exe files on its command line. These will have been generated, typically, from
separate invokation of the C# compiler.
Kiwi.Remote() attribute described in §7.1 enables a designated class or method to be cut out for separate compilation with its own IP-XACT description.
Numbers 1 and 3 in the following list are relatively obvious, so we discuss only number 2.
IP-XACT is an IEEE standard for describing IP blocks and for automated configuration and integration of assemblies of IP blocks. All conformant documents will have the following basic titular attributes spirit:vendor, spirit:library, spirit:name, spirit:version. A document typically then represents one of:
Today, the predominant protocol for interblock communication is AXI in its various forms. A block with AXI interfaces should be accompanied with an XML description using the IP-XACT schema.
Separately-compiled modules will not share hardware resources (such as registers, ALUs or small RAMs) between them. Also, each will, in general, have its own (set of) bondout load/store port(s) for access to centralised resources such as DRAM.
We use the terms, module and IP block interchangably with the term FU (functional unit). An AFU is an application-specific functional unit. There is no technical disticintion between an FU and an AFU, but the built-in diosim simulator cannot always find suitable simulation models for AFUs whereas it is expected that all standard FUs, such as ALUs and SSRAMs have simulation models (sometimes automatically created by cvipgen.fs).
Restriction: A module for separate compilation by KiwiC cannot have free parameters at the moment, as would be used to statically set a dictionary maximum contents size for instance.![[*]](footnote.png) For example, a generic dictionary component [insert link here please] cannot be compiled, even though the basic data operations on it
are marked up as remotely callable with Kiwi.Remote() or otherwise.
The dictionary example fails for these reasons:
For example, a generic dictionary component [insert link here please] cannot be compiled, even though the basic data operations on it
are marked up as remotely callable with Kiwi.Remote() or otherwise.
The dictionary example fails for these reasons:
An FU (IP Block or AFU) may support more than one operation or more than one port that provides the same operation. Alternatively, an FU may be mirrored, meaning more than one instance can be created to provide more processing capacity. Certain FUs may never be mirrored, especially those holding state that cannot be replicated, such as a heapspace manager.
For management purposes, the methods provided by an FU are partitioned into method groups (MGRs). Each method group has a disjoint set of nets at the hardware level (except for directorate nets such as the clock and reset). Each method group has its own IP-XACT bus interface defined in the XML component definition and each bus interface (method group) has its own pair of XML files definining its bus abstraction and RTL bus interface. There may be a third file for each method group which describes its TLM bus interface signature
A method group corresponds to a physical bus. Only one method in a method group can be invoked at once, such as the read or write methods of on one port of a RAM.
TODO - in this release the general means of describing which methods are in which mgr is not fully implemented. It works as follows: Canned IP blocks, such as the SSRAMs, can have multiple methods per method group. These have been hand-crafted. Imported and exported IP blocks have exactly one method per methodgroup.
A component is mirrorable if all of its invoked methods have the mirrorable attribute.
There may be re-entry restrictions on which methods can be concurrently invoked, but low-level handshake can control these.
A pre-compiled IP block is described with two (or more) metainfo files in extended IP-XACT format. KiwiC will generate such files for each block compiled but they may also be provided from other sources, such as IP libraries or hand-crafted.
|
The IP-XACT standard schema provides all of the information needed for net-level structural IP block interconnection.
Beyond providing the block name and version number, it gives a full description of the net-level interface and any TLM interfaces in higher-level models. The precision of the implemented function is manifested by the bit-widths of the busses.
Hence the HPR System Integrator mode of compilation, illustrated below for the peered instances, is readily supported without extensions. Afterall, this is the primary use today for IP-XACT.
We currently do not support automatic selection of sub-assemblies based on non-functional parameters, such as area and energy, but method overloading within the API of a given block works. Also, we do not automatically partition a design for incremental compilation according to the scale of the blocks or other heuristics: instead [Kiwi.Remote()] attributes must be manually added.
Where a custom block is separately compiled for use in an incremental compilation project, it, generally, has a custom interface. Hence there are two IP-XACT documents associated with an incremental compilation step: a so-called `spirit:abstractionDefintion' that defines the interface and the `spirit:component' that defines the child component, making reference to the interface document and also other interfaces, such as management and services ports, also sported by the child.
The parent compilation will read in these documents. And further IP-XACT documents will be written to describe the parent block by the parent compilation.
A final document may ultimately be written by HPR System Integrator that is a `spirit:design' for the whole structure.
We use a squirrelling function, akin to the one used for C++ link editing, to generate an almost-human-readable kind name for the the interface. Alternatively, a kind name can be manually specified in the C# [Kiwi.Remote()] attribute.
The abstraction definition describes the transactional method names associated with the net-level ports. For instance, a child component might have three methods, such as read(a), write(a, d) and flush().
The default approach is that each method has dedicated handshake, argument and result nets (as in Bluespec). The default approach is not always suitable, especially for pre-existing IP blocks. For example, on a single-ported RAM the address bus will be shared between the read(a) and write(a, d) methods. A second example is a general trig block ALU that implements ten different trig functions (sin, cos, tanh, ...): the argument and result busses will be shared over each invokable opertion.
One way to achieve sharing of argument and result busses, while retaining the default approach where each function has dedicated nets, is to write in C# a shim with a single callable method around the bock's natural API and direct operations to this target. This simply requires adding one further, public, method to the component's C# class definition and making sure that all required calls pass through that method. An example is in Figure 5.
To exploit an existing component as a black box, the RTL result of synthesising the child component is not needed. The IP-XACT defining the child should be manually edited in the place where it refers to the RTL filename to instead refer to a manual implementation that uses the third-party component, such as the CAM on the NetFPGA board (see ... to be added).
Alternatively, going beyond the default method, so-called `meld' code can be provided that defines the transactional protocol at the net level.
TODO: define re-entrant synchronisation aspects and sharing of resources over entry points...
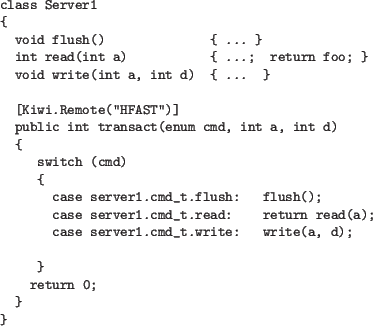 |
IP-XACT only provides about half of the information needed to import a hardware IP block for HLS so we use extensions for this purpose.
Additional information is needed for replication and schedulling of such blocks in an HLS flow.
A summary of the additional information needed is in Table 3.
We use the <spirit:VendorExtensions><hprls:...> namespace for our extensions. The schema is here: LINK MISSING.
There are two main module instantiation styles: IP blocks can be instantiated as peers or with hierarchy.
Each instanced block needs to have both a C# implementation and an RTL implementation packaged with an IP-XACT wrapper. The RTL and IP-XACT may have been generated by earlier runs of KiwiC or else may have been created by hand or have come from a third party. The C# version is required for two reasons: 1. so that the instantiating C# file will compile without a missing class error, and 2. so that the the system as a pure dotnet design in WD (workstation development) environment. Only a stub implementation (null method bodies) is needed for C# compilation to succeed. And for the dotnet run, only a high-level behavioural model is needed in the C# when the real implementation comes from elsewhere, such as when it is hardened IP like the NetFPGA CAM.
Peer interfacing requires both sides to import a shared interface declaration so they may be compiled separately at the C# stage, yet still communicate afterwards. This could be a TLM abstraction of a standard interface, such as an AXI variant, or it could be a custom application-specific interface. And a TLM2-style socket set might be used to falicitate the binding.
Peer instancing skeleton example:

Hierarchic instancing is where one C# file is compiled first and a second has an instance of it available during its own compilation.
Hierarchic instancing skeleton example:
![]()
KiwiC will be invoked several times in either of these coding styles and each run generate a set of output files. Each set consists typically of some RTL and/or SystemC files and an IP-XACT meta file describing the set.
In the peer instancing example, each of the three instantiated components is defined as a class that is itself marked up with the Kiwi.Remote() attribute. In the hierarchic example, the attribute is instead applied to the instance. Also, in the hierarchic example, the ALU instance may actually be placed outside the rendered containing RTL with additional top-level ports provided for wiring it up.
Note that the ALU in the hierarchic example might typically be stateless and hence replicatable. If so, its invokation will be completely on a par with the multiplier and divider instances also needed for method foo. The HLS binder will decide how many instances of it to make and the HLS scheduller will factor in the appropriate fixed pipelining delay or variable delay and handshake nets.
Kiwi defines that if any subsystem stops with an abend syndrome code, this must be passed up through parent modules to the substrate wrapper. And all modules must halt at that instant so PC values can be collected.
An example of glue logic being inserted by HPR System Integrator is when it must collect these abend syndromes and PC values from each instantiated module and combine them into a larger abend code and to halt the composite when any component abends.
In the peer instancing example, the KiwiC front end will invoke the HPR System Integrator function (§39) of the HPR library that underlies Kiwi.
The HPR System Integrator compiler takes a set of HPR VMs and generates SP_RTL constructs to wire up their ports following the VM instantiation pattern or an input IP-XACT document. It will instantiate protocol adaptors and glue logic based on pre-defined rules.
Please see SoC render part of the manual: Section 39.
HPR System Integrator supports:
Another example, at the moment, is that KiwiC generates HFAST load/store ports but the Zynq platform requires these to be adapted to AXI. This can either be done automatically by HPR System Integrator or by using the IP Integrator GUI within Vivado.
There are some examples in the standard distribution, such as primes and cuckoo cache.
Here's how to make a simple synchronous counter that produces a 32-bit net-level output.
using KiwiSystem; class Counter32
{
[Kiwi.OutputWordPort("counter")]
static int counter;
[Kiwi.HardwareEntryPoint()]
static int Main2()
{
while(true)
{
Kiwi.Pause();
counter = counter + 1;
}
}
}