Behavioural algorithm:
while (1)
{
wait (Start);
RA=A; RB=B; RC=0;
while(RA>0)
{
if odd(RA) RC=RC+RB;
RA = RA >> 1;
RB = RB << 1;
}
Ready = 1;
wait(!Start);
Ready = 0;
}
(Either HLS or hand coding can
give the illustrateddatapath
and sequencer structure:)
| 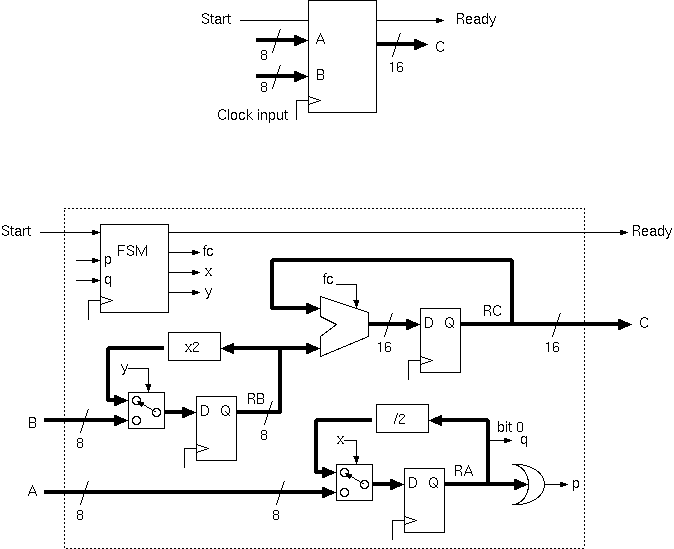 |
It is certainly not fully-pipelined, it goes busy for many cycles, depening on the log of the A input. The illustration shows a common design pattern consisting of a datapath and a sequencer. Booth's algorithm (see additional material) is faster, still using one adder but needing half the clock ticks.
Exercise: Write out the complete design, including sequencer, for the above multiplier, or that of Booth, or a long division unit, in Verilog or SystemC.
You may wish to dynamically swap the inputs over according to which has the lowest most-significant bit set.
For today's VLSI, for 32 bits, a fixed latency multiplier is typically used. This will have 2 or 3 clock cycles delay and be fully pipelined.
Fully-pipelined logic with fixed latency is easy to incorporate into static schedules, either by hand or with automated HLS tools. Recent email from Dr Mullins: At clock freq 500MHz, I see something like 13.5pJ for a 32-bit multiply (2-stage pipeline) in a 40nm low power (LP) silicon process. Its area is 8750um.
| 36: (C) 2012-17, DJ Greaves, University of Cambridge, Computer Laboratory. | |