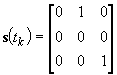|
|
 |
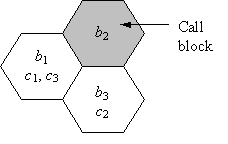
2.1.2 Centralised Non-measurement (CN)The systems in this quadrant depend less upon a priori knowledge but more upon current knowledge and hence the channel is assigned dynamically during network operation. The base stations are connected to a central controller where they obtain information relating to current interference and traffic conditions. The system assumes that the network is operating in a licensed band and that only same network co-channel and adjacent channel interference exists. Therefore, measurements are not performed since interference and traffic condition can be extracted via information concerning the channel usage of the base stations in the network. Since the interference and traffic conditions change during network operation, the base stations using this information can assign the channel more efficiently thereby adapting to traffic conditions and reducing call blocking. For example, consider the three cell network in Figure 2.1 with base stations B = {b1, b2, b3}, demand D = [2 1 1] and channel set C = {c1, c2, c3}, where C = |C|. Now consider the situation if the channel separation between neighbouring cells is changed from zero to one with other separations remaining the same as those in the example presented at the beginning of the Chapter 2 . This scenario does not have a solution (i.e. C<CMIN) and if FCA is used one of the base stations will experience call blocking with the previously specified D. For example, if c1 and c3 are assigned to b1 and c2 assigned to b3, b2 will not have a free channel and will experience a call block whenever a new call arrives. This is illustrated in Figure 2.12.
Figure 2.12: Call block in b2 using FCA for (C<CMIN). However, during network operation, not all the channels are used simultaneously, that is the traffic demand vector D(t) is a function of time t. Therefore, using DCA the assignment s(t) is also a function of time and changes according to D(t). Assume at time tk the traffic demand is D(tk)=[1 0 1] and the assignment s(tk) using the notation in (2.3) is (where channels are represented by columns and base stations by rows):
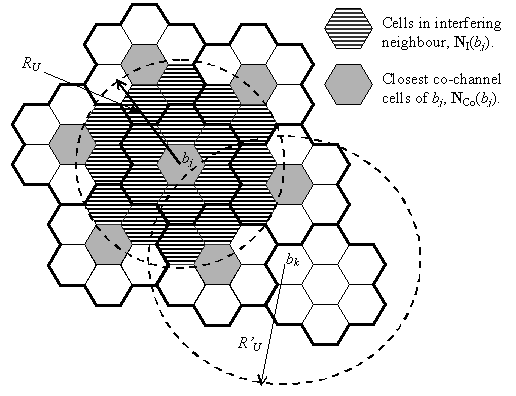
At time tk+1, there is a new call at b2, that is D(tk+1)=[1 1 1]. Now if b2 knows the channel usage of b1 and b3 using centralised information, it can assign c1 (i.e. s2,1(tk+1) = 1) to this new call and still conform to the compatibility matrix thereby admitting the call. This is in contrast to the FCA scenario described previously where a call in b2 would have been blocked. Assume at time tk+2 there is no call in b2 (i.e. s2,1(tk+2) = 0) and the traffic demand is changed to D(tk+2)=[1 0 2], centralised information will permit b3 to assign c1 to this new call (i.e. s3,1(tk+2) = 1). In the FCA scenario this new call at b3 will be blocked because it was designed for D=[2 1 1] not withstanding that the total traffic in D(tk+2) is actually smaller than that in D. Clearly, FCA is at a disadvantage since it is unable to adapt to small changes in traffic. Note that although b3 has a free channel at time tk+2 in the DCA scenario to service this new call, the call will still be blocked if no radio transceiver is available to support this channel. Therefore, it is possible for methods in this quadrant to adapt to fluctuations in traffic demand but at a cost of installing extra radio transceivers in each base station. Since no measurements are made, a call may still be blocked if a bad compatibility matrix (or one that uses soft constraints) or interference from another system (e.g. if the system operates in an unlicensed band) gives rise to a poor SNR, even if a free channel and radio transceiver is available. FCA is designed for high traffic demand because the solution s found is close to the optimum value with the assumption that all channels are occupied. Employing DCA in this quadrant will give a solution s(t) similar to that of an FCA technique using call ordering a (e.g. [19], [20], [21], [22] and [28]). However for DCA the call order a is determined by D(t), which may result in a poor local optimum solution. At high traffic, dj is high for all bjÎB and in (2.6) the degree of assignment difficulty DB(j) for the base stations becomes harder as less free channels are available causing the DCA to select poor channels leading to a poor solution. Therefore, at low to medium traffic, DCA may perform better than FCA, but at high traffic, FCA tends to perform better than DCA. The degree of centralisation is dependent upon the algorithm used. Full centralisation may have problems with scalability particularly if the algorithm requires frequent updates and a significant processing time. Consequently, a fully centralised method may be limited to small networks. There are many algorithms where the degree of centralisation includes only the base stations that fall within the reuse distance of base station j, (i.e. bj) that is base stations that would interfere with bj if any of them uses the same channel as bj. The set of base stations that fall within the reuse distance of bj (i.e. RU) are called the interfering neighbours NI(bj) of bj and are shown in Figure 2.13. Hence, a channel is free in bj if it is not used by base stations in NI(bj). Now define NCo(bj) as the set of base stations that are the nearest co-channel neighbours of bj – that is a channel can be used simultaneously in bj and NCo(bj).
Figure
2.13: Interfering
neighbours NI(bj)
and closest co-channel cells NCo(bj) Assume that each group of 7 distinct cells of the network shown in Figure 2.13 are connected to a base station controller (BSC) (each group of cells is outlined in bold). Although bj needs only to communicate with base stations in NI(bj), the BSC connected to bj (BSC j) needs to communicate with six other BSCs since the base stations in NI(bj) are connected to them. If base station k, namely bk has a reuse distance R’u (the reuse distance may not be the same for all cells) that includes base stations connected to BSC j falling within NI(bk), BSC j will also need to communicate with the BSC connected to bk. Let Bj={bm, bm+1, … bm+Nc} be the set of all base stations connected to BSC j. Hence, BSC i needs to communicate with BSC j if {Bj Ç NI(bl)}ÏÆ for blÎBi, where Æ is the null set. In order for two BSCs to communicate, they need to be either linked directly or connected to a main central controller that routes all signals between BSCs. Although, a central controller may be involved, centralisation up to the interfering neighbour is scalable since the amount of signalling is limited and less than that in a fully centralised system. The lesser amount of signalling also means shorter delays in assigning a channel but note that each assignment will not have channel usage knowledge of the entire network. 2.1.2.1 Centralisation up to the Interfering NeighbourCentralisation can be introduced into a network with a set of base stations B={b1, b2, … bB} using FCA to utilise the channels more efficiently. The so called nominal channels are a set of channels assigned to base station j using the FCA technique. If bj uses up all its nominal channels and a new call arrives, bj can still serve this call (if a radio transceiver is available) by borrowing a channel from one of its neighbouring base stations that has not used up all its nominal channels. This method is called Simple Channel Borrowing [31]. The channel borrowed by bj must not interfere with other base stations (i.e., it must conform to the compatibility matrix) and base stations in NI(bj) are prohibited from using it. The borrowed channel is said to be locked and this channel is unlocked when the call is completed (or is handed off to another base station). In light traffic, Simple Channel Borrowing performs better than pure FCA but in heavy traffic FCA performs better. In heavy traffic, channel borrowing becomes more frequent leading to excessive channel locking and a consequent increase in the blocking probability. The set of nominal channels can be divided into two subsets where one set can be borrowed while the other is used only by bj. This method is called Hybrid Channel Borrowing and it reduces the effect of excessive channel locking at high traffic demands [31]. When a channel is borrowed by bj, instead of locking all base stations in NI(bj), for a system using a sectored antenna, Borrowing with Directional Channel Locking (BDCL) [31] locks only the base stations in NI(bj) with antennas facing directly toward bj. This reduces the number of channel locks. A call using a borrowed channel can be reassigned to a nominal channel whenever one becomes available, thereby reducing the channel locking period. Channel borrowing is built upon FCA and therefore requires the a priori knowledge described previously, which will be time consuming to acquire and maintain in a large network. In some systems, the base station may be mobile and hence a priori knowledge is not available [39]. As described previously, DCA avoids going through the FCA process since all the channels in DCA are made available for use. A Simple DCA method [32] is to attach an ordered list of channels Cj to each base station (i.e. bjÎB) and whenever a call arrives at bj, the algorithm will pick a free channel that has the highest order in Cj. Once a channel is selected, bj will lock this channel preventing the base stations in NI(bj) from using it. For a bkÎNI(bj) the ordered list is arranged such that a high ordered channel in Ck is a low ordered channel in Cj and the base stations in NI(bj) and bj should have unique lists. A call using a lower ordered channel is reassigned to a higher ordered channel whenever the higher ordered channel is freed. The ordered list can also make use of a priori network information since more information will lead to a better channel allocation. In [33] a Geometric DCA is introduced that uses a priori information in the ordered list, where the set of channels C is divided into distinct groups {C1, C2, … CK}, where each group Cj is a subset of C and each group consists of an ordered list of channels (usually separated by cj,j so that they can be used in the same base station). Each base station say bj within a cluster is assigned a different channel group (e.g. Cj) and the size of the cluster Nc is |NI(bj)| + bj for the scenario with uniform traffic and a constant size cluster determined using the method described in Figure 2.3. Hence, the number of channel groups is Nc in uniform traffic. A unique channel group ordered list is assigned to each base station such that Cj is the highest priority group in bj and for any two base stations bj and bk, a cluster high priority group in bj is a low priority group in bk. Using additional a priori information improves the performance (e.g. blocking and dropping probabilities) compared to the Simple DCA at the expense of additional work off-line. The ordered channel list in Simple DCA and Geometric DCA are constructed prior to network operation and they remain static during network operation. Rather than having a static ordered channel list, a cost function can be used to dynamically order the channels. By giving a cost to each free channel, the algorithm will assign a free channel with the lowest cost and reassign a high cost channel currently in use to a lower cost channel when it becomes free. For example, in the Nanda-Goodman DCA [34], the cost of using a channel by bj is the number of base stations in NI(bj) that would be locked from this channel (excluding those base stations bkÎNI(bj) that are already locked from this channel owing to this channel being used by a base station in NI(bk)). Note that this cost function promotes channel packing. In [35], a Two-Step Dynamic-Priority DCA (TSDP) algorithm is proposed whereby a channel can be designated either primary or secondary, where primary channels have a higher priority than secondary channels. A channel in bj is a primary channel if the number of base stations in NCo(bj), using this channel, is above a predefined threshold, otherwise it is a secondary channel. All channels start off as secondary channels and are ordered according to the Nanda-Goodman cost function until they become a primary channel. Here channels used by a greater number of base stations in NCo(bj) have a higher priority and in a tie, the channel that is freed in more base stations in NCo(bj) has a higher priority. The primary channel is introduced in TSDP to encourage higher channel packing giving a better performance (in terms of call blocking and dropping probabilities) than Nanda-Goodman and Geometric DCAs. In [36], primary channels are assigned a priori and the cost function is the same as that in Nanda-Goodman but with an additional cost to the base station that uses a non-primary channel. In a Locally Optimised Dynamic Assignment (LODA) [31] the cost encourages packing of channels such that channels are reused as closely as possible. An aggressive DCA is used in [32] where the channels in Cj are divided into primary C1j and secondary C2j groups, where C1j are the highest ordered channels in Cj and have a higher priority than those in C2j. Primary channels in Cj are owned by bj, while channels in C2j can be borrowed by bj. Whenever a channel is released, the owner of this channel (i.e. the base station where this channel is a primary channel) is given priority to acquire it over other base stations. In the aggressive DCA, when base station bj runs out of free channel it can take a channel from another base station bk in NI(bj) (e.g. channels owned by bj) and force bk to seek another channel. However, this aggressive channel acquisition is applied only to important calls (i.e. handoff) and the channel is acquired if it doesn’t cause too many calls in NI(bj) to seek another channel, which may lead to call termination. Aggressive DCA improves call dropping probability and the rearrangement of channels within the network causes the base stations to use their own channels, thereby further reducing the channel locking period. The methods described here require the base station bj to communicate with base stations in NI(bj) to obtain the channel usage of these base stations. This can be done in the backbone network (usually wired) using a search or an update method [37]. In a search method , the requesting base station, bj announces that it wants a channel and all the base stations in NI(bj) will respond with a list of channels that they are not using. The requesting base station can construct a list of free channels from these lists. The request is time-stamped so that a bkÎNI(bj) who is also searching for a channel will defer its response to bj until bk has finished searching for a channel for itself, if bj’s request has a later time-stamp than bk’s time-stamp. In an update method , each base station maintains a list of free channels. The requesting base station bj selects a free channel from this list and requests permission to use this channel from all the base stations in NI(bj). If all the base stations in NI(bj) grant the use of this channel, bj will select this channel, otherwise bj will consider another channel in its list. Whenever bj acquires or releases a channel it will inform all the base stations in NI(bj) so that they can update their list of free channels. Each request is also time-stamped in the update method so that a bkÎ NI(bj) will reject a channel request by bj if bk is also requesting the same channel and has an earlier time-stamp. The search method doesn’t maintain a list of free channel and hence channel reassignment is difficult. Channel reassignment is easy to implement in the update method but it requires more signalling as each bj needs to inform all the base station in NI(bj) of its channel usage. Categorising the channels into primary and secondary as in the Aggressive DCA and TSDP can reduce the amount of signalling in an update scheme. Here, base station bj acquires a primary channel whenever it is free and if a secondary channel is required, bj goes into the update process [37]. Hence signalling is only required for secondary channels. The signalling is reduced further in the Advanced Update scheme introduced in [37] whereby during the update process, bj needs only to seek permission from the base station k, where the free channel bj seeks is a primary channel of bk and bkÎNI(bj). In the search method, the first base station to send a request gets to pick a channel from a list of free channels. In the update method, the first base station to select a contention free channel gets to use it. In high traffic, there are less contention free channels and the update method takes longer to find a channel than the search method. Based on this argument, [38] proposes an UpdateSearch scheme that combines both the update and the search method. The UpdateSearch scheme has two phases, where the first phase uses an update method while the second phase uses a search method. This method begins with the first phase (update method) and moves into the second phase if the first phase fails (e.g. after a few trials). As the update method is more likely to fail in high traffic, this method will move into the search method that has a lower and bounded time to find a channel. 2.1.2.2 Fully Centralised SystemA fully centralised DCA has global knowledge of the network, and knowing the channel usage of each base station, each call arrival can be assigned a channel such that the overall assignment s(t) approaches the optimal solution. Given that FCA by itself is a NP-complete problem, finding the best channel assignment during network operation demands high processing resources and may be limited to small networks only. Hopfield Neural Networks can be implemented using parallel processors as proposed in [40] for a fully centralised DCA. Here, each base station (e.g. bj) has an energy E(sj(t)) that is a function of the channel assignment of bj (i.e. sj(t) = {sj,1, sj,2, … sj,C}, where sj(t) Î s(t)) and s(t-1). E(sj(t)) is defined such that it conforms to the compatibility matrix, satisfies the traffic demand at time t for bj, promotes channel packing, favours assignments that follow a reuse pattern (similar to Figure 2.3) and tries to maintain the previous assignment sj(t-1) so that less channels are reassigned. E(sj(t)) also balances the importance of each factor by assigning weights to them, and for each call arrival it converges quickly to the first sub-optimal value giving its corresponding channel assignment sj(t). Although E(sj(t)) settles upon the first sub-optimal value, it performs better than DCA with centralisation up to the interference neighbourhood. An additional factor that encourages the network to reserve channels for handoff is introduced in E(sj(t)) in [41] in order to improve the dropping probability. The handoff constraint is a soft constraint since it is handled in E(sj(t)) and hence produces a better balance between call blocking and call dropping probabilities compared to [40] and methods that reserve a number of channels solely for handoff.
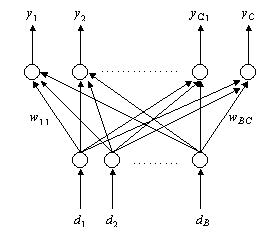
Figure 2.14: Self-organising neural network, SONN Consider the neural network in Figure 2.14, with input D={d1, d2, … dB} and output Y={y1, y2, … yC}. Each input dj is weighted by multiplication with wj,k before connecting to output yk. Each output is a summation function of the weighted inputs. For a specific input D’, the output node that is “closest” (user specific definition) to the input will produce a maximum output yj*. The weights connected to the winning node yj* are changed so that yj* will be “closer” to D’. In a Self-Organising Neural Network (SONN) , the neighbouring nodes YNj*ÎY of the winning node yj* are also allowed to change their weights. In [26], a SONN as in Figure 2.14 is proposed for use in DCA where the inputs are the traffic demand vector D(t) and the output yk is the cost of using channel ckÎC. The weights wj,k represents the probability that channel j is assigned to base station k in a similar manner to the assignment vector in (2.3) and each output represents the cost of using the channels. The cost is proportional to the degree each channel violates the compatibility matrix (i.e. a soft constraint). The “closeness” in this model is the cost. The weights are probabilities and are transformed into an actual assignment s(t) in the form of (2.3) using a HNN with an appropriate energy function. This method was proposed for use in DCA. However, it is tested in FCA and its performance is worse than one using a HNN with hill climbing as described in the same publication [26]. If no free channel is available in bj, a new call can be serviced by reassigning a call in another base station so that a channel is freed in bj. In a fully centralised system, channel reassignment can be made more aggressive such that a call is only blocked if no channel reassignment is possible in the entire network to free a channel. The idealised method would reassign the channels such that only the minimum number of channels CMIN is used at all times. This idealised method is called Maximum Packing , (MP) [42] and it is the optimal DCA strategy among the Non-Measurement channel allocation methods. However, the complexity of the MP algorithm is high, there is a large amount of communication with all the base stations and finding CMIN is NP-hard. Hence, implementing MP is difficult and is practical only for small networks. In MAXAVAIL [43], each call arrival is assigned a free channel such that the selected channel leaves the maximum number of free channels for the entire network. A call is blocked if there is no free channel in the base station when a new call arrives. This requires the system to go through every free channel in the base station and compute the total number of free channels in every base station if this channel is used. Although MAXAVAIL tries to maximise the number of free channels, there is no way of telling whether CMIN channels are in use at all times. A more aggressive algorithm ReMax1 [43] applies channel reassignment and MAXAVAIL. In ReMax1, if a call arrives at bj and no free channel is available, it will consider all the channels not in use by bj that will be interfered with exactly one on going call, if it was used. Let L1 be the list of calls using these channels. ReMax1 applies MAXAVAIL to each call in L1 as if it were a “new call arrival” at the corresponding base station. The call in L1 that returns the highest number of free channels is reassigned so that the channel can be used by bj to service its new call arrival. A call is blocked in ReMax1 if every call in L1 is blocked. If a call is blocked using ReMax1, a more aggressive method ReMax2 will use ReMax1 on every call in L1 instead of MAXAVAIL. The reassignment can be taken to higher levels (e.g. ReMax3, etc.) but the complexity of doing so increases exponentially. MAXAVAIL closely implements MP and is claimed to be one of the best strategies in this class [44], however the amount of computation for each assignment is high. Most DCA methods consider the immediate cost of assigning a channel and ignore the long-term cost (immediate and cumulative future cost). In Reinforcement Learning [17], an agent learns a policy (e.g. a DCA strategy) that minimizes the expected long-term cost by repeatedly interacting with the environment. If a system can be modelled in a state-space diagram, the expected long-term cost is calculated using the cost at each possible state and the probabilities of transiting to each state. This information is usually not available. Q-learning which is a subset of Reinforcement Learning that does not require this information but manages to estimate the cost by learning. In [44] a DCA method using Q-learning is proposed, where a state is a call arrival in a base station and the cost encourages high channel packing in a similar way to the one proposed in LODA [31]. As the network operates, the DCA method will eventually converge to a policy that will select a channel for each call such that the expected long-term cost is minimized. This method requires less computation, and it is shown in [44] to perform as well as MAXAVAIL. An MP implementation called the Simplified Maximum Packing method is proposed in [45]. In this method, each cell is given a set of primary channels in a similar manner to the channel borrowing methods. If no primary and non-primary (channels not used within the interference neighbourhood) channels are available to service a call, a method similar to ReMax1 is used to reassign an existing call to free a channel. Here the lowest cost channel is the highest packed channel (i.e. the co-channel base stations are as close as possible). Channel reassignment is also performed when a call is completed, where the highest cost channel is reassigned to a newly freed lower cost channel.
|