Figure 2b
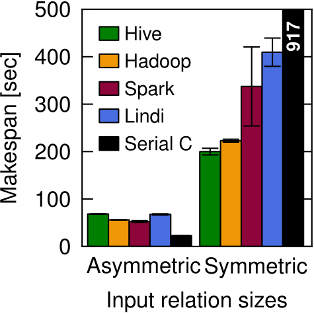
Figure 2b (page 2) shows that the performance of different data processing systems varies significantly for an I/O-intensive join between two data sets.
For the asymmetric join, a simple serial C implementation is fastest, while a symmetric join is best executed in a distributed system with parallel I/O.
Figure 2b
Under construction: the links in the description below are currently broken; we will fix this shortly when we make the first Musketeer release.
If you are interested in being notified when the data appears,
please join our
musketeer-announce mailing list.
Thanks for your patience.
-- The Musketeer team.
Experimental setup
This experiment was executed on our small dedicated cluster of seven machines.
We used two different input data sets:
- Asymmetric: the 4.8M vertices joined against the 69M edges of the LiveJournal graph.
- Symmetric: two uniformly randomly generated sets of integers (generated using
gen_join_symmetric.sh) of 39M rows each.
We also tuned the following system-specific configuration parameters:
- Hive: Set the
hive.input.formatvariable toHiveInputFormatinstead of the defaultCombinedHiveInputFormatclass. The latter merges several input splits and hence reduces the total number of map tasks, which limits parallelism and, in this case, is detrimental. This change improved Hive's performance by over 5x. - Hadoop: none.
- Spark: set the
parallelismparameter to 128 (other values performed worse). - Lindi: used our HDFS connector script to load the input splits before execution. The input was also split .
- Serial C: used our HDFS connector script to load the input data before execution.
Result data set
The raw results for this experiment are available here.
To plot Figure 2b, run the following command:
experiments/plotting_scripts$ python plot_join_barchart.py ../query_proc/data.csv HiveOptimized Hive MusketeerHadoop Hadoop Spark128Parallelism Spark Naiad Lindi MusketeerWildCherry "Serial C" join-motiv-makespan.pdf
The graph will be in join-motiv-makespan.pdf.