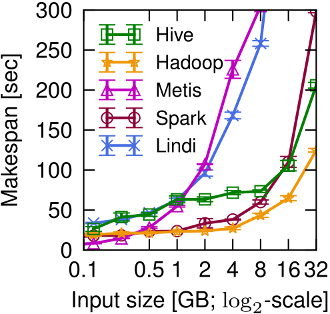
Figure 2a
Figure 2a (page 2) shows that different data processing systems see wildly different performance even on a simple string processing workload.
At small data sizes, low-overhead single-machine systems (e.g. Metis) perform best, while at larger scale, the parallel I/O of distributed systems offers benefit over their overheads (although some distributed approaches, e.g. Lindi, scale less well than others).
Figure 2a
Under construction: the links in the description below are currently broken; we will fix this shortly when we make the first Musketeer release.
If you are interested in being notified when the data appears,
please join our
musketeer-announce mailing list.
Thanks for your patience.
-- The Musketeer team.
Experimental setup
This experiment was executed on our small dedicated cluster of seven machines.
The input data set was a two-column ASCII table, generated using gen_project.sh,
with data sizes varying between 128 MB and 32 GB.
We also tuned the following system-specific configuration parameters:
- Hive: Set the
hive.input.formatvariable toHiveInputFormatinstead of the defaultCombinedHiveInputFormatclass. The latter merges several input splits and hence reduces the total number of map tasks, which limits parallelism and, in this case, is detrimental. This change improved Hive's performance by over 5x. - Hadoop: none.
- Metis: used our HDFS connector script to load the input data before execution.
- Spark: none.
- Lindi: used our HDFS connector script to load the input splits before execution. The input was also split
Result data set
The raw results for this experiment are available here.
To plot Figure 2a, run the following command:
experiments/plotting_scripts$ python plot_project_linechart.py ../op_benchmarks/stat/combined_project.stat project-motiv-makespan
The graph will be in project-motiv-makespan.pdf.