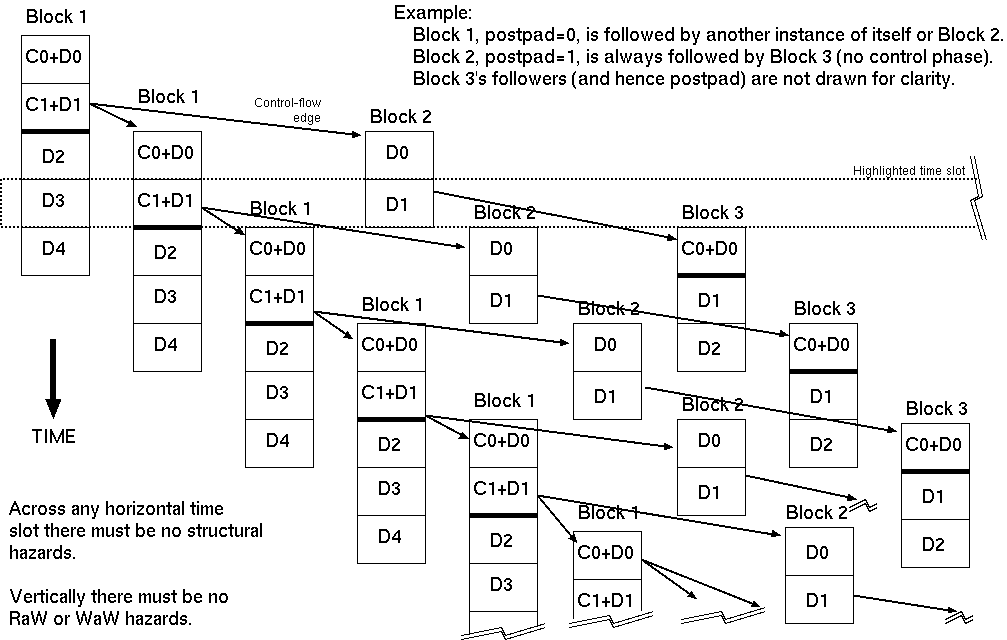
Fragment of an example inter-block initiation and hazard graph.
Multiple basic blocks, even from one thread, will be executing at once, owing to pipelining.
Frequently, an inner loop consists of one basic block repeated, and so it is competing with itself for structural resources and data hazards. This is loop pipelining. Where an outer loop is requested to be pipelined, all loops inside must be pipelined.
Each time offset in a block's schedule needs to be checked for structural hazards against the resource use of all other blocks that are potentially running at the same time.
Every block has its own static schedule of determined length.
The early part of the schedule generally contains control-flow predicate computation to determine which block will run next. This can be null if the block is the initialisation code for a subsequent loop (i.e. the basic block ends on a branch destination rather than on a conditional branch).
The later part of the block contains data reads, data writes and ALU computations. Data operations can also occur in the control phase but when resources are tight (typically memory read bandwidth) the control work should be given higher schedulling priority and hence remain at the top of the schedule.
Per thread there will be at most one control section running at any one time. But there can be a number of data sections from successors and from predecessors still running.
The interblock schedule problem has exponential growth properties with base equal to the average control-flow fan out, but only a finite part needs to be considered governed by the maximal block length.
As well as avoiding structural hazards, the schedule must contain no RaW or WaW hazards. So a block must read a datum at a point in its schedule after any earlier block that might be running has written it. Or if at the same time, forwarding logic must be synthesised.
It may be necessary to add a `postpad' to relax the schedule. This is a delay beyond what is needed by the control flow predicate computation before following the control flow arc. This introduces extra space in the global schedule allowing more time and hence generally requiring fewer FUs.
In the highlighted time slot in the diagram, the D3 operations of the first block are concurrent with the control and data C1+D1 operations of a later copy of itself when it has looped back or with the D1 phase of Block 2 if exited from its tight loop.
Observing sequential consistency imposes a further constraint on schedulling order: for certain blocks, the order of of operations must be (partially) respected.
For instance, in a shared memory, where a packet is being stored and then signalled ready with a write to a flag or pointer in the same RAM, the signalling operation must be kept last. (This is not a WaW hazard since the writes are to different addresses in the RAM.)
Observing these limits typically results in an expansion of the overall schedule.
| 19: (C) 2012-18, DJ Greaves, University of Cambridge, Computer Laboratory. |