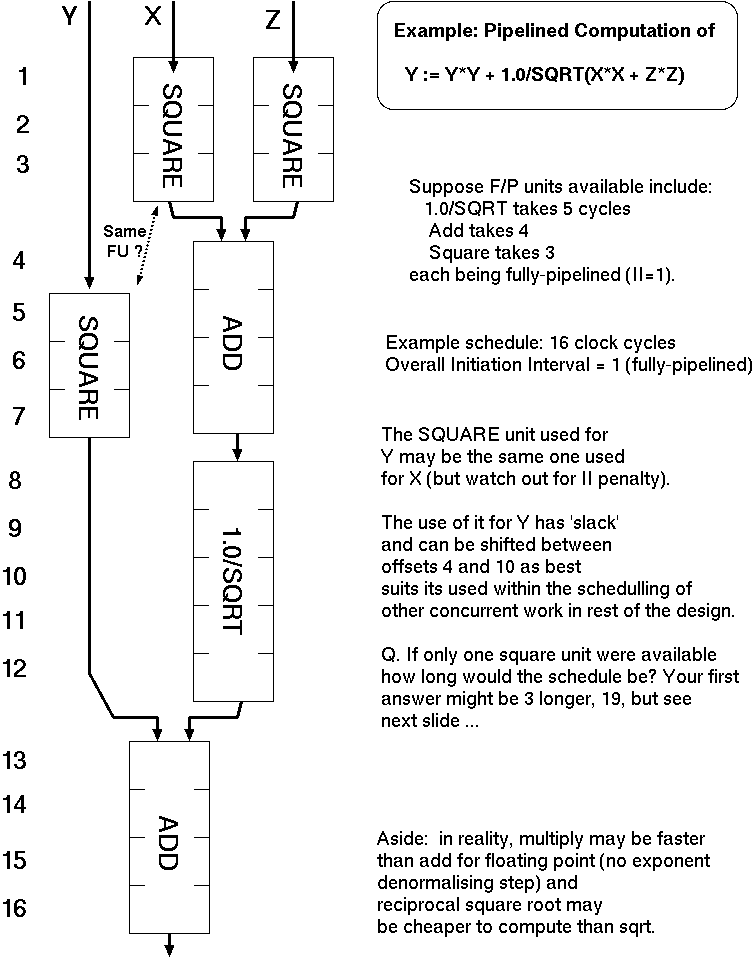
Example static schedule for a basic block containing a single assignment.
After some amount of loop unrolling, we have an expanded control-flow graph that has larger basic blocks than in the original HLL program.
In classical HLS, each basic block of the expanded graph is given a time-domain static scheudle.
The diagram we have just considered was a little naive: it was constructed assuming that the FUs were non-pipelined (i.e. their II was the same as their latency). Non-pipelined versions of some kinds of FU are more compact (less silicon area) than pipelined equivalents, so they do crop up. But we were told our floating-point FUs had II=1.
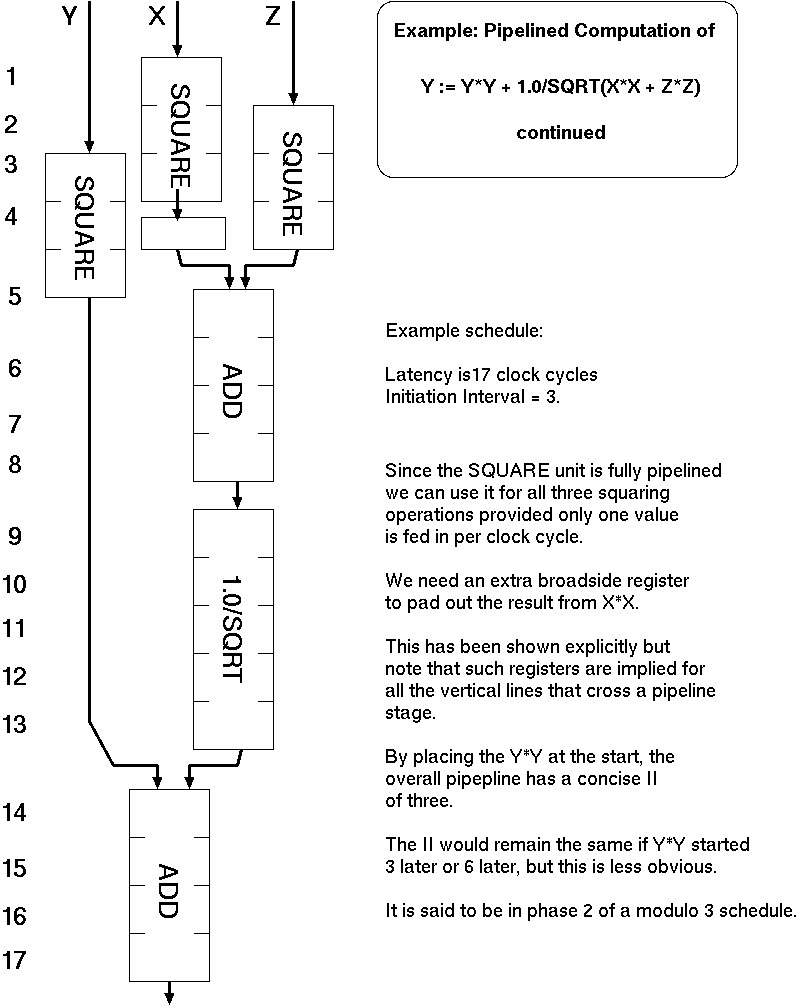
Our new design uses only one SQUARE unit at the expense of latency being one higher. II is often more critical than latency for HLS, and our II is only 3.
A good heuristic for schedulling is to start the operations which have the largest processing delay as early as possible. This is called a list schedule. But integer linear programming packages are often used to find an optimum schedule and resource use trade off.
Our example generated only one output.
A basic block schedule typically contains multiple assignments, with sub-expressions and functional units being reused in the time domain throughout the schedule and shared between output assignments.
To avoid RaW hazards within one basic block, all reads to a variable or memory location must be schedulled before all writes to the same.
The name alias problem means we must be conservative in this analysis when considering whether arrays subscripts are equal. This is `undecidable' in general theory, but often doable in practice. Indeed may subscript expressions will be simple functions of loop `induction variables' whose pattern we need to understand for high performance.
| 18: (C) 2012-18, DJ Greaves, University of Cambridge, Computer Laboratory. |