The work on CBT encouraged others to try to improve on its limitations while keeping the good properties of shared trees, and Sparse-Mode PIM was one result. The equivalent of a CBT Core is called a Rendezvous Point (RP) in PIM, but it largely serves the same purpose.
When a sender starts sending, irrespective of whether it is a member or not, its local router receives the packets and maps the group address to the address of the RP. It then encapsulates each packet in another IP packet (imagine putting one letter inside another differently addressed envelope) and sends it unicast directly to the RP.
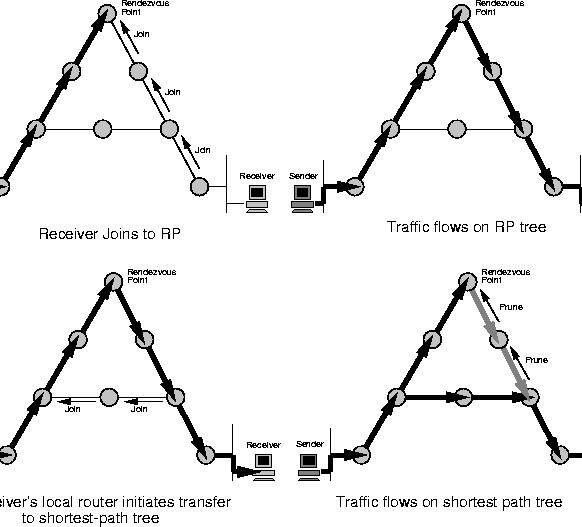
When a receiver joins the group, its local router initiates a Join message that travels hop-by-hop to the RP instantiating forwarding state for the group. However, this state is unidirectional state - it can only be used by packets flowing from the RP towards the receiver, and not for packets to flow back up the tree towards the RP. Data from senders is de-encapsulated at the RP and flows down the shared-tree to all the receivers.
The important advance that SM-PIM made over CBT was to realize that discovering who the senders are could be separated from building efficient trees from those senders to receivers.
Thus SM-PIM unidirectional trees are not terribly good distribution trees, but do start data flowing to the receivers. Once this data is flowing, a receiver's local router can then initiate a transfer from the shared tree to a shortest-path tree by sending a source-specific join message towards the source, as shown in figure 3.2. When data starts to arrive along the shortest-path tree, a prune message can be sent back up the shared tree towards the source to avoid getting the traffic twice.
Unlike other shortest-path tree protocols such as DVMRP and DM-PIM where prune state exists everywhere there are no receivers, with SM-PIM, source-specific state only exists on the shortest-path tree. Also low bandwidth sources such as those sending RTCP receiver reports do not trigger the transfer to a shortest path tree, which further helps scaling by eliminating unnecessary source-specific state.
Because SM-PIM can optimise its distribution trees after formation, it is less critically dependent on the RP location than CBT is on the Core location. Hence the primary requirement for choosing an RP is load-balancing. To perform multicast-group to RP mapping, SM-PIM pre-distributes a list of candidates to be RPs to all routers. When a router needs to perform this mapping, it uses a special hash function to hash the group address into the list of candidate RPs to decide the actual RP to join. Except in exceptional failure circumstances, all the routers within the domain will perform the same hash, and come up with the same choice of RP. The RP may or may not be in an optimal location, but this is offset by the ability to switch to a shortest path tree.
The dependence on this hash function and the requirement to achieve convergence on a list of candidate RPs does however limit the scaling of SM-PIM. As a result, it is also best deployed within a domain, although the size of such a domain may be quite large.