

|
ArchitectureWe are currently designing and constructing a privacy-perserving architecture to gather data from people's deployments of energy monitoring systems, such as the one we have installed in the Computer Lab. These multiple data sources can then be combined to improve community energy use. To produce accurate reports on personal energy use, it is necessary to track a users location, for example to calculate their energy use whilst commuting, at work, as well as at home. This requires personal data, and it is important to allow only reputable parties to use this information, and only for the applications the user allows. In this case, we want to allow the university to calculate our energy use as accurately as possible, yet deny data that the university does not require, and ensure the university is only using this data for this application. Our solution is to use a 'personal container' architecture where personal data is stored in user-specific servers, through which the university requests access to a subset of that data which users can accept or deny, and identify exactly what is being accessed. Using a personal container style datastore allows us to access multiple streams of data, the majority of which already exist, to accurately compute a personal energy footprint. For example, a user may already generate a large amount of location history throughout their online presence - Foursquare check-ins, geotagged photos and Tweets, Facebook events, Google latitude updates and sport or health based tracking apps for example. The personal container also allows simple addition of data sources directly, such as a home energy monitor, or high accuracy location tracking mobile phone application. 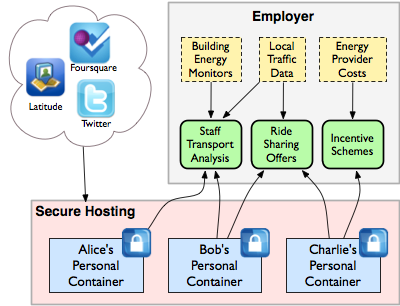
In this system, the personal containers are stored seperately from the employer, therefore the users can fill the containers with a lot of personal data, safe in the knowledge that the employer can only acces the subset which it has requested and been allowed to use. (8am to 10am location information on weekedays only to calculate commuting information for example.) This data can then be aggregated with publicly available data (e.g. local traffic data and energy costs) and building monitors. The result is a series of schemes such as optimising transport, ride sharing, incentives to cut costs, that users can choose to take advantage of, without sacrificing too much privacy. PrototypeWe are currently experimenting with the Locker Project platform, a personal container written in Node.js, which provides not only a data store, but also an infrastructure to create applications that interact with the stored data. Getting data into Locker is handled by connectors, which once setup via OAuth or other authentication can handle downloading and storing historical data, as well as mirroring the most recent. For more information about our locker implementation, see Locker Setup>. We are also liaising with project partners in the Horizion Institute who have created more self contained location tracking and personal energy monitoring aparatus. |