The raw results obtained from the various devices are presented first, then the results from a range of experiments performed using the processor node and devices in a variety of configurations.
When capturing live video (e.g. 768 x 288 pixels per field,
50 fields per second for PAL sources![]() ) at 24 bits per pixel, each scan
line of pixel data is captured in
) at 24 bits per pixel, each scan
line of pixel data is captured in  . In this mode, digital
pixel data is being generated by the ATM camera at a sustained rate of
265Mbps, peaking at over 288Mbps. The video FIFOs on the
ATM camera are capable of holding an entire frame which may then be
transmitted as back to back cells with only a small gap between frames
waiting for the next vertical sync pulse. Without taking into account
protocol overheads, it is clear that the ATM camera can easily
saturate a 160Mbps port on the switch fabric used in the DAN
demonstrator.
. In this mode, digital
pixel data is being generated by the ATM camera at a sustained rate of
265Mbps, peaking at over 288Mbps. The video FIFOs on the
ATM camera are capable of holding an entire frame which may then be
transmitted as back to back cells with only a small gap between frames
waiting for the next vertical sync pulse. Without taking into account
protocol overheads, it is clear that the ATM camera can easily
saturate a 160Mbps port on the switch fabric used in the DAN
demonstrator.
Using the video FIFOs on the version 2 camera, constant bit rate video streams between 1 and 80Mbps have been generated. For example, a 352x288 pixel image in 16 bits per pixel, 25 fps generates 88Mbps of video averaged over a scan line. The frame buffer enables this to be smoothed to a continuous rate of 41Mbps by inserting gaps between PDUs.
This data can be carried through the interconnect and has been shown not to adversely interfere with cache line traffic (see section 4.6.2).
The major use of the Audio/DSP node has been as a source and sink of audio rather than as a stream processor. Interoperability tests with Sun and HP workstations using various encodings were performed by recording the data from one system and replaying on the other. Simultaneous capture and replay by the audio node was also demonstrated. When used in its role as an audio source and sink the current software always runs the CODEC at 48kHz sample rate, and the DSP either sub-samples on capture or interpolates on replay to provide lower sampling rates. This enables multiple streams to be supported at different qualities, and has been found useful for jitter removal.
A second test was used to stress the DAN interface with the node in its DSP configuration. A virtual circuit was created across the DAN from the DSP node's transmit system to its receive buffer. The loop was completed by instructing the DSP to transmit on this circuit any cells that were received. Once a single cell was injected into this loop the ability of the DSP to perform null processing on a stream at the full interconnect speed was demonstrated by observing that the DSP transmitted a cell in every cell time. Thus, the DSP node could be used to log simple statistics on data passing though it.
Software emulation of the framestore has been used to enable the demonstration of the DAN and experimentation with various levels of framestore functionality. Unfortunately, the performance of the emulation running on the DECStation has been limited by the speed at which it can service its simple ATM interface. However, it is still capable of sinking over 15Mbps of 8bit RGB video into up to 16 overlapping, arbitrary shaped windows. The hardware version is designed to be able to sink video at the full interconnect rate.
An early demonstration of the DAN used the ATM camera and framestore to provide an emulation of the Pandora's Box based multimedia workstation [\bf\protect\citenameHopper90]. This enabled interworking with the multimedia infrastructure at both the Computer Laboratory and with Olivetti Research Ltd.
In this configuration, the DECStation was used as a highly intelligent frame buffer, and ran a complete X-server over the Wanda microkernel. The Pandora extensions were built into the X Server allowing unmodified Pandora applications to talk to the machine as though it were a genuine Pandora's Box. A separate daemon interpreted the Pandora control protocol intended for the Box and generated the correct requests to the DAN devices in order to create the required audio and video streams.
Local video and audio streams were able to use the native DAN formats between the camera and the framestore, in particular allowing larger colour video streams to be displayed. However, remote streams were transformed to conform to the Pandora protocols. This format conversion was performed using one of the processor nodes on the DAN.
Using this configuration, the DAN workstation was shown to interwork with standard Pandora's boxes allowing use of all of the normal video conferencing and video mail applications, at times handling up to 20 video streams simultaneously.
This configuration was found to be unsatisfactory as it was not possible to maintain application quality of service through the shared X server, not least because it is difficult to identify and partition the resources used by each application.
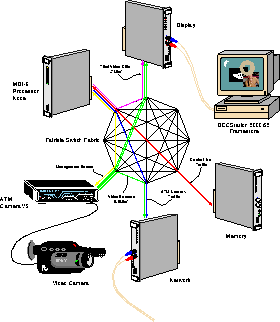
Figure 4: The experimental configuration
A complete demonstration system was constructed using the devices described above. A number of overlapping video windows from different sources were displayed on the framestore. To test the clipping algorithm in the framestore, one of these was a circular window with a hole in the middle through which two other windows could be seen.
A software library was written for the processor node which allowed clients to make use of the write-only virtual display capability of the framestore. Each client uses X-like primitives to render its own windows directly into the framestore, removing the need for an X server in the display datapath.
The various streams shown in figure 4 are as follows:
As in all other experiments, cache line service times were unaffected by the presence of the other streams.
The main observations made with the CPU node were to explore the practicality of using the ATM based interconnect for cache traffic. Comparison with studies of cache behaviour reported by other authors [\bf\protect\citenamePrzybylski88][\bf\protect\citenameAgarwal93][\bf\protect\citenameAgarwal86][\bf\protect\citenameHill88][\bf\protect\citenameSmith87][\bf\protect\citenameSmith82] showed that the example loads used in these experiments were realistic.
Further experiments were performed to observe the effects on the cache traffic for interfering data streams.
Measurements were taken of the mean cache-miss service time for four
states of the CPU node. The first was taken for the operating system
startup and execution of a PAL compiler; this test has approximately
38% of cache fetches also being flushes. The second measurement was
taken some time later with the CPU node running no user processes but
being ``pinged''![]() at one second intervals for about a minute; this has about
20% flush-and-read requests. The final two tests were made with the
cache being ``thrashed'' for twenty seconds, causing either continuous
read requests or continuous flush-and-read requests. Each test was
performed a number of times, giving repeatable results which are
summarised in table 1. In this experiment the fabric was
clocked at 15MHz, giving a cell frame time of
at one second intervals for about a minute; this has about
20% flush-and-read requests. The final two tests were made with the
cache being ``thrashed'' for twenty seconds, causing either continuous
read requests or continuous flush-and-read requests. Each test was
performed a number of times, giving repeatable results which are
summarised in table 1. In this experiment the fabric was
clocked at 15MHz, giving a cell frame time of 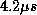 .
.

Table 1: Mean Memory Service Time
The hardware tests were performed using the debug monitor to access
memory, and by capturing the behaviour using a logic analyser. Using
this setup it was not possible to accurately measure the small
resynchronisation times![]() for stopping and restarting the CPU on top of that
observed for the request-reply operation.
for stopping and restarting the CPU on top of that
observed for the request-reply operation.
The ``thrash'' tests were performed by disabling interrupts on the CPU
node and putting it into a loop referencing three locations that were
co-resident in the cache. If this loop is set just to read from the
locations then every time there will be a miss because of the LRU
replacement policy. Similarly, writing the locations will make
the lines dirty and force both a flush and a read on every access.
This allows the time for the two basic operations of ``read cache
line'' and ``flush and read cache line'' to be measured. In the software
based server the large difference between the two is caused by
the need to copy the data from the network cell buffer into
the main memory. Access to the cell buffers is
slow (observed at 700ns per word for an earlier version of the port
controller [\bf\protect\citenameHayter92]) and the extra 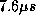 taken by the
write basically consists of nine reads of the buffer (the address and
8 data words) and the eight writes to main memory. The
hardware version writes the data into memory as it arrives from the
DAN and therefore does not show any difference between the two cases.
taken by the
write basically consists of nine reads of the buffer (the address and
8 data words) and the eight writes to main memory. The
hardware version writes the data into memory as it arrives from the
DAN and therefore does not show any difference between the two cases.
The service times observed are very slow compared to most real systems. There are two factors which cause this: the use of software for the memory server, and the speed of the interconnect. The hardware server experiment shows that it is possible to reduce the overhead to the two cell times required for a request cell followed by a reply cell. The use of request-reply with fixed-size cells will always impose a penalty over buses or interconnects where the request consists solely of the address. However, this penalty is reduced in the DAN by the ability to flush and request in the same cell.
Table 2 shows the read and flush times for some of the workstations used by the Systems Research Group in Cambridge. Note that the write time in all of these is only the time taken for data to be written, for flush-and-read the two times should be added. The times shown are for 32 byte cache lines and are the best case times (for the DS 5000/25 which uses 16 byte lines this was calculated as a single setup delay followed by 8 word accesses).
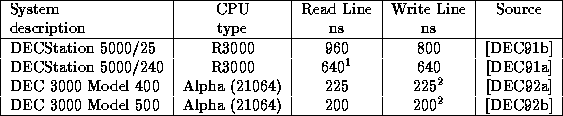
Table 2: Cache Line Service Times for Workstations
Clearly the times on these systems are much faster than those observed on the DAN demonstrator. However, the low end workstation is only just over eight times faster than the hardware memory server (four for flush-and-read); by moving to a 32 bit wide path and using an ASIC to allow a higher rate switch fabric, this performance is achievable on a DAN. The comparison with the Alpha workstations is a little unfair since these use a 32 byte wide memory bus and are aggressively optimised.
The DAN is intended to support real-time multimedia traffic in addition to the memory service traffic. Since it will be an important part of a real system the effect of competing streams on memory service time was studied. The implementation of the demonstrator is based on a crossbar switch element, so traffic was generated contending for the same crossbar output as the memory server. This traffic was marked so that it was discarded by the hardware of the memory server with no performance impact.
The interference traffic used came from both an ATM camera video
source and from a traffic generator. In general the
experiments![]() showed the effects of the conflicting stream on the
cache service time was mainly influenced by the scheduling strategy of
the interconnect. For example in one experiment using video traffic
with a peak rate of 54Mbps at the same priority as
the cache lines, there was has no effect on the cache line fetch
time - while at first surprising this result can be explained by the
round robin scheduling within the switch fabric.
showed the effects of the conflicting stream on the
cache service time was mainly influenced by the scheduling strategy of
the interconnect. For example in one experiment using video traffic
with a peak rate of 54Mbps at the same priority as
the cache lines, there was has no effect on the cache line fetch
time - while at first surprising this result can be explained by the
round robin scheduling within the switch fabric.
A more interesting result was found by using a traffic generator to create a interfering stream with higher priority at the contention point. The priority system ensures that this will always win over the cache request, simplifying the behaviour. The interference stream is generated as a burst of data followed by a gap. During the burst cells are injected into the fabric every cell time, and during the gap no cells are injected. The burst length was varied from 0 to 10 cells and the gap from 1 to 18 cells. Clearly, with no gap the cache request is unable to get through the fabric and the CPU is unable to access memory. The results are shown in figure 5.
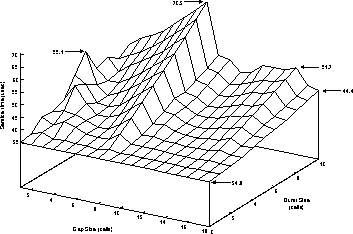
Figure 5: Service Time with High Priority Contention
To understand the shape of the graph it is important to note that 74%
of accesses are reads with a service time of just under eight cell
times and that a single cell time is very large compared to the CPU
speed. Therefore eight cell times after a request there is very likely
to be another request. Hence when the gap size is eight and a request
succeeds in the first cell time of the gap a subsequent request will
collide with the start of the next burst and be delayed. This results
in the peak seen for a gap of 8. Similarly the smaller peak at a gap
size of 16 where the next request succeeds but the third will be
blocked. Indeed the extra delay of 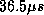 for a gap of eight and
for a gap of eight and
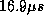 are very close to the expected 2:1 ratio which would be
seen if requests always occurred immediately after replies resulting
in every one being blocked with an 8 cell time gap and every other
blocked with a 16 cell time gap.
are very close to the expected 2:1 ratio which would be
seen if requests always occurred immediately after replies resulting
in every one being blocked with an 8 cell time gap and every other
blocked with a 16 cell time gap.
The conditions for this experiment are clearly contrived, especially marking the contending stream as higher priority than the CPU cache line access, but it serves to show that with a little thought about the scheduling used on the interconnect there is no obstacle to simultaneously carrying both multimedia and cache traffic on a DAN.
The principal gain from using caches is that the data currently being manipulated and the code being executed are both found in fast memory close to the processor. To obtain the same benefit for streams of multimedia data, use can be made of the close connection between the cache and the DAN - stream data from devices can be placed directly in the cache as it arrives. In this case, unlike the usual behaviour of a cache, data appears regardless of whether it has been previously accessed. The CPU therefore has fast access to the data as soon as it arrives, if the data is not yet present a cache-miss is seen and the processor stalls. The operating system on the machine must deal with two other cases: ``data in the past'', where the access is to part of the stream which has been lost from the buffer; and ``data in the future'', where the access is to data which will not arrive on the stream for some time. The first of these should be raised as an to the application as an exception, since it indicates that the process is unable to keep up with the incoming data rate. The second is likely to occur frequently if only parts of a frame are of interest, and should result in the processor being rescheduled. This idea is explored more fully in [\bf\protect\citenameHayter94].
An example use for this system is in what we term a ``Spot the Ball'' type problem. This is where the task is attempting to locate some feature in the incoming stream and track it from frame to frame. For example, the ball in a football match, the speaker's head in a seminar, or the probe on the end of a robot arm. In all these cases hints from previous frames may be used, and it is likely that only a small amount of the current frame will be examined. However, the access may be fairly random - depending on the search algorithm used. Implementation of a simplified ``Spot the Ball'' has been used to investigate the working of this system.