With the Atropos scheduler shares are specified using an application dependent period. The share of the processor each sdom receives is specified by a tuple . The slice s and period p together represent the processor bandwidth to the sdom: it will receive at least s ticks of CPU time (perhaps as several time slices) in each period of length p. x is a boolean value used to indicate whether the sdom is prepared to receive ``slack'' CPU time. l, the latency hint, is described below.
The Atropos scheduler internally uses an algorithm to provide this share guarantee. However the deadlines on which it operates are not available to or specified by the application - for the implementation of the scheduler to be simple and fast it relies on the fact that the QoS Manager has presented it with a soluble problem - this could not be ensured if the applications were allowed to specify their own deadlines.
An sdom can be in one of five states and may be on a scheduler queue:
For each sdom, the scheduler holds a deadline d, which is the time at which the sdom's current period ends, and a value r which is the time remaining to the sdom within its current period. There are queues Qr and Qw of runnable and waiting sdoms, both sorted by deadline (with dx and px the deadlines and periods of the respective queue heads), and a third queue of blocked sdoms.
The scheduler requires a hardware timer that will cause the scheduler
to be entered at or very shortly after a specified time in the
future, ideally with a microsecond resolution or better![]() . When the scheduler is
entered at time t as a result of a timer interrupt or an event
delivery:
. When the scheduler is
entered at time t as a result of a timer interrupt or an event
delivery:
This basic algorithm will find a feasible schedule. This is seen by
regarding a `task' as `the execution of an sdom for s nanoseconds'
- as the QoS Manager has ensured that the total share of the
processor allocated is less than 100% (i.e. 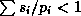 ),
and slices can be executed at any point during their period - this
approach satisfies the conditions required for an EDF algorithm to
function correctly[19],
),
and slices can be executed at any point during their period - this
approach satisfies the conditions required for an EDF algorithm to
function correctly[19],
This argument relies on two simplifications: firstly, that scheduling overhead is negligible, and secondly that the system is in a steady state. The first is addressed by ensuring there is sufficient slack time in the system to allow the scheduler to run and by not counting time in the scheduler as used by anybody. The second is concerned with moving an sdom with a share allocation from Qb to Qr. A safe option is to set d := t + p and r := s; this introduces the sdom with the maximum scheduling leeway and since a feasible schedule exists no deadlines will be missed as a result. For most domains this is sufficient, and it is the default behaviour.
In the limit, all sdoms can proceed simultaneously with an instantaneous share of the processor which is constant over time. This limit is often referred to as processor sharing. Moreover, it can efficiently support domains requiring a wide range of scheduling granularities.