Instead, Nemesis uses protection domains . A protection domain is a mapping from the virtual address space to a set of access rights, i.e. a protection domain P may be formally defined by:
![]()
Logically, all protection domains are considered subsets of an additional global protection domain. This allows the global protecting/sharing of certain memory regions; that is, the granting of a base level of permissions to all protection domains.
Every domain is associated with exactly one protection domain, although multiple domains may share such an association. The protection domain of an executing domain determines the accessibility of any region of memory to that executing domain.
A large portion of the Nemesis operating system is comprised of shared
text in the form of stateless libraries and closure-invoked
modules![[*]](foot_motif.gif) These, along with small amounts of
globally accessible data, may be considered to reside within the
global protection domain. The NTSC -- a rather special case -- will
in general exist partly within
the global protection domain, and partly outside any protection
domain.
This is illustrated in Figure 2.
These, along with small amounts of
globally accessible data, may be considered to reside within the
global protection domain. The NTSC -- a rather special case -- will
in general exist partly within
the global protection domain, and partly outside any protection
domain.
This is illustrated in Figure 2.
There is a close relationship between protection domains and stretches; since a stretch encapsulates a region of the virtual address space with the same accessibility, a protection domain may also be considered as a mapping from stretches to access rights. Hence the stretch interface provides a logical place to provide access control modification operations.
When a stretch is allocated, it is initialised with a default set of access rights -- read, write and meta -- for the protection domain of the caller. The third of these is the most interesting; a meta right provides the following functions:
Four kinds of access control operations are provided on a stretch:
The ``global'' rights referred to are the rights of the global protection domain of which all other protection domains are subsets. One consequence of this is that the accessibility of a stretch from a particular protection domain is always at least the global rights.
A region of the virtual address space is allocated by creating a stretch, and hence the part of the VM system which handles virtual address allocation is called the stretch allocator . Any domain may request a stretch from a stretch allocator, specifying the desired size and (optionally) a starting address and attributes. Should the request be successful, a new stretch will be created and returned to the caller. The caller is now the owner of the stretch. The starting address and length of the returned stretch may then be queried; these will always be a multiple of the page size.
There may be a number of stretch allocators, although they will manage non-overlapping regions. This may be useful in cases where it is desirable for certain regions of the virtual address space to be associated with certain properties; for example, one allocator might provide stretches for DMA buffers, another provide stretches which must be mapped in a certain way, and so forth. Using different allocators for these various portions of the address space allows differing resource management policies to be implemented.
A stretch itself encapsulates a particular contiguous region of the virtual address space, as determined by a (base,length) pair, with each address within the region having the same access permissions. It is not possible to move, shorten or extend the stretch once it has been created -- the base and length remain the same throughout the lifetime of the stretch.
These properties rule out the possibility of nested stretch allocators, since it would not be possible to modify the access permissions of any ``sub-stretch'' independently of any other. It is of course possible, however, to subdivide and reallocate the virtual addresses of the stretch in terms of some second level allocator (e.g. a heap).
When allocated, a stretch need not in general be backed by physical resources. Before the virtual address may be referred to, then, the stretch must be associated with a stretch driver -- we say that a stretch must be bound to a stretch driver. The stretch driver is the object responsible for providing any backing (physical memory, disk space, etc.) for the stretch.
Many implementations of stretch drivers exist; two in particular are worth mentioning:
Clearly a large number of alternatives is also conceivable: the only essential property of a stretch driver is that it somehow deal with events involving any part of any stretch with which it is associated.
The freeing of a stretch is similarly a two stage process. First the stretch is unbound from its stretch driver; this allows any physical resources which may have been associated with the stretch to be disposed of correctly. Secondly, the stretch is destroyed via a stretch allocator. This must be same stretch allocator used to allocate the stretch initially. Figure 3 shows the life-cycle of a stretch.
Note that the permission to unbind or destroy a stretch is independent
of the standard ![]() read, write, execute,
meta
read, write, execute,
meta ![]() rights associated with the stretch. Instead it is the
responsibility of the relevant stretch driver or allocator to
implement a protection scheme. Generally unbinding and destruction of
a stretch is restricted to the owning domain.
rights associated with the stretch. Instead it is the
responsibility of the relevant stretch driver or allocator to
implement a protection scheme. Generally unbinding and destruction of
a stretch is restricted to the owning domain.
Nemesis provides fine-grained control over the allocation of physical
memory, including (where applicable) I/O space. A stretch driver may
request specific physical frames, or frames within a ``special''
region.
This allows a stretch driver with platform knowledge to make use of page colouring, or to take
advantages of ``super-page'' TLB mappings, etc. Clearly, a default
allocation policy is also supported for domains with no special requirements.
As with virtual memory, the allocation of physical memory is done by a central frames allocator . This allocator actually supports two different interfaces so that domains may request physical memory in appropriate ways:
Only certain privileged domains have the power to perform physical accesses, and hence the use of this interface is restricted to these domains.
This represents the set of physical frames which a stretch driver may use for backing any of its stretches. The set is recorded in a nailed area defined by the translation system so that it is easy to validate mapping attempts by a domain.
As has been seen in the previous section, the responsibility for providing physical backing for a stretch is delegated to the stretch driver. Thus in general it is the stretch drivers that deal with a domain's frame stack.
As for stretch allocation, it is often desirable to have more than one frame allocator. This is particularly convenient on machines with memory mapped I/O space or with physical addresses which encode information about caching or buffering. The use of a separate allocator allows:
Clearly in the case where multiple frame allocators are available, it is not necessary for every one of them to provide both the Frames and FrameStack interface. This might rather be limited to a single allocator.
One further concern for physical memory allocators is that of
revocation . Limited physical memory generally implies
considerable contention.
In Nemesis memory management the ideas of guaranteed and optimistic resources are used, as they are for other resources in the system, e.g. CPU. A domain has some explicitly guaranteed number of physical frames which are immune from revocation in the short term. In addition, any domain may also have some number of optimistically allocated physical frames. This latter set are currently available for use by the domain, but are subject to later revocation without notification. The fact that the domain knows explicitly which frames it has been granted and under what conditions, allows it to place data in appropriate places.
Nemesis expects each domain to deal with mapping its own stretches, and as such a domain will generally require some physical frames which it may use for this purpose. Furthermore it is important that attempted use of the translation system can be easily validated to prevent unauthorised behaviour. This validation usually requires two checks to be made:
Conceptually, then, the translation system provides three operations:
The translation system is, however, a rather machine-specific object, and so particular implementations may refine or augment the above. A good example of where this is useful is for machines which have software managed TLBs -- on such architectures one may use an arbitrary page-table format and thus provide for reference bits if desired. An example of an implementation of the translation system will be seen in Section 5.
:
The above list includes all the faults which Nemesis currently recognises; it is not expected that every type of fault will be possible on every architecture.
Of key importance within Nemesis is the idea of accountability: every domain should perform whatever tasks are necessary for its own execution. In terms of the VM system, this means that a domain is responsible for satisfying any faults which occur on stretches which it owns. There is no concept of a ``system pager'', or of an ``application level pager'': instead, every domain is its own pager (or, more generally, memory fault handler).
Clearly this would be unduly complex in a traditional or microkernel operating system, but with a vertically integrated system, practically any system task may be easily shared by all domains. In this particular case, the domain will typically invoke the library code of an implemented stretch driver, though it may use a private implementation if it desires.
In order to achieve the above we require a light-weight low latency asynchronous mechanism whereby a domain may be notified of a fault occurring. The NTSC provides this by means of the event mechanism, which allows the asynchronous notification of a domain of some happening. Event channels are used throughout Nemesis to provide inter-domain communication and to support device driver stubs -- and to signal memory faults.
On a memory fault, the NTSC identifies the stretch containing the faulting address and sends the faulting domain an event. The next time this domain is activated, it should resolve the fault. This may involve simply mapping one of its unmapped frames, or may involve paging out a resident page. The decision on which page to replace is totally under the control of the domain which may therefore use whatever policy it prefers.
If the stretch was being shared, the domain which faulted may not be sufficiently authorised (i.e. may not possess meta rights for the stretch). In this case, it receives the event and notices that it cannot resolve the fault itself. If, as is common, it contains a user-level thread scheduler, it may decide to simply run another thread. Alternatively it may optimistically retry the faulting instruction, or attempt to contact a domain which can potentially resolve the fault.
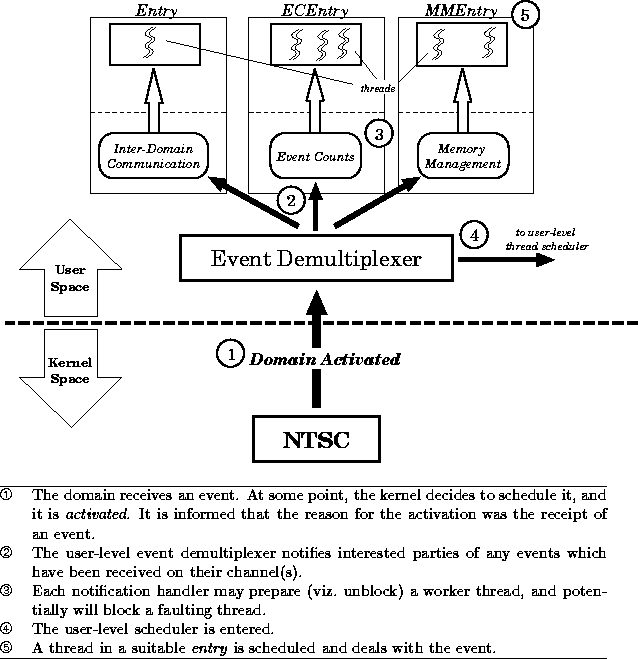
It is important to understand how the domain handles the incoming event, and how it notifies the correct handler accordingly. Figure 4 illustrates how domains can handle events: Note that the structure of the user-space part illustrated is not a mandatory aspect of the design -- any domain may deal with incoming events any way in which it wishes. The illustrated structure is, however, typical.
In the case of memory faults, the first two stages of the event delivery happen as normal. In the notification handler, however, there are usually two choices:
In the latter case, IDC operations are possible, facilitating paging, the handling of faults on shared stretches, and the invocation of a user-level debugger for unresolvable faults. More details on these aspects of fault handling are given in Section 5.5.
Nemesis is most suited to RISC architectures -- the ability to choose a page-table structure for the SAS model, to prefetch TLB entries on a protection domain boundary, or to make use of software TLBs allow a fine-tuning process not possible with CISC MMUs. One additional aspect of certain RISC architectures is software cache invalidation and/or prefetching. Nemesis supports such architectures by means of cache hints .
Cache hints provide a declarative interface to the hardware; the actual effect they have is implementation and machine specific. Likely semantics include the invalidation of a cache line (or of the entire cache) and the prefetching of a line (or lines) into a cache. Currently three cache hints are defined:
, this hint may be required in order to
ensure cache consistency in the presence of DMA access by IO
devices. In most cases, however, cache consistency is provided by
the hardware and the likely reaction to this hint will be a
nop.
In each case the associated range of virtual addresses is specified by region. The range is specified at a level of bytes (or at least words) rather than pages to allow caches to be invalidated or pushed over small objects (for example ATM cell payloads).
It is important to note that various other ``useful'' low-level features (such as a partitioned cache[Hayter94], or a protection translation buffer[Koldinfer92]) may be available on other or future architectures. It is difficult to design interfaces for all possible enhancements, and it is not attempted here. Whenever such interfaces are designed, however, they should be declarative . This allows implementations without the specific hardware to trivially support a nop reaction.
![\begin{figure}
\centerline{
\includegraphics [width=0.99\textwidth]{figures/pdoms_alt.eps}
}\end{figure}](img6.gif)
![\begin{figure}
\centerline{
\includegraphics [width=0.99\textwidth]{figures/life_cycle.eps}
}\end{figure}](img8.gif)