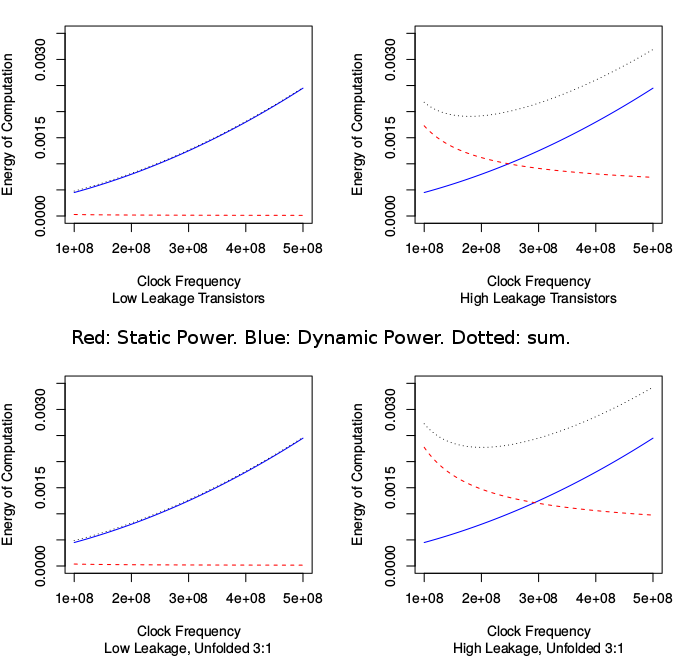
Sweetspot shift in DVFS approach for higher leakage on a real-time task.
But: for sub 45nm, voltage scaling is less viable and transistors with much higher static leakage current are commonly used: so can now be better to operate within the voltage/frequency band that works and then power off until next deadline.
# Trade off of Hare and Tortoise for increasingly leaky technology.
# For a hard-realtime computation we known the number of clock cycles needed but should we do them quickly
# and halt (Archilies) or slowly and finish just in time (Tortoise). For a higher leakage technology,
# switching off as much as possible tends to become preferable to running at low supply voltage.
# Unfold=1 is baseline design. Unfold=3 uses three times more silicon.
static_dynamic_tradeoff <- function(clock_freq, leakage, unfold, xx)
{
op_count <- 1e5;
execution_time = op_count / clock_freq / (unfold ^ 0.75); // Model: Pollack-like unfold benefit.
vdd <- 1 + 0.5 * (clock_freq/100e6); // Model: Higher supply needed for higher clk.
static_power <- leakage * vdd ^ 0.9 * unfold * 0.4; // Model: Leakage slightly sublinear.
static_energy <- static_power * execution_time; // Integrate static power
dynamic_energy <- op_count * vdd ^ 2.0 / 0.5 * 1e-9; // Use CV^2/2 for dynamic
}
| 37: (C) 2012-18, DJ Greaves, University of Cambridge, Computer Laboratory. |