A directed acyclic graph (DAG) can be used to represent a set of jobs where the input, output, or execution of one or more jobs is dependent on one or more other jobs. The jobs are nodes (vertices) in the graph, and the edges (arcs) identify the dependencies. Condor finds machines for the execution of programs, but it does not schedule programs based on dependencies. The Directed Acyclic Graph Manager (DAGMan) is a meta-scheduler for the execution of programs. DAGMan submits the programs to Condor in an order represented by a DAG and processes the results. A DAG input file describes the DAG, and further submit description file(s) are used by DAGMan when submitting programs to run under Condor.
DAGMan is itself executed as a scheduler universe job within Condor. As DAGMan submits programs, it monitors log file(s) to to enforce the ordering required within the DAG. DAGMan is also responsible for scheduling, recovery, and reporting on the set of programs submitted to Condor.
DAGMan now (as of version 6.7.17, with bug fixes in 6.7.18) allows multiple batch system processes per DAG node. Because of this, we are introducing some terminology to clarify the following discussion:
Prior to version 6.7.17, DAGMan required that each job contain only one job proc; now a single job can contain multiple job procs. The multiple job procs can result from a parallel universe job, or from a non-parallel job that simply queues multiple job procs (e.g., has a Queue n statement, where n > 1 or has multiple Queue statements).
There are some limitations on multiple job procs (these may change in future versions):
If a number of job procs are in the same cluster, they will have Condor IDs with the same value for the first part of the ID (e.g., 227.0, 227.1, 227.2). Having different executables within a given submit file is one thing that will cause a single condor_ submit to generate multiple clusters.
Note that for jobs with multiple job procs, the failure of any job proc means that the entire job will be considered failed. When DAGMan sees that a job proc has failed, it will immediately remove any other job procs of that job that are still running.
The input file used by DAGMan specifies seven items:
Comments may be placed in the input file that describes the DAG.
The pound character (#) as the first character on a
line identifies the line as a comment.
Comments do not span lines.
An example input file for DAGMan is
# Filename: diamond.dag
#
JOB A A.condor
JOB B B.condor
JOB C C.condor
JOB D D.condor
Script PRE A top_pre.csh
Script PRE B mid_pre.perl $JOB
Script POST B mid_post.perl $JOB $RETURN
Script PRE C mid_pre.perl $JOB
Script POST C mid_post.perl $JOB $RETURN
Script PRE D bot_pre.csh
PARENT A CHILD B C
PARENT B C CHILD D
Retry C 3
VARS A state="Wisconsin"
ABORT-DAG-ON C 10 RETURN 1
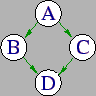
This input file describes the DAG shown in Figure 2.2.
DAGMan has the ability to manage different types of jobs. Condor CPU jobs are indicated with the JOB keyword. Stork data placement jobs are indicated with the DATA keyword. All JobNames, irrespective of type, must be unique. Otherwise, the term Job or job will indicate a generic job, of any type.
Each DAG file keyword is described below.
The first section of the input file lists all the jobs that appear in the DAG. Each job to be managed by Condor is described by a single line called a JOB Entry. The syntax used for each JOB Entry is
JOB JobName SubmitDescriptionFileName [DONE]
A JOB entry maps a JobName to a Condor submit description file. The JobName uniquely identifies nodes within the DAGMan input file and in output messages.
The keyword JOB and the JobName are not case sensitive. A JobName of joba is equivalent to JobA. The SubmitDescriptionFileName is case sensitive, since the UNIX file system is case sensitive. The JobName can be any string that contains no white space.
The optional DONE identifies a job as being already completed. This is useful in situations where the user wishes to verify results, but does not need all programs within the dependency graph to be executed. The DONE feature is also utilized when an error occurs causing the DAG to not be completed. DAGMan generates a Rescue DAG, a DAGMan input file that can be used to restart and complete a DAG without re-executing completed programs.
The DATA keyword specifies a job to be managed by the Stork data placement server. The syntax used for each DATA Entry is
DATA JobName SubmitDescriptionFileName [DONE]
A DATA Entry maps a JobName to a Stork submit description file. In all other respects, the DATA keyword is identical to the JOB keyword.
Here is an example of a simple DAG that stages in data using Stork, processes the data using Condor, and stages the processed data out using Stork. Depending upon the implementation, multiple data jobs to stage in data or to stage out data may be run in parallel.
DATA STAGE_IN1 stage_in1.stork
DATA STAGE_IN2 stage_in2.stork
JOB PROCESS process.condor
DATA STAGE_OUT1 stage_out1.stork
DATA STAGE_OUT2 stage_out2.stork
PARENT STAGE_IN1 STAGE_IN2 CHILD PROCESS
PARENT PROCESS CHILD STAGE_OUT1 STAGE_OUT2
The third type of item in a DAGMan input file enumerates processing that is done either before a job within the DAG is submitted to Condor or Stork for execution or after a job within the DAG completes its execution. Processing done before a job is submitted to Condor or Stork is called a PRE script. Processing done after a job completes its execution under Condor or Stork is called a POST script. A node in the DAG is comprised of the job together with PRE and/or POST scripts. The dependencies in the DAG are enforced based on nodes.
Syntax for PRE and POST script lines within the input file:
SCRIPT PRE JobName ExecutableName [arguments]
SCRIPT POST JobName ExecutableName [arguments]
The SCRIPT keyword identifies the type of line within the DAG input file. The PRE or POST keyword specifies the relative timing of when the script is to be run. The JobName specifies the node to which the script is attached. The ExecutableName specifies the script to be executed, and it may be followed by any command line arguments to that script. The ExecutableName and optional arguments have their case preserved.
Scripts are optional for each job, and any scripts are executed on the machine to which the DAG is submitted (not necessarily the machine on which the node's job is run). (And note that if a job contains multiple job procs, the job itself may be spread across several machines.)
The PRE and POST scripts are commonly used when files must be placed into a staging area for the job to use, and files are cleaned up or removed once the job is finished running. An example using PRE/POST scripts involves staging files that are stored on tape. The PRE script reads compressed input files from the tape drive, and it uncompresses them, placing the input files in the current directory. The program within the DAG node is submitted to Condor, and it reads these input files. The program produces output files. The POST script compresses the output files, writes them out to the tape, and then deletes the staged input and output files.
DAGMan takes note of the exit value of the scripts as well as the job. If the PRE script fails (exit value != 0), then neither the job nor the POST script runs, and the node is marked as failed.
If the PRE script succeeds, the job is submitted to Condor or Stork. If the job fails and there is no POST script, the DAG node is marked as failed. An exit value not equal to 0 indicates program failure. It is therefore important that the program returns the exit value 0 to indicate the program did not fail.
If the job fails and there is a POST script, node failure is determined by the exit value of the POST script. A failing value from the POST script marks the node as failed. A succeeding value from the POST script (even with a failed job) marks the node as successful. Therefore, the POST script may need to consider the return value from the job.
By default, the POST script is run regardless of the job's return value.
A node not marked as failed at any point is successful.
Two variables are available to ease script writing. The $JOB variable evaluates to JobName. For POST scripts, the $RETURN variable evaluates to the return value of the job. Jobs that die from signals are reported with a $RETURN value representing the negative signal number. For example, SIGKILL (signal 9) is reported as -9. Jobs whose batch system submission fails are reported as -1001. Jobs which are externally removed from the batch system queue (i.e., by something other than condor_ dagman) are reported as -1002. The $JOB and $RETURN variables may be placed anywhere within the POST script arguments.
As an example, suppose the PRE script expands a compressed file named JobName.gz. The SCRIPT entry for jobs A, B, and C are
SCRIPT PRE A pre.csh $JOB .gz
SCRIPT PRE B pre.csh $JOB .gz
SCRIPT PRE C pre.csh $JOB .gz
The script pre.csh may use these arguments
#!/bin/csh
gunzip $argv[1]$argv[2]
The fourth type of item in the DAG input file describes the dependencies within the DAG. Nodes are parents and/or children within the DAG. A parent node must be completed successfully before any child node may be started. A child node is started once all its parents have successfully completed.
The syntax of a dependency line within the DAG input file:
PARENT ParentJobName... CHILD ChildJobName...
The PARENT keyword is followed by one or more ParentJobNames. The CHILD keyword is followed by one or more ChildJobNames. Each child job depends on every parent job on the line. A single line in the input file can specify the dependencies from one or more parents to one or more children. As an example, the line
PARENT p1 p2 CHILD c1 c2produces four dependencies:
p1 to c1
p1 to c2
p2 to c1
p2 to c2
The fifth type of item in the DAG input file provides a way (optional) to retry failed nodes. The syntax for retry is
RETRY JobName NumberOfRetries [UNLESS-EXIT <value>]
where the JobName is the same as the name given in a Job Entry line, and NumberOfRetries is an integer, the number of times to retry the node after failure. The default number of retries for any node is 0, the same as not having a retry line in the file.
In some cases, it is inappropriate to retry for the number of times specified. For example, a PRE script may edit the job's submit file to indicate what it should do, and if it runs out of possibilities after a few retries, then there is no point in continuing to retry the node. In this case, you can specify UNLESS-EXIT, and if any of the parts of the node (PRE script, job, or POST script) exits with the specified value, then the node will be aborted and will not be retried.
In the event of retry, all parts of a node within the DAG are redone, following the same rules regarding node failure as given above. The PRE script is executed first, followed by submitting the job to Condor or Stork upon success of the PRE script. Failure of the node is then determined by the return value of the job, the existence and return value of a POST script.
The sixth type of item in the DAG input file provides a method of defining a macro to be placed into the submit description file. These macros are defined on a per-node basis, using the following format.
VARS JobName macroname="string"...
The definition of the macro is available to use within the
submit description file. The macroname can be variable
length and consist of alphanumerics (e.g. a..Z and 0..9) and
underscores. The space character delimits the list of macros when
there is more than one macro defined for each JobName.
Correct syntax requires that the string must be
enclosed in double quotes.
To use a double quote inside string,
escape it with the backslash character (\).
To add the backslash character itself, use two backslashes (\\).
Note that macronames cannot begin with "queue" (in any combination of upper and lower case).
The seventh type of item in the DAG input file provides a way to abort the entire DAG if a given node returns a specific exit code. The syntax for ABORT-DAG-ON:
ABORT-DAG-ON JobName AbortExitValue [RETURN <DAGReturnValue>]
If the specified node returns the specified abort exit value, the DAG is immediately aborted. The main difference between a node failure and a DAG abort is that in the case of an abort, the DAG is stopped immediately, including removing nodes that are currently running. In the case of a node failure, the DAG will continue to run until no more progress can be made because of the DAG dependencies.
An abort of a DAG is based on exit values from within a node, where the node can contain a PRE script, the job itself, and a POST script. If a node has a PRE script and the PRE script returns the abort exit value, the DAG is aborted. If the node has no POST script, and the job returns the abort exit value, the DAG is aborted. If the node has a POST script, the POST script is run, and the DAG is aborted if the POST script returns the abort exit value.
An abort overrides node retries. If a node returns the abort exit value, the DAG is aborted, even if the node has retries specified.
When a DAG aborts, by default it exits with the node return value that caused the abort. This can be changed by specifying the DAG return value with the RETURN keyword. The DAG abort return value can be used for DAGs within DAGs, allowing an inner DAG to cause an abort of an outer DAG.
Each node in a DAG may have a unique executable, and each may have a unique submit description file. Each Condor job may be submitted to a different universe, for example standard, vanilla, or local.
One key limitation: each Condor submit description file must submit only one cluster. At the present time DAGMan cannot deal with a submit file producing multiple job clusters.
DAGMan no longer requires that all jobs specify the same log file. However, if the DAG contains a very large number of jobs, each specifying its own log file, performance may suffer. Therefore, if the DAG contains a large number of jobs, it is best to have all of the jobs use the same log file. Another current limitation is that all Stork jobs currently require a separate log file. DAGMan enforces the dependencies within a DAG using the events recorded in the log file(s) produced by job submission to Condor.
Here is a simple input file for a modified version of diamond-shaped DAG example.
# Filename: diamond.dag
#
JOB A diamond_job.condor
JOB B diamond_job.condor
JOB C diamond_job.condor
JOB D diamond_job.condor
PARENT A CHILD B C
PARENT B C CHILD D
A single Condor submit description file goes with all the nodes in this DAG:
# Filename: diamond_job.condor
#
executable = /path/diamond.exe
output = diamond.out.$(cluster)
error = diamond.err.$(cluster)
log = diamond_condor.log
universe = vanilla
notification = NEVER
queue
This example uses the same Condor submit description file for all the jobs in the DAG. This implies that each node within the DAG runs the same job. The $(cluster) macro is used to produce unique file names for each job's output. Each JOB is submitted separately, into its own cluster, so this provides unique names for the output files.
The notification is set to NEVER in this example.
This tells Condor not to send e-mail about the completion of a job
submitted to Condor.
For DAGs with many nodes, this is recommended
to reduce or eliminate excessive numbers of e-mails.
A separate example shows an intended use of a VARS entry in the DAG. It can be used to dramatically reduce the number of submit description files needed for a DAG. In the case where the submit description file for each node varies only in file naming, the use of a substitution macro within the submit description file allows the use of a single submit description file. Note that the user log file for a job currently cannot be specified using a macro passed from the DAG.
The example uses a single submit description file in the DAG input file, and uses the Vars entry to name output files.
# submit description file called: theonefile.sub
executable = progX
output = $(outfilename)
error = error.$(outfilename)
universe = standard
queue
The relevant portion of the DAG input file appears as
JOB A theonefile.sub JOB B theonefile.sub JOB C theonefile.sub VARS A outfilename="A" VARS B outfilename="B" VARS C outfilename="C"
For a DAG like this one with thousands of nodes, being able to write and maintain a single submit description file and a single, yet more complex, DAG input file is preferable.
A DAG is submitted using the program condor_ submit_dag.
See the manual
page ![[*]](crossref.png) for complete details.
A simple submission has the syntax
for complete details.
A simple submission has the syntax
condor_ submit_dag DAGInputFileName
The example may be submitted with
condor_submit_dag diamond.dagIn order to guarantee recoverability, the DAGMan program itself is run as a Condor job. As such, it needs a submit description file. condor_ submit_dag produces the needed file, naming it by appending .condor.sub to the DAGInputFileName. This submit description file may be edited if the DAG is submitted with
condor_submit_dag -no_submit diamond.dagcausing condor_ submit_dag to generate the submit description file, but not submit DAGMan to Condor. To submit the DAG, once the submit description file is edited, use
condor_submit diamond.dag.condor.sub
An optional argument to condor_ submit_dag, -maxjobs, is used to specify the maximum number of batch jobs that DAGMan may submit at one time. It is commonly used when there is a limited amount of input file staging capacity. As a specific example, consider a case where each job will require 4 Mbytes of input files, and the jobs will run in a directory with a volume of 100 Mbytes of free space. Using the argument -maxjobs 25 guarantees that a maximum of 25 jobs, using a maximum of 100 Mbytes of space, will be submitted to Condor and/or Stork at one time.
While the -maxjobs argument is used to limit the number of batch system jobs submitted at one time, it may be desirable to limit the number of scripts running at one time. The optional -maxpre argument limits the number of PRE scripts that may be running at one time, while the optional -maxpost argument limits the number of POST scripts that may be running at one time.
An optional argument to condor_ submit_dag, -maxidle, is used to limit the number of idle jobs within a given DAG. When the number of idle node jobs in the DAG reaches the specified value, condor_ dagman will stop submitting jobs, even if there are ready nodes in the DAG. Once some of the idle jobs start to run, condor_ dagman will resume submitting jobs. Note that this parameter only limits the number of idle jobs submitted by a given condor_ dagman - idle jobs submitted by other sources (including other condor_ dagman runs) are ignored.
DAGs that submit jobs to Stork using the DATA keyword must also specify the Stork user log file, using the -storklog argument.
After submission, the progress of the DAG can be monitored by looking at the log file(s), observing the e-mail that job submission to Condor causes, or by using condor_ q -dag. You can also look at the dagman.out file. This file contains a large amount of information about the DAGMan run. The name of the dagman.out file is produced by appending .dagman.out to DAGInputFileName; for example, if the DAG file is diamond.dag, the dagman.out file is diamond.dag.dagman.out.
If the dagman.out file grows too big, you can limit its size with the MAX_DAGMAN_LOG configuration macro (see section 3.3.22).
If you have some kind of problem in your DAGMan run, please save the corresponding dagman.out file - it is the most important debugging tool for DAGMan. As of version 6.8.2, the dagman.out is appended to, rather than overwritten, with each new DAGMan run.
condor_ submit_dag attempts to check the DAG input file. If a problem is detected, condor_ submit_dag prints out an error message and aborts.
To remove an entire DAG, consisting of DAGMan plus any jobs submitted to Condor or Stork, remove the DAGMan job running under Condor. condor_ q will list the job number. Use the job number to remove the job, for example
% condor_q
-- Submitter: turunmaa.cs.wisc.edu : <128.105.175.125:36165> : turunmaa.cs.wisc.edu
ID OWNER SUBMITTED RUN_TIME ST PRI SIZE CMD
9.0 smoler 10/12 11:47 0+00:01:32 R 0 8.7 condor_dagman -f -
11.0 smoler 10/12 11:48 0+00:00:00 I 0 3.6 B.out
12.0 smoler 10/12 11:48 0+00:00:00 I 0 3.6 C.out
3 jobs; 2 idle, 1 running, 0 held
% condor_rm 9.0
Before the DAGMan job stops running, it uses condor_ rm and/or stork_ rm to remove any jobs within the DAG that are running.
In the case where a machine is scheduled to go down, DAGMan will clean up memory and exit. However, it will leave any submitted jobs in Condor's queue.
DAGMan can help with the resubmission of uncompleted portions of a DAG when one or more nodes resulted in failure. If any node in the DAG fails, the remainder of the DAG is continued until no more forward progress can be made based on the DAG's dependencies. At this point, DAGMan produces a file called a Rescue DAG.
The Rescue DAG is a DAG input file, functionally the same as the original DAG file. It additionally contains indication of successfully completed nodes using the DONE option in the input description file. If the DAG is resubmitted using this Rescue DAG input file, the nodes marked as completed will not be re-executed.
The Rescue DAG is automatically generated by DAGMan when a node within the DAG fails. The file is named using the DAGInputFileName, and appending the suffix .rescue to it. Statistics about the failed DAG execution are presented as comments at the beginning of the Rescue DAG input file.
If the Rescue DAG file is generated before all retries of a node are completed, then the Rescue DAG file will also contain Retry entries. The number of retries will be set to the appropriate remaining number of retries.
Note that for jobs with multiple job procs, the entire job must be re-run as a unit. So if some job procs of a given job failed and some succeeded on the first try, when running the rescue DAG even the job procs that succeeded will be re-run.
It can be helpful to see a picture of a DAG. DAGMan can assist you in visualizing a DAG by creating the input files used by the AT&T Research Labs graphviz package. dot is a program within this package, available from http://www.graphviz.org/, and it is used to draw pictures of DAGs.
DAGMan produces one or more dot files as the result of an extra line in a DAGMan input file. The line appears as
DOT dag.dot
This creates a file called dag.dot. which contains a specification of the DAG before any jobs within the DAG are submitted to Condor. The dag.dot file is used to create a visualization of the DAG by using this file as input to dot. This example creates a Postscript file, with a visualization of the DAG:
dot -Tps dag.dot -o dag.ps
Within the DAGMan input file, the DOT command can take several optional parameters:
DOT dag.dot DONT-OVERWRITE
causes files
dag.dot.0,
dag.dot.1,
dag.dot.2,
etc. to be created.
This option is
most useful combined with the UPDATE option to
visualize the history of the DAG after it has finished executing.
label=.
This may be useful if further editing of the created files would
be necessary,
perhaps because you are automatically visualizing the DAG as it
progresses.
If conflicting parameters are used in a DOT command, the last one listed is used.
The organization and dependencies of the jobs within a DAG are the keys to its utility. There are cases when a DAG is easier to visualize and construct hierarchically, as when a node within a DAG is also a DAG. Condor DAGMan handles this situation with grace.
Since more than one DAG is being discussed, terminology is introduced to clarify which DAG is which. Reuse the example DAG as given in Figure 2.2. Assume that node B of this diamond-shaped DAG will itself be a DAG. The DAG of node B is called the inner DAG, and the diamond-shaped DAG is called the outer DAG.
To make DAGs within DAGs, the essential element is getting the name of the submit description file for the inner DAG correct within the outer DAG's input file.
Work on the inner DAG first. The goal is to generate a Condor submit description file for this inner DAG. Here is a very simple DAG input file used as an example of the inner DAG.
# Filename: inner.dag
#
JOB X X.submit
JOB Y Y.submit
JOB Z Z.submit
PARENT X CHILD Y
PARENT Y CHILD Z
Use condor_ submit_dag to create a submit description file for this inner dag:
condor_submit_dag -no_submit inner.dagThe resulting file will be named inner.dag.condor.sub. This file will be needed in the DAG input file of the outer DAG. The naming of the file is the name of the DAG input file (inner.dag) with the suffix .condor.sub.
A simple example of a DAG input file for the outer DAG is
# Filename: diamond.dag
#
JOB A A.submit
JOB B inner.dag.condor.sub
JOB C C.submit
JOB D D.submit
PARENT A CHILD B C
PARENT B C CHILD D
The outer DAG is then submitted as before, with
condor_submit_dag diamond.dag
More than one level of nested DAGs is supported.
One item to get right: to locate the log files used in ordering the DAG, DAGMan either needs a completely flat directory structure (all files for outer and inner DAGs within the same directory) or it needs full pathnames to all log files.
A single use of condor_ submit_dag may execute multiple, independent DAGs. Each independent DAG has its own DAG input file. These DAG input files are command-line arguments to condor_ submit_dag (see the condor_ submit_dag manual page at 9).
Internally, all of the independent DAGs are combined into a single, larger DAG, with no dependencies between the original independent DAGs. As a result, any generated rescue DAG file represents all of the input DAGs as a single DAG. The file name of this rescue DAG is based on the DAG input file listed first within the command-line arguments to condor_ submit_dag (unlike a single-DAG rescue DAG file, however, the file name will be <whatever>.dag_multi.rescue, as opposed to just <whatever>.dag.rescue). Other files such as dagman.out and the lock file also have names based on this first DAG input file.
The success or failure of the independent DAGs is well defined. When multiple, independent DAGs are submitted with a single command, the success of the composite DAG is defined as the logical AND of the success of each independent DAG. This implies that failure is defined as the logical OR of the failure of any of the independent DAGs.
By default, DAGMan internally renames the nodes to avoid node name collisions. If all node names are unique, the renaming of nodes may be disabled by setting the configuration variable DAGMAN_MUNGE_NODE_NAMES to False (see 3.3.22).
By default, condor_ dagman assumes that all relative paths in a DAG file and the associated submit files are relative to the current working directory when condor_ submit_dag is run. (Note that relative paths in submit files can be modified by the submit command initialdir; see the condor_ submit manual page at 9 for more details. The rest of this discussion ignores initialdir.)
In most cases, this is what you want. However, if you are running multiple DAGs with a single condor_ dagman, and each DAG is in its own directory, this will cause problems. In this case, you should use the -usedagdir command-line argument to condor_ submit_dag (see the condor_ submit_dag manual page at 9 for more details). This tells condor_ dagman to run each DAG as if condor_ submit_dag had been run in the directory in which the relevant DAG file exists.
For example, assume that a directory called parent contains two subdirectories called dag1 and dag2, and that dag1 contains the file one.dag and dag2 contains the file two.dag. Further, assume that each DAG is set up to be run from its own directory (i.e, the following command:
cd dag1; condor_submit_dag one.dagwill correctly run one.dag).
The goal is to run the two, independent DAGs located within dag1 and dag2 while the current working directory is parent. To do so, run the following command:
condor_submit_dag -usedagdir dag1/one.dag dag2/two.dag
Of course, if all paths in your DAG file(s) and the relevant submit files are absolute, you don't need the -usedagdir argument; however, using absolute paths is NOT generally a good idea.
If you don't use -usedagdir, relative paths can still work for multiple DAGs, if all file paths are given relative to the current working directory as condor_ submit_dag is executed. However, this means that, if the DAGs are in separate directories, they cannot be submitted from their own directories, only from the parent directory the paths are set up for.
Note that if you use the -usedagdir argument, and your run results in a rescue DAG, the rescue DAG file will be written to the current working directory, and should be run from that directory. The rescue DAG includes all the path information necessary to run each node job in the proper directory.
Configuration variables relating to DAGMan may be found in section 3.3.22.