A World Wide Web client or browser![]() connects to a World Wide Web
server and asks for a document. It knows which server to connect
to and which document to ask for from the information given in a
URL (see chapters 3 and 5).
connects to a World Wide Web
server and asks for a document. It knows which server to connect
to and which document to ask for from the information given in a
URL (see chapters 3 and 5).
When the server replies with the contents of the document, the client must display it to the user.
Now, a document can contain plain text to be displayed, it can
contain HTML text which needs special formatting, or it can
contain multimedia data such as a picture or an audio clip to be
displayed or played. The client must decide what type of data the
document contains, and so what to do with it. The information
about what type of data the document contains is conveyed in a
few additional lines of information the WWW server adds to the
top of the document. In particular, the line that says what type of
data is in the document is called the content type (see sections
![]() and
and ![]() for more details).
for more details).
Some content types, such as plain text or HTML text, will be
dealt with by the client itself. Plain text is easy to display. HTML
takes a little more intelligence, as it needs laying out neatly on the
screen in appropriate fonts and the paragraphs of text need to be
wrapped at appropriate places if the screen is too narrow to
display them. HTML can also contain embedded images (see
section ![]() ). To display an embedded image the
browser will need to make another connection to a
server
). To display an embedded image the
browser will need to make another connection to a
server![]() to
retrieve the image data
to
retrieve the image data![]() , and then it'll need to leave enough
space in the text to insert the picture. See figure 4.1
for an example.
, and then it'll need to leave enough
space in the text to insert the picture. See figure 4.1
for an example.
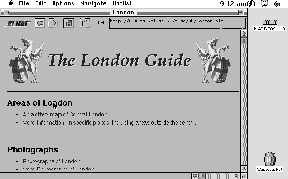
Figure 4.1: EIT MacWeb displaying images on an
Apple Macintosh
Some links in an HTML document will also result in documents
being retrieved that contain data that cannot be displayed by the
browser itself.
In most cases the browser will then send the document data to a
separate viewer program to display the image or play the
video or audio![]() clip that the document data
represents. See section 4.6 for how a browser knows
which viewer to start up.
clip that the document data
represents. See section 4.6 for how a browser knows
which viewer to start up.