Given that all changes to a document are multicast, and that all changes are timestamped, we have a simple mechanism for clock synchronisation amongst the members of a group:
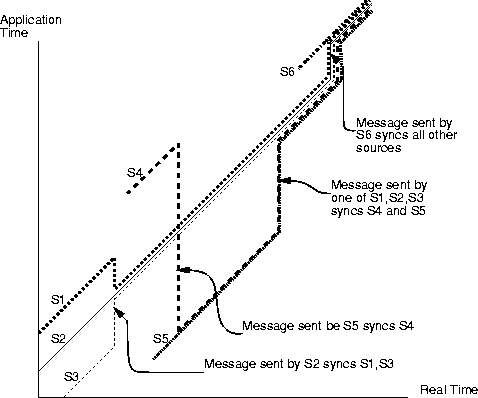
Figure 8.2 illustrates this process. In this figure, source S2 sends the first message, and S1 and S3 synchronise to the timestamp in the message. Note S1 can only move its clock backwards because it has no data. Two new sources then join, S4 and S5, and before any of the original sources send a message, S5 does so. As S4 has sent no message (therefore has no data), it now synchronises to S5. The three original sources have data therefore do not synchronise to S5. One of the three original sources then sends, and both S4 and S5 synchronise to the timestamp in the message. A new source S6 then joins, and sends before anyone else does. As its local clock is ahead, all the existing sources now synchronise to it.
To illustrate in more detail, this consider three sites A, B, & C, with three application clocks tA, tB, and tC, and positive transmission delays dAB, dAC, etc.
if A sends the first message, we have
tB=tA-dAB
tC=tA-dAC
if dAB ever decreases when A sends, then B will increase its clock to match the new delay, and tA and tB become closer.
if dAB increases, B continues to use tB
Now consider a message sent by C:
This message arrives at B with timestamp tA-dAC and it arrives at time tA-dAB+dCB. A comparison is made and only if dAC < dAB-dCB is the clock at B increased to be tA-dAC. Thus the clock at B can only get closer to the clock at A when a message is received from C.
The process continues so long as messages are sent.
As all messages are timestamped anyway, global clock synchronisation to less than the minimum delay between any two active sites is provided for free, and no explicit clock synchronisation protocol is required. Naturally this assumes that all local clocks run at the same rate. This is a reasonable assumption for almost all of today's workstations. Even if there is a clock in a conference that does not run at the same rate as the rest, this does not cause the application any real problems. The worst that can happen is that all clocks increase whenever a message from the fastest clock is received, and that timestamps bear no relation to real time, and do not get successively more accurate than the first pass approximation.
There are many algorithms that synchronise the clocks more accurately than the algorithm given above, but for the purposes of consistency control, a necessary feature is that clocks are never decreased, and the algorithm given is simple and sufficient.
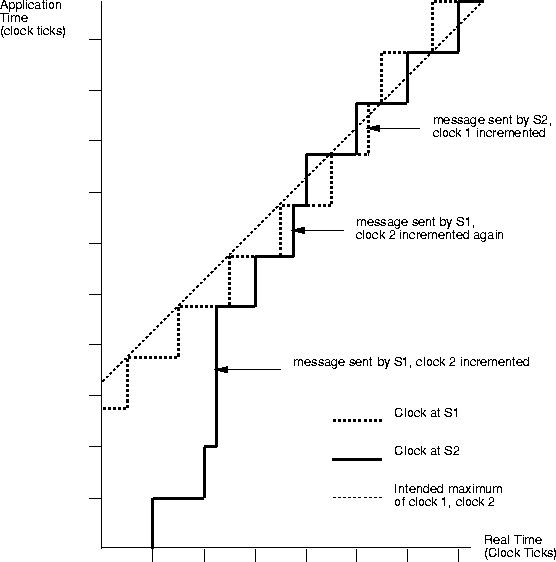
Implementation of this algorithm reveals that there is a case where clocks do not stabilise to the fastest clock. This occurs when two sites with a clock tick of length t are connected by a network with a transit delay of less than t, as illustrated in figure 8.3. This can happen with some Unix workstations with a 20ms clock resolution connected by a local Ethernet. Under these circumstances, the receiver will synchronise to the sender to a resolution of less than t. If the two clocks are not in phase, then the receiver can be ahead of the sender for part of each clock cycle. If their roles as sender and receiver are reversed and the new sender now sends a packet at a point in the clock cycle where its clock is ahead, the old sender then increments its clock to match the new sender. If both sites send alternately, this can result in both clocks being incremented indefinitely. This can simply be avoided if the clock tick interval is known, by simply ignoring and clock differences of less than the clock tick interval. This is not noticeable from the user's point of view as clock tick intervals are generally less than 20ms.
![]()
![]()
![]()
![]()
Next: Towards Reliability
Up: Design
Previous: Distributing the data model
Jon CROWCROFT
1998-12-03