The source coder operates on only non-interlaced pictures. Pictures are coded as luminance and two color difference components(Y, Cb, Cr). The Cb and Cr matrices are half the size of the Y matrix.
H261 supports two image resolutions, QCIF which is (144x176 pixels)and , optionally, CIF which is(288x352).
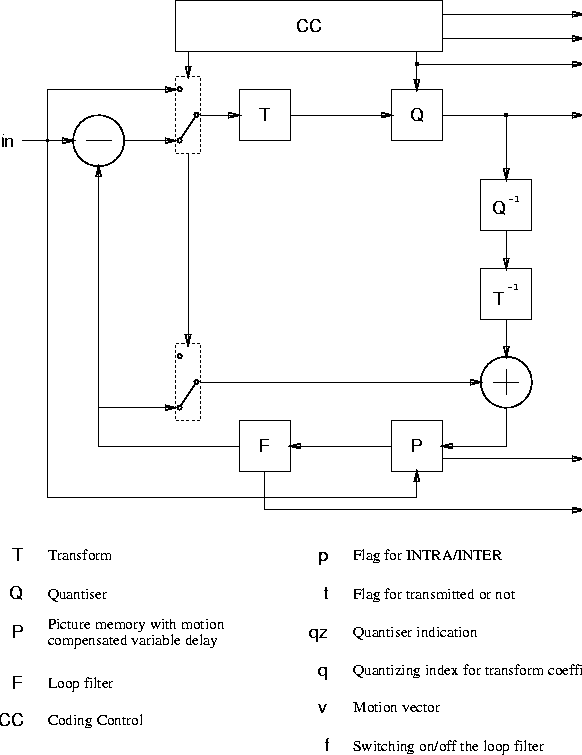
The three main elements in an H.261 encoder as illustrated in 4.14 are:
H261 defines two types of coding. INTRA coding where blocks of 8x8 pixels each are encoded only with reference to themselves and are sent directly to the block transformation process. On the other hand INTER coding frames are encoded with respect to another reference frame.
A prediction error is calculated between a 16x16 pixel region (macroblock) and the (recovered) correspondent macroblock in the previous frame. Prediction error of transmitted blocks (criteria of transmission is not standardized) are then sent to the block transformation process.
H261 supports motion compensation in the encoder as an option. In motion compensation a search area is constructed in the previous (recovered) frame to determine the best reference macroblock . Both the prediction error as well as the motion vectors specifying the value and direction of displacement between the encoded macroblock and the chosen reference are sent. The search area as well as how to compute the motion vectors are not subject to standardization. Both horizontal and vertical components of the vectors must have integer values in the range + 15 and 15 though
In block transformation, INTRA coded frames as well as prediction errors will be composed into 8x8 blocks. Each block will be processed by a two-dimensional FDCT function. If this sounds expensive, there are fast table driven algorithms and can be done in s/w quite easily, as well as very easily in hardware.
The purpose of this step is to achieve further compression by representing the DCT coefficients with no greater precision than is necessary to achieve the required quality. The number of quantizers are 1 for the INTRA dc coefficients and 31 for all others.
Entropy coding involves extra compression (non-lossy) is done by assigning shorter code-words to frequent events and longer code-words to less frequent events. Huffman coding is usually used to implement this step.
In other words, for a given quality, we can lose coefficients of the transform by using less bits than would be needed for all the values This leads to a "coarser" picture. We can then entropy code the final set of values by using shorter words for the most common values and longer ones for rarer ones (like using 8 bits for three letter words in English:-)