


Next: Hierarchical Coding
Up: Video Input and Output
Previous: Color Output by Computers
Video compression can take away the requirement for the very high data rates
and move video transmission and storage into a very similar regime to that
for audio. In fact, in terms of tolerance for poor quality, it seems humans
are better at adapting to poor visual information than poor audio
information.
A simple minded calculation shows the amount of data you might expect,
and is shown in table 4.5.
Table 4.5:
Liberal Estimate for Uncompressed Video Data Rate
| 1024 x 1024 pixels, |
| 3 bytes per pixel (24 bit RGB) |
| 25 Frames per second |
|
yields 75Mbytes/second, or 600Mbps - this is right on the limit of modern
transmission capacity.
Even in this age of deregulation and cheaper telecoms, and larger, faster
disks, this is profligate.
On the other hand, for a scene with a human face in, as few as 64 pixels
square, and 10 frames per second might suffice for a meaningful image.
Table 4.6:
Cautious Estimate for Uncompressed Video Data Rate
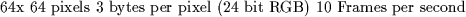 |
yields 122KBytes/Second, or just under 1 Mbps - this is achievable on modern
LANs and high speed WANs but still not friendly!
Notice that in the last simple example, we did two things to the picture.
- 1.
- We used less "space" for each frame by sending less "detail".
- 2.
- We sent frames less frequently since little is moving.
This is a clue as to how to go about improving things. Basically, if
there isn't much information to send, we avoid sending it. Spatial and
temporal domain compression are both used in many of the standards.
If a frame contains a lot of image that is the same, maybe we can encode
this with less bits without losing any information (run length encode, use
logically larger pixels etc. etc.). On the other hand, we can take advantage
of other features of natural scenes to reduce the amount of bits - for
example, nature is very fractal, or self-similar:- there are lots of
features, sky, grass, lines on face etc., that are repetitive at any level
of detail. If we leave out some levels of detail, the eye (and human visual
cortex processing) end up being fooled a lot of the time. The way that
the eye and the ear work (integration versus differentiation) means
that video and audio compression are very different things.
Next: Hierarchical Coding
Up: Video Input and Output
Previous: Color Output by Computers
Jon CROWCROFT
1998-12-03