All the while in Computer Science we are concerned with how long things are going to take. It is almost always necessary to make a few simplifying assumptions before starting of cost estimation, and for algorithms the ones most commonly used are:
Despite the severity of all these limitations cost estimation for algorithms has proved very useful, and almost always the indications it gives relate closely to the practical behaviour people observe when they write and run programs.
The notations bit-O and ![]() are used as short-hand for some of the
above cautions.
are used as short-hand for some of the
above cautions.
A function f(n) is said to be O(g(n)) if there are constants k and Nsuch that f(n) < k g(n) whenever n > N.
A function f(n) is said to be
![]() if there are constants k1,
k2 and N such that
k1g(n) < f(n) < k2g(n) whenever n > N.
if there are constants k1,
k2 and N such that
k1g(n) < f(n) < k2g(n) whenever n > N.
Note that neither notation says anything about f(n) being a computing
time estimate, even though that will be a common use. Big-O just provides
an upper bound to say that f(n) is less than something, while ![]() is much stronger, and indicates that eventually f and g agree within
a constant factor. Here are a few examples that may help explain:
is much stronger, and indicates that eventually f and g agree within
a constant factor. Here are a few examples that may help explain:
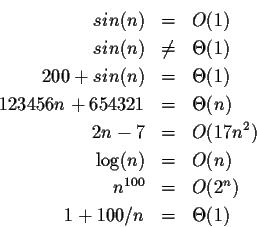
Various important computer procedures have costs that grow as
![]() .
In the proofs of this the logarithm will often come out as ones to base 2,
but observe that
.
In the proofs of this the logarithm will often come out as ones to base 2,
but observe that
![]() [indeed a stronger
statement could be made--the ratio between them is utterly fixed], so
with Big-O or
[indeed a stronger
statement could be made--the ratio between them is utterly fixed], so
with Big-O or ![]() notation there is no need to specify the base of
logarithms--all versions are equally valid.
notation there is no need to specify the base of
logarithms--all versions are equally valid.