Key observation (from DJ Greaves): Much high-performance computing on FPGA is limited by I/O bandwidth, so let's make sure we use 100 percent of that and factor everything else around it.
No program counter - Stream Processing processes the stream in stream order.
Data flows as fast as possible to/from DRAM bank or fileserver - good. Programs need to be linearised to wrap around the stream.
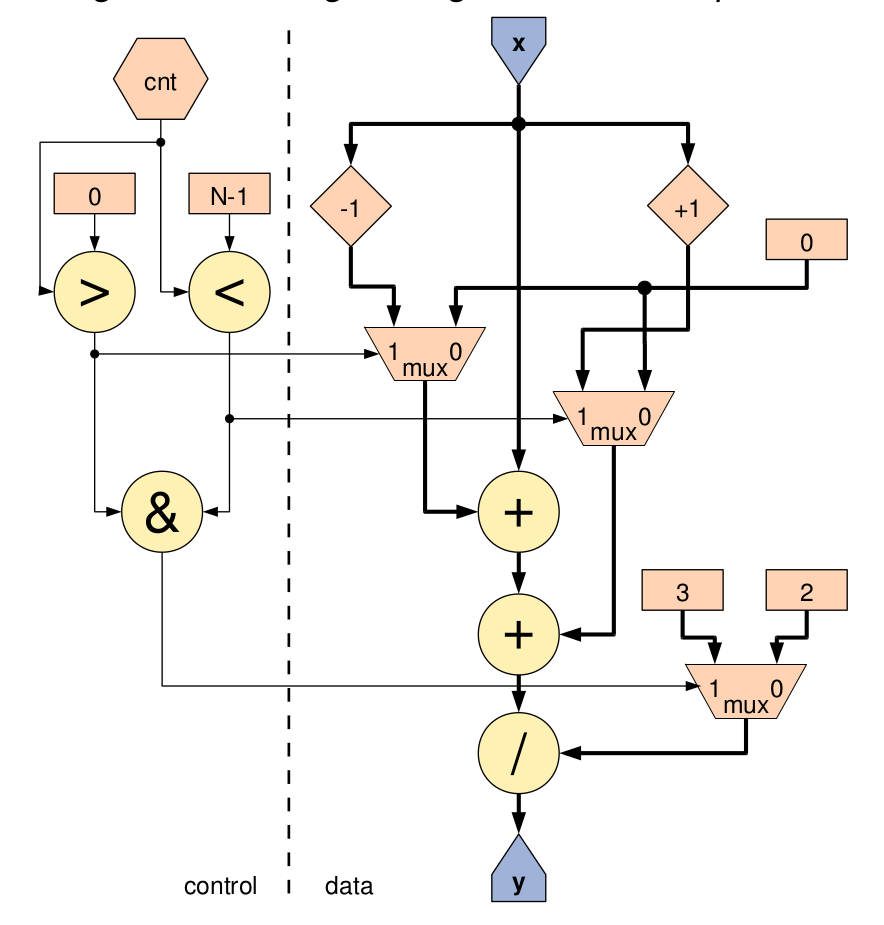
Trivial example : blurrer: compute the local 3-average:
HWType flt = hwFloat(8,24); HWVar x = io.input(”x”, flt ) ; HWVar x_prev = stream.offset(x, − 1); HWVar x_next = stream.offset(x, +1); HWVar cnt = control.count.simpleCounter(32, N); HWVar sel_nl = cnt > 0; HWVar sel_nh = cnt < (N − 1); HWVar sel_m = sel_nl & sel_nh; HWVar prev = sel_nl ? x_prev : 0; HWVar next = sel_nh ? x_next : 0; HWVar divisor = sel_m ? 3.0 : 2.0; HWVar y = (prev+x+next)/divisor; io.output(”y” , y, flt ) ;
| 48: (C) 2012-18, DJ Greaves, University of Cambridge, Computer Laboratory. |