Alternative Memory Bank Structures giving wider effective bus width.
Whether computing on standard CPUs or FPGA, memory bandwidth is often a main performance bottleneck.
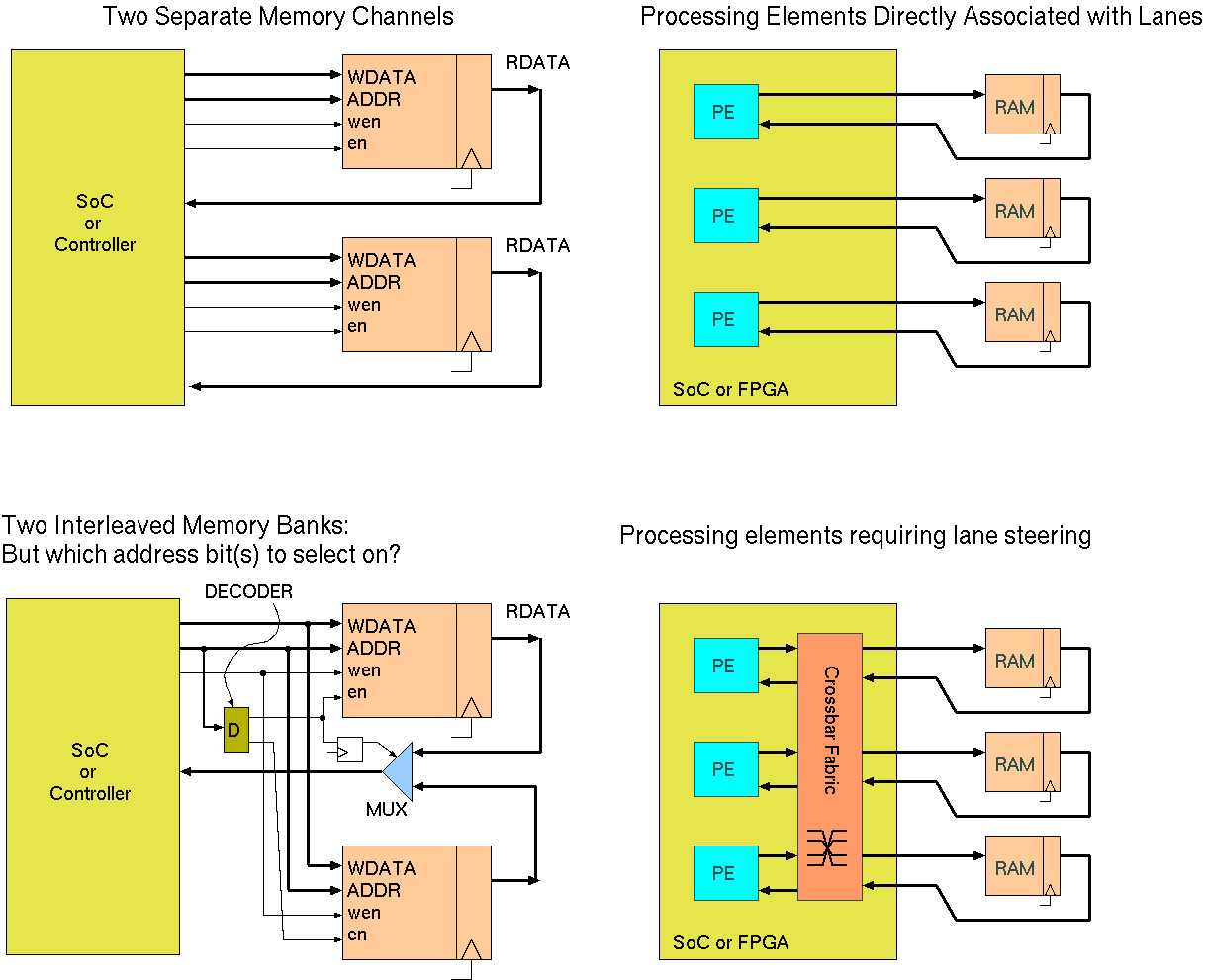
Given that data transfer rate per-bit of read or write port is fixed, two solutions to memory bandwidth are to use multiple banks or wide memories.
Multiple banks (aka channels) can be accessed simultaneously at different locations, whereas memories with a wider word are accessed at just one location at a time (per port). Both yield more data for each access.
Both also may or may not need lane steering or a crossbar routing matrix, depending on the application and allowable mappings of data to processing units.
The best approach also depends on whether the memories are truly random access. SRAM is truly random access, whereas DRAM will have different access times depending on what state the target bank (i.e. bit plane) is in.
With multiple RAM banks, data can be arranged randomly or systematically between them. To achieve `random' data placement, some set of the address bus bits are normally used to select between the different banks. Indeed, when multiple chips are used to provide a single bank, this arrangement is inevitably deployed. The question is which bits to use.
Using low bits causes a fine-grained interleave, but may either destroy or leverage spatial locality in access patterns according to many details.
Ideally, concurrent accesses hit different banks, therefore providing parallelism. Where data access patterns are known in advance, which is typically the case for HLS, then this can be maximised or even ensured by careful bank mapping. Interconnection complexity is also reduced when it is manifest that certain data paths of a full cross-bar with never be used. In the best cases (easiest applications), we need no lane-steering or interconnect switch and each processing element acts on just one part of the wide data bus. This is basically the GPU architecture.
| 25: (C) 2012-18, DJ Greaves, University of Cambridge, Computer Laboratory. |