Human Computer Interaction Notes
Advanced Graphics & HCI
Dr Alan
Blackwell
University of Cambridge
Computer Laboratory
Part II course 2000-2001
0.1. Introduction
With the exception of some embedded software and operating system code, the success of a software product is determined by the humans who use the product. This module deals with theoretical and practical techniques for making successful and usable software. Many computer science students enjoy creating attractive "sexy" graphical displays for their software, but that is not our main concern here. People's idea of what is attractive depends largely on fashion; the software of ten years ago was considered attractive at the time, as were the cars of twenty years ago. The sexiest software of today will look just as old-fashioned before long. Instead, we are interested in the principles that make software more usable for its purpose. Software that is usable for its purpose is sometimes described by programmers as "intuitive" (easy to learn, easy to remember, easy to apply to new problems) or "powerful" (efficient, effective). These terms are vague and unscientific, but they point in the right direction. The rest of this module presents scientific approaches to making software that is "intuitive" and "powerful".
The field of human-computer interaction (HCI) is rather different from other areas of computer science. In order to make software that is easy to learn, easy to remember and easy to apply to new problems, we must understand something about learning, memory and problem solving. These are topics that are normally taught in cognitive psychology departments rather than computer science (although computer scientists who work in artificial intelligence are very familiar with relevant psychological principles). The other part of the field - how to make products that are efficient and effective - is the central concern of engineering, and is more often taught in engineering departments. Human-computer interaction is therefore one part psychology and one part engineering - some computer scientists find that this is hard work compared to what they are used to. HCI research is mostly about experimental studies and design techniques rather than mathematics or algorithms, so serious study of HCI involves more than just new subject matter - it involves new ways of studying. This includes the possibility that there may be alternative theories, all of which are useful, but none of which are "right".
HCI helps us to understand why some software products are good and other software is bad. But sadly it is not a guaranteed formula for creating a successful product. In this sense it is like architecture or product design. Architects and product designers need a thorough technical grasp of the materials they work with, but the success of their work depends on the creative application of this technical knowledge. This creativity is a craft skill that is normally learned by working with a master designer in a studio, or from case studies of successful designs. A computer science course does not provide sufficient time for this kind of training in creativity, but it can provide the essential elements: an understanding of the users' needs (from psychology), and an understanding of potential solutions (from engineering). Along the way we will meet some case study material, and more is available online (see the reference to the Interface Hall of Shame), but much of the content of this course will only come alive once you have graduated and are working alongside experienced software designers.
0.2. Overview
This course includes both theoretical material and practical approaches to designing user interfaces. In the lectures, the two will be combined. There are four theoretical themes, each one of which will be presented together with relevant research background material and end with the description of a practical design approach that has been developed from that material. In these notes, all of the theoretical material will come together for continuity, and the four design methods will be described in more detail toward the end of the notes.
The theoretical topics include:
In Theme 1:
In Theme 2:
In Theme 3:
In Theme 4:
The four design methods are:
At the end of the notes, some further resources are given - reviews of the set texts, some other useful books, and a list of online resources. There are also a few exercises designed to provide some insight into how practical usability evaluation might be attempted in a commercial context. It is important to attempt at least one of these exercises before starting supervisions for this course - previous experience with this material suggests that there is little benefit in supervisions unless a range of these exercises have been attempted by the supervisees.
Theme 1 - Interaction Techniques
1.1. Styles of interaction in the development of user interfaces
Technical descriptions of human-computer interaction have always been heavily influenced by the physical interaction devices that are available. The earliest digital computers were scientific instruments. Interacting with them involved configuration of the equipment (often mechanical reconnection via wiring panels), setting parameters on a control panel (using switches and dials) and monitoring of processes (via lamps and cathode ray tubes). Improvements in usability would be made in the same way as for the usability of any other machine - arranging the control panel more conveniently, or providing more switches for configuration.
1.1.1. Algebraic Languages
Once programs started to be designed and written at a desk and loaded into the computer from paper tapes by technicians, interaction with the machine became more like a mathematical activity. The first programming language, FORTRAN, was a "formula translator" that automatically interpreted the natural mathematical terminology of these users.
1.1.2. Data Files
Commercial data-processing tasks used an interface that was already established for data storage and processing: punched cards. Keypunch operators created data records using card-punch machines. Punch cards were also used to store programs with one line on each card. Programmers used to walk around carrying file-boxes of cards, and interaction became more like a paper record-keeping operation.
1.1.3. Command Lines
Computers could interact directly with an operator via a teletype terminal. These were used first by the operators of large computers, and then for interacting directly with the first generation of mini-computers. As you typed, the characters were printed so that you could see your input. The computer (or person) at the other end had to wait for the end of a line, then send a line in response to be printed at your end. This alternation encouraged the view of the computer as another person on a communicating teletype, and interaction as a dialogue with an obedient subordinate. The user issues a command, and the response from the subordinate is an acknowledgement of the command.
1.1.4. Line Editors
This was the style of interaction in use when users started to edit text on-line, rather than by inserting or replacing punch cards in a card file. When using a command-line editor, the user issued commands (paraphrased here) such as:
Of course the actual commands were more like "P12 S/Z/X D13". The ideal of human computer interaction was to make this dialogue seem as much as possible like dialogue with another person - ideally by making the commands natural English sentences - while not requiring too much typing. Command languages (see the UNIX command line for an example) were therefore optimised to be brief, but easy to remember and structured like English with verbs and objects.
1.1.5. What You See Is What You Get
Teletypes used lots of paper, and this was not really necessary when so many commands were only of transient interest. The glass teletype or video display terminal displayed the operator commands and teletype responses on the screen, (sc)rolling up the screen like the paper unrolling from a teletype. This was OK for interaction dialogue, but advanced devices allowed control codes that would write characters anywhere on the screen. The next innovation was a "full-screen" editor that showed a whole lot of text at once, rather than one line at a time. They incorporated the idea that the user really needs to see the product they are working on, rather than a transient sequence of commands and responses - What You See Is What You Get or WYSIWYG.
1.1.6. Modeless Interaction
The first full screen editors were like front-end viewers added onto existing line editors (the vi editor under UNIX was a particularly successful example of this). Many of the commands were issued from a command line at the bottom of the screen, and the user had to toggle between command mode and edit mode. The user interface behaved quite differently in each mode, and it was difficult to remember which mode you were in - often with unpredictable results. More advanced editors such as EMACS attempted to provide a modeless interface, in which a given keystroke would have the same effect in any context within the interface.
1.1.7. Menus
When users forgot a command, many command line interpreters could send a set of choices to the teletype, so that the user could enter the code for the one he or she wanted. Video terminals with cursor addressing meant that instead of entering a code, the user could move the cursor to the place on the screen where the command was displayed, and press a function key to act on it. This was a breakthrough in both reducing typing and also allowing longer, natural language commands. At the same time, interaction became far less like a dialogue.
1.1.8. Pointing devices
Moving the cursor to the appropriate position in a menu was facilitated by the development of the light pen for pointing at locations on the screen, and of the mouse for specifying motion along two axes.
1.1.9. Graphical displays
The majority of video display terminals were only capable of displaying 25 rows of 80 alphanumeric characters, but some technical applications required the display of graphical information. Graphical terminals could interpret a variety of complex languages that specified the points and lines to be displayed, forming engineering drawings or electronic schematics. Graphic terminals often switched between teletype mode and graphic mode, rather than drawing command text anywhere on the screen.
1.1.10. Icons and windows
The development of the bit-mapped display in personal computers allowed the display of more realistic pictorial images. When combined with a mouse, programs could be controlled by pointing at images. The symbolic content of nodes in schematic diagrams could now represent things that were originally abstract components of a formulaic sentence. The idea of making pictures of abstract concepts, named by analogy to religious paintings of abstract beings, was described as icons.
1.1.11. Summary
This brief history demonstrates that the main theoretical approaches to user interface - algebraic languages, dialogues, WYSIWYG, icons - all depended primarily on developments in I/O devices. Some theories of HCI now appear less important than they once did, and it is possible that future technical developments will be just as radical. When we are all interacting with our wristwatches by speaking to them, studies of accuracy in pointing will seem far less important. Nevertheless, this deepening historical heritage gives us a rich perspective for analysing the way that we use computers.
Our current generation of HCI theory is based on analysis of the current generation of technology: windows, icons, menus and pointers (the WIMP interface). This generation does represent some very significant advances over command line and teletype interfaces. The most radical of these is that the "command" is no longer the central unit of interaction. Instead, the object of the user action (represented by an icon) is the central unit of interaction. This is derived from early computer graphics systems (notably Sutherland's Sketchpad), in which a light pen could be used to point at and manipulate parts of the drawing. David C. Smith in his 1977 Stanford PhD recognised that graphical objects could be used as iconic representations of abstract data, and that manipulating the graphical object might correspond to commands on that data. This idea was developed further in the Xerox Palo Alto Research Center, from where it was adopted by first Apple Computer then Microsoft. Smith's original proposal was a little vague about the benefits of the approach, but the Xerox project analysed it in depth. A psychologist, Ben Shneiderman, expressed the important attributes of direct manipulation in 1983:
It may seem surprising that these desirable attributes were not always recognised. They certainly seem obvious now that we are familiar with graphical user interfaces, but they are clearly not true of interaction techniques such as the UNIX or DOS command line. You may like to compare your favourite command line to a graphical desktop, and see how it compares on each of these criteria.
1.3. Style Guidelines
Competing operating system vendors are now very concerned that their systems should appear easy to use. Unfortunately, users' experience of usability is often through programs from third party software companies which the operating system vendor does not have control over. In order to make this software easier to use, operating system suppliers, starting with Apple, therefore publish style guidelines advising developers on how to make usable applications. The current version of the guidelines published by Microsoft gives some general advice on usability that is almost exactly the same as that published by Shneiderman in 1983 (although with slight differences in terminology including "persistence", "forgiveness" and "feedback" rather than "continuity", "reversibility" and "visibility").
However the main part of these style guides is concerned with using the functions of the user interface library to make applications look part of a family. The Macintosh guidelines include precise instructions on shape and size of buttons. The Windows guidelines describe the standard appearance of windows, menus, icons and toolbars as well as internal interfaces such as use of the registry or OLE. These standards do have some implications for usability - they make it easier for users to recognise the behaviour of certain types of controls - but they do not address many important aspects of usability. As Newman and Lamming point out (15.3.2), they sometimes offer contradictory advice. Suns' Open Look guidelines recommend placing menu items in order of the process being carried out, but elsewhere say that most frequently used items should be at the top. Finally, style guides have an increasing function of providing corporate branding for the operating system suppliers, and this sometimes overshadows usability concerns.
1.4. Heuristic evaluation
If a programmer has more ambition than wanting to create a generic Windows (or Macintosh or Motif) application, how can he or she apply the lessons from the years of experimentation with different interfaces? One approach is to collect all the lessons that have been learned through different stages of hardware development, and then test in a systematic way whether our new design takes those lessons into account. This first theme has given a review of the most important of these historical discoveries - they include the use of command languages, dialogues, WYSIWYG, menus and direct manipulation. Nielsen suggested that the usability of a system should be evaluated by a panel of experts, each working from a list of usability heuristics. Every aspect of the system function could then be compared to the things we know about usability, and the results aggregated in order to direct the system design. The practical arrangements for conducting heuristic evaluation, together with a suggested set of heuristics, are covered in the first of the analysis technique descriptions later in these notes.
Theme 2 - Psychological User Models
2.1. The need for user models
The first theme described the historical development of computer user interfaces, and the way that this has provided us with a set of design guidelines and heuristics for developing usable software. It hinted that this development involved psychologists who analysed the requirements of human users, but gave no details of the type of research conducted by those psychologists. A great deal of this research was actually conducted here in Cambridge, after the establishment of the Applied Psychology Unit in Chaucer Road. The APU was created in response to problems observed during the second world war - as military hardware became more technical, its performance was often limited by the abilities of the operators (e.g. gunners, pilots or tank drivers) rather than specification of the machines. The APU recruited researchers from experimental psychology who could apply earlier discoveries about human perception and movement, and who also conducted experiments on volunteers from a nearby military establishment.
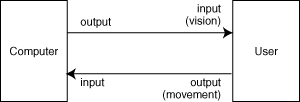
This concern with machine interaction resulted in the borrowing of theory from the machine engineers, applying it to the performance of the machine operators. The engineering theories of closed loop control and information transfer described complex systems in terms of the dynamics of interacting subsystems. Research into usability therefore described the operators themselves as further black box subsystems, having inputs (observing the world, and the state of the machine), and outputs (controlling the machine). In order to understand the dynamic performance of the whole system, it was clearly necessary to understand the human portion of the system as well as the machine. Some aspects of these communication channels, such as visual perception of simple shapes and lights, had been studied for over 50 years. Others required new research which was conducted in Cambridge and at the other research centers creating the discipline of cognitive psychology. The set of black boxes that have resulted bear a rather close resemblance to generic computer architectures - they include models of visual input, of physical output, of memory, and of a problem-solving processor that uses that memory for intermediate results.
The basic characteristics of human vision are highly important to computer graphics, because the ultimate goal of graphics is creating a visual stimulus sufficient for human observers to see a coherent and meaningful display. Some of this material was therefore covered in the Part 1B Computer Graphics and Image Processing course. The Part 1B course described the structure of the human retina, which is composed of brightness sensing rods and colour sensing cones. The cones are concentrated in the foveal region, which provides finer resolution of detail. The characteristics of colour vision can be described in terms of colour spaces that quantify and linearise the subjective impressions resulting from different levels of stimulation of red, blue and green sensing cones. Our eyes do not simply register colour planes, however. They adapt to different levels of brightness, are sensitive to local contrast, and impose quantisation over physically uniform intensity distributions.
2.2.1. Marr's theory of vision
These results do not give us a great deal of information about how we interpret the signals coming from our eyes, and are thus of limited use for describing interaction with machines (beyond our ability to observe flashing coloured lights). David Marr proposed a series of black boxes which were involved in interpreting this visual input. The first level is the retinal image. This is processed (by nerve cells in the retina) to find the boundaries between relatively uniform regions. The result of this edge filtering is a primal sketch. The structure of the primal sketch can be analysed to form a 2½D sketch in which 2D regions are identified as being in front of or behind other regions. Finally this intermediate representation is resolved into a 3D model of the object being perceived.
Marr's theory of vision can be regarded as the inverse of the computer graphics process in which 3D models are converted into two dimensional surfaces and edges for rendering. It provides us with a basis for simulating and modelling the process of understanding visual displays. It is certainly adequate for describing the way that we interpret window displays, which are essentially 2½ dimensional. The use in display windows of uniformly coloured regions together with shadows to disambiguate stacking order means that we can interpret these as being meaningful objects.
2.2.2. Gestalt laws of perception
Marr was more concerned with perception of the physical world than with two dimensional displays, but many interesting characteristics of display interpretation had already been established by German Gestalt psychologists before 1920. These gestalt principles of visual organisation include the principles of:
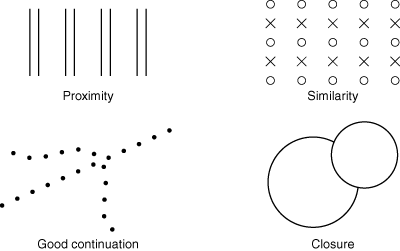
Gestalt laws of perception are clearly critical to graphic design, and are important characteristics of a two-dimensional user interface.
2.2.3. Visual tasks
There has been substantial research into human performance for basic visual tasks. Many of these results are relevant to perception of displays, but are too detailed for an introductory course. Some relevant topics that are covered at length in specialist textbooks include:
Depth perception - our ability to perceive distance in the physical world relies on many different perceptual factors. The basic mechanism of depth perception, binocular stereo vision, is not very reliable, so we supplement it with a wide variety of monocular depth cues. On current computer displays these cues are the only means of depth perception, as the display is rendered on a flat screen.
Face recognition - we are able to carry out certain types of image segmentation very quickly. Processing of human faces within a scene occurs far more quickly than other types of scene analysis, and we can perform some high-precision tasks such as identifying direction of gaze with great accuracy.
Visual search - when we need to identify one object among a field of different objects, several effects are relevant. Finding a given letter in a list of letters varies linearly with the length of the list, but we can find a differently coloured letter in near-constant time. Other visual "pop-out" effects include the speed with which we can find local variations in brightness, or identify a shape with a different orientation in a field of identical shapes. One particular measure of visual search was discovered at the Cambridge Applied Psychology Unit by a researcher working on gun aiming: Hick found that the time to find one item among a number of similar items (i.e. discounting pop-out effects) is related to number of items by a log function, now called Hick’s Law:
T = k log2 (n + 1)
2.3. Models of physical "output"
Psychological studies of mental "outputs" have typically concentrated on speech more than physical action. However human speech is currently less relevant to HCI, as long as speech-operated interfaces are relatively uncommon. The dynamics of reaching actions are also relatively well-understood, however, because they are mechanically quite predictable. We know that reaching out to pick something up involves a high speed approach phase followed by a slower homing phase. While moving, our hands already form the appropriate shape for grasping the object.
This kind of study is less relevant to current user interfaces, however. Most interesting are studies of typing, and studies of pointing. Studies of typing allow us to investigate some urban myths of the user interface. For example, the "qwerty" keyboard is not so inefficient as many computer scientists believe. People can make successive strikes more quickly with alternate hands than with the fingers of the same hand. The qwerty keyboard happens to facilitate this quite well, so that even non-typists (in 1981 - before keyboards were as widespread as today) could type far more quickly on a qwerty keyboard (1.08 letters/s) than an alphabetic one (0.65 letters/s).
The process of pointing at a target was of particular interest when mice were first introduced. How was it possible to compare the speed of pointing at something with a mouse to the speed of typing a command, or making a series of cursor movements? Fortunately, this is another result that was established during early research on machine models of human motion. Fitts' law describes the fact that the time it takes to point at a given location is related to the size of the target and to the distance from the current hand position to the target.
Fitts experiment involved two targets of variable size, and separated by a variable distance. Experimental subjects were required to touch first one target, then the other, as quickly as they could. The time that it takes to do this increased with the Amplitude of the movement (i.e. the distance between the targets) and decreased with the Width of the target that they were pointing to:
T = K log2(A / W + 1)
Fitts' law has been found to apply quite well to pointing operations with a mouse, and can hence be used to predict human performance when using menu interfaces.
2.4. Models of memory
One of the most famous findings in cognitive psychology research, and the one most often known to user interface developers, is an observation by George Miller in 1956. Miller generalised from a number of studies finding that people can recall somewhere between 5 and 9 things at one time - usually referred to as "seven plus or minus two". Surprisingly, this number always seems to be about the same, regardless of what the "things" are. It applies to individual digits and letters, meaning that it would be very difficult to remember 25 letters. However if the letters are arranged into five 5-letter words (apple, grape ), we have no trouble remembering them. We can even remember 5 simple sentences reasonably easily. Miller called these units of short-term memory chunks. It is rather more difficult to define a chunk than to make the observation - but it clearly has something to do with how we can interpret the information. This is often relevant in user interfaces - a user may be able to remember a sequence of seven meaningful operations, but will be unable to remember them if they seem to be arbitrary combinations of smaller elements.
Short term memory is also very different from long term memory - everything we know. Learning is the process of encoding information from short term memory into long term memory, where it appears to be stored by association with the other things we already know. Current models of long-term memory are largely based on connectionist theories - we recall things as a result of activation from related nodes in a network. According to this model, we can improve learning and retrieval by providing rich associations - many related connections. This is exploited in user interfaces that mimic either real world situations or other familiar applications.
A further subtlety of human memory is that the information stored is not always verbal. Short term memory experiments involving recall of lists failed to investigate the way that we remember visual scenes. Visual working memory is in fact independent of verbal short term memory, and this can be exploited in mnemonic techniques which associate images with items to be remembered.
2.5. Models of problem solving
Basic models of human problem solving are completely familiar to computer scientists who have studied research into artificial intelligence. The earliest models of problem solving in cognitive psychology are derived from the 1969 work of Ernst and Newell on a Generalised Problem Solver. The GPS operated in a search space characterised by possible intermediate states between some initial state and a goal state. Problem solving consisted of finding a series of operations that would eventually reach the goal state. This involved recursive application of two heuristics: A) select an intermediate goal that will reduce the difference between the current state and the desired state, and B) if there is no operation to achieve that goal directly, decompose it into sub-goals.
This model of problem solving as a recursive hierarchy of sub-goals has been widely adopted as a basis for the analysis of human problem solving. In physical tasks, the basic operations (and hence the leaves of the sub-goal tree) are physical actions. The required difference reduction can be deduced from perceptual (visual) input. The difficulty of the problem can be analysed in terms of the depth of the sub-goal tree; if the tree is too deep, the limited capacity of working memory will result in a "stack overflow" so that we forget what we should do next to finish the problem.
2.6. System models for HCI
2.6.1. The Model Human Processor
These results from psychological research give us the basic elements that we need to describe the whole interaction loop of the computer and its user. We simply need to combine the observations that have been made regarding performance of the black boxes for visual perception, motion, and cognitive processing. This was precisely the approach taken by Card, Moran & Newell, who proposed a minimal Model Human Processor for predicting the speed with which users could carry out tasks on a computer. They assumed that the task could be broken down into unitary perceptual events, motion events, and cognitive events, and that the total time required to carry out a sequence of events could be estimated by adding the time usually required for each type of event. Based on earlier studies, they observed that perceiving a stimulus takes somewhere between 50 and 200 ms (typically 100), that making a simple decision takes somewhere between 25 and 170 ms (typically 70), and that making a tapping motion takes somewhere between 30 and 100 ms (typically 70). They proposed a number of other elaborations, but the essential parameters are:
tp = 100 [50 ~ 200] ms
tc = 70 [25 ~ 170] ms
tm = 70 [30 ~ 100] ms
The total time required for some user interface action is then predicted by the number of times each type of event must occur in the performance of that action.
T = nptp + nctc + nmtm
2.6.2. Keystroke Level Model
Card, Moran & Newell refined their model for use as a system design tool that could be used by designers to compare the operation speed of alternative design. The keystroke-level model added operators to describe specific types of movement - keystrokes, pointing with a mouse and drawing. They added the system response time and the time to make mental preparations, and defined the circumstances in which mental preparation would be required. The keystroke level model is described in more detail in the second of the analysis technique sections later in these notes.
2.6.3. GOMS
The keystroke level model predicts only basic actions, not complex task procedures. The GOMS model (Goal, Operators, Methods and Selection) extended KLM further, with a detailed model of problem solving based on the Newell's earlier work on the General Problem Solver. The operators, or basic actions taken by the user, corresponded to the components of the keystroke level model. The rest of GOMS described the process of selecting operators in order to accomplish a complex task. An experienced user would be expected to have some repertoire of methods - sequences of operations that are known to accomplish a particular goal. Where more than one method can be used to achieve the same goal, the model predicted that extra time would be required for selection - choosing the best method to use. GOMS attempted to provide quantitative models of the process of goal hierarchy decomposition, the working memory required to store goals and working values, and also the learning processes that are involved in acquiring new methods.
The implication of the GOMS method was that the requirements of the user can be predicted exactly from the nature of the software application. It should be possible to predict exactly what actions the user will take in advance by simulating their reasoning with the GOMS model. Having done that, the user interface could simply be designed to provide the most efficient path through the goal hierarchy. As it happens, this theoretical goal seems to have been too ambitious. GOMS provided a very neat fit of a psychological model to software design, but this convenience can be attributed partly to the fact that the GPS model of human problem solving was itself a computer program in the first place. At the level of complexity of real user interfaces, the behaviour of early AI simulations like GPS bears little resemblance to the behaviour of real humans.
2.6.4. Recent complex models
HCI research is continuing to develop more complex models of human cognitive processes, in the hope that they can be used to predict usability through automated analysis. This course will not give any further consideration to programmable user models, which are generally based on the latest generation of computer models of human cognition. The Applied Psychology Unit in Cambridge was a major centre of this type of work in the 1980s and early 1990s. Richard Young's work on Programmable User Models continues at the University of Hertfordshire.
Phil Barnard, still at the Applied Psychology Unit (now Cognition and Brain Science Unit), is developing a cognitive model that describes cognitive processes beyond the domain of HCI. His Interacting Cognitive Subsystems model describes human cognitive processing in terms of nine cognitive subsystems having a common structure. Jon May has used the ICS model to describe interaction processes including attention within a display, different levels of mental representation and the interaction of knowledge with task structure. He proposes that usability can be analysed by comparing changes of state in task structure to mental structure using transition path diagrams. This method is described in a tutorial available online: http://www.shef.ac.uk/~pc1jm/papers/guide1997.pdf
Theme 3 - Evaluation of Cognitive Models
The second theme described the many attempts to construct exact analytical models of the human user, in order to make precise mathematical estimates of the time required to operate a user interface. These models are based on empirical data from psychological experiments, but the granularity of behaviour that is described has been at such a low level that it can only be used to analyse very simple and uninteresting actions. As a result, HCI practitioners have adopted a set of observational, experimental and design techniques that are closer to the level of granularity we normally use when discussing complex human tasks.
Mental models research attempts to describe the structure of the mental representations that people use for everyday reasoning and problem solving. Common mental models of everyday situations are often quite different from scientific descriptions of the same phenomena. They may be adequate for basic problem solving, but break down in unusual situations. For example, many people imagine electricity as being like a fluid flowing through the circuit. When electrical wiring was first installed in houses, it appeared very similar to gas or water reticulation, including valves to turn the flow on and off, and hoses to direct the flow into an appliance. Many people extended this analogy and believed that the electricity would leak out of the light sockets if they were left without a lightbulb. This mental model did not cause any serious problems - people simply made sure that there were lightbulbs in the sockets, and they had no trouble operating electrical devices on the basis of their model.
The psychological nature of unofficial but useful mental models was described in the 1970s, and these ideas have been widely applied to computer systems. Young's study of calculator users in 1981 found that users generally had some cover story which explained to their satisfaction what happened inside the device. Payne carried out a more recent study of ATM users, demonstrating that even though they have never been given explicit instruction about the operation of the ATM network, they do have a definite mental model of data flow through the network, as well as clear beliefs about information such as the location of their account details.
The basic claim of mental models theory is that if you know the users' beliefs about the system they are using, you can predict their behaviour. The users' mental models allow them to make inferences about the results of their actions by a process of mental simulation. The user imagines the effect of his or her actions before committing to a physical action on the device. This mental simulation process is used to predict the effect of an action in accordance with a mental model, and it supports planning of future actions through inference on the mental model. Where the model is incomplete, and the user encounters a situation that cannot be explained by the mental model, this inference will usually rely on analogy to other devices that the user already knows.
If we were to describe this in terms of computational problem solving models, we have to recognise that users are working simultaneously in two different problem state spaces. One of the spaces describes the actual structure of the users' goals, which may not explicitly recognise the computer at all. The other describes their understanding of the device state space. These two state spaces are yoked together, so that moves in one state space can only be accomplished by equivalent moves in the other. If we use this model to analyse usability, we must also recognise that the user's model of the device will not be the same as the designer's model of the device - mental model theory attempts to construct an explicit characterisation of the user's model as a basis for design.
It should be clear that mental models theory is far more complex than the Model Human Processor and GOMS theories described in the second theme. Although the user model is very likely different to the designer's model, and may be "unscientific", it can still be quite complex, with a complex set of mappings between goals and device that may be different for different users. It is very difficult to make a predictive computational simulation of the mental model and its effects on users' problem solving. Instead, we must study the behaviour of users. We assume that system users generally have good reasons for their actions, and orient our research toward finding out what those reasons are.
3.2. User-oriented design methods
The remainder of this theme describes some of the approaches that have been applied to the study of system users for usability purposes.
Prototyping is becoming increasingly important as a software design method, particularly addressing the problems of developing user interfaces within a strict waterfall development model. Companies that use waterfall models have placed increasing emphasis on accurate portrayal of the user interface at the specification phase, after finding that the majority of specification changes arise from client not understanding the requirements for user functionality. In terms of mental models theory, this could be expected - clients who have no image of the interface that they will operate are unlikely to have a useful mental model of system behaviour.
If the system can respond in complex ways, it is difficult to appreciate this from static figures in a specification, so the specification phase of projects often uses rapid prototyping tools to construct a functional user interface. This prototype can be demonstrated to clients and used as a basis for discussion. If a spiral development model is adopted rather than a waterfall, the prototype can be refined iteratively until the full system functionality is achieved. Incremental prototyping requires that the rapid prototyping tool also meets the engineering requirements of the final system. If such a tool is not available, an alternative is deep prototyping, in which one aspect of the system functionality is fully implemented before developing the rest of the interface.
These common approaches to prototyping are quite different to the prototyping techniques that have been found to be successful in developing novel user interfaces. Many product designers believe that creativity in the product design process is directly related to the number of prototypes produced. HCI research similarly emphasises techniques for developing a large number of prototypes, exploring different possible solutions, and evaluating the usability of alternatives. This is in contrast to incremental prototyping techniques, which encourage cost-saving by using the first solution regardless of its usability properties.
Investigation of multiple prototypes requires low cost techniques for producing prototypes. Rather than implementing realistic system functionality, these often use generic graphic design tools with some scripting functions: early HCI research often used Apple Hypercard, and more recent work uses Macromedia Director. An even more radical proposal is low-fidelity prototyping, in which the prototype user interface is made using controls built from glue and paper. During evaluation, the functionality can be implemented using the Wizard of Oz technique - a person simulates the machine by responding to user actions with the display of new (paper) screens.
The objective of building multiple prototypes is to investigate design alternatives through evaluation with actual users. The next section describes some techniques for making this evaluation.
3.3.1. Controlled experiments
The most common empirical method used in HCI is the controlled experiment. An experiment is based on a number of observations (measurements made while someone is using an experimental interface). A typical measurement might be "How long did Fred take to finish task A?" or "How many errors did he make"? A wide range of alternative measurements are possible, including heart rate or other exotic biological data. However we most often assume, as in the discussion of KLM and GOMS, that it is a good thing if interfaces allow us to do something quickly.
A single observation of speed is not very interesting, however. If Fred did the task again, he would take a different amount of time, and if someone else did it, it would take an even more different amount of time. We therefore collect sets of measurements, and compare averages. The sets might be multiple observations of one person performing a task over many trials, or of a range of people (experimental subjects) performing the same task under controlled conditions. As with most human performance, the measured results will usually be found to have a normal distribution.
A typical HCI experiment involves one or more experimental treatments that modify the user interface. A very simple example might test the question: "How long does Fred take to finish task A when using a good UI, compared to a bad UI?" The result will often be that the good UI is usually faster to use than the bad, but not in every trial. If we plot the measurements, we find two overlapping normal distributions, and we must therefore compare the effect of treatments relative to the spread in the population distribution. We need to know whether the difference between the averages is the result of normal random variation, or the effect of the changes we made to the user interface.
This involves a statistical significance test such as the t-test. The t-test and other similar tests answer the question "What is the probability that the observed difference in means is due to random variation?". This is called the null hypothesis, and we generally hope that the answer will be "the probability is very low" - i.e. that the observed difference is most likely because we designed a really good interface. In HCI research, we usually insist that the probability of the result being due to random variation (p) is less than 0.05, or 5%. Good quality research results are normally based on experiments with significance values p < 0.01.
Sources of variation in reaction time
Some people find it surprising that we can draw scientific conclusions from measurements that are different every time we make them. This is rather fatalistic. We all agree that people are different. If there were no way to measure the value of a user interface for a wide range of different people, there would be no chance of progress in user interface development. It is important, however, that we are aware of the sources of variation in the measurements.
These include:
The statistical techniques used in sophisticated experiments isolate these kinds of factors, and try to account for them separately in order to gain a good understanding of the effects of the experimental treatments. Fortunately over a large number of trials all of these factors tend to combine into a pattern of random variation within the normal distribution, as predicted by the central limit theorem. The central limit theorem and further null-hypothesis testing techniques are beyond the scope of this course. A useful introductory text on experiment design is Robson's Experiment, Design and Statistics in Psychology. A briefer summary of the most important principles is given in chapter 10 of Newman and Lamming.
A more serious concern in this kind of research is the validity of the result. Would the observed effect generalise to other situations besides the precise context of the experiment? What exactly was the mechanism by which the effect occurred? Is there some established HCI work or psychological theory that can explain it? Could it be replicated if you repeated the experiment with slight variations (older users, for example, or a different model of computer)? In order to avoid these potential criticisms, HCI researchers often try to use experimental tasks and context that have good environmental validity - they are as close as possible to the situation in which the interface will really be used.
3.3.2. Other empirical techniques
Hypothesis testing is a very useful technique for making quantifiable statements about improvements in a user interface. It also hides a lot of useful information, however. Experimental subjects usually have a lot of useful feedback about the interface that they are trying, but there is no easy way to incorporate this into statistical analyses. Instead, we use a range of other techniques to capture and aggregate interpretative reports from system users.
Surveys
Surveys include a range of techniques for collecting report data from a population. The most familiar types of survey are public opinion polls and market research surveys, but there are a much greater range of survey applications. Surveys are usually composed of a combination of closed and open questions. Closed questions require a yes/no answer, or a choice on a Likert scale - this is the familiar 1 to 5 scale asking respondents to rank the degree to which they agree with a statement. Closed questions are useful for statistical comparisons of different groups of respondents. In open questions the respondent is asked to compose a free response to a the question. The latter requires a methodical coding technique to structure the content of the responses across the population, and is particularly useful for discovering information that the investigator was not expecting.
Questionnaires
Questionnaires are a particular type of survey. (Interview studies of a sample population are also a form of survey). Questionnaires are generally used to gather responses from a larger sample, and can be administered by email as well as on paper. A discussion of the issues that can be encountered in questionnaire studies is available on-line at: http://kmi.open.ac.uk/people/paulm/summer98/question.html.
Think aloud studies
Much cognitive psychology research, including some basic research on mental models, is based on think-aloud studies, in which subjects are asked to carry out some task while talking as continuously as possible. The data are collected in the form of a verbal protocol, normally transcribed from a tape recording so that subtle points are not missed. Use of this technique requires some care. It can be difficult to get subjects to think aloud, and some methods of doing so can bias the experimental data. A detailed discussion of this kind of study is provided by Ericsson & Simon (1985).
Bad techniques
Some user interface developers use evaluation techniques that are practically useless. Unfortunately these techniques can even be found in some published research in computer science. This section is included as a warning to interpret such results with great care.
Simple subjective reports seldom give useful information about interface usability. When users are shown a shiny new interface next to a tatty old one, they will often say that they like the new one better, regardless of its usability. There are many circumstances in which a person's introspective feelings about their mental performance is not a good predictor of actual performance, so this type of report is unreliable as well as open to bias.
Some research proposes a usability hypothesis, then does not test it at all. "It was proposed that more colours should be used in order to increase usability". This type of statement is speculation rather than science; designing novel user interfaces without any kind of experimental testing is rather pointless.
There is a great deal of variation between different people in their ability to use different interfaces. This may result from different mental models, different cognitive skills, and many other factors. Any conclusions drawn from an observation of only one person must therefore be very suspect. Unfortunately, many user interfaces are developed based on observations of a single person - the programmer. The introspection of the user interface developer about his or her performance is seldom relevant to users.
The word "intuitive" is often used in discussion of user interfaces to summarise theories based on all the above.
3.4. Cognitive walkthrough
Cognitive walkthrough is an evaluation technique that incorporates a more sophisticated theory of user behaviour, incorporating an implicit user model and a theory of exploratory learning (Lewis and Polson's CE+ theory) based on empirical studies. Cognitive walkthrough is described in more detail in the third of the analysis technique sections later in these notes.
Theme 4 - Task-Oriented Analysis
This theme returns to the topic of the first, in that it is oriented more toward engineering than toward psychology. In fact it borrows techniques from other social sciences that have been found to be useful in software design.
4.1. Observation and task analysis
4.1.1. Structured interviews
Most software projects start with a series of meetings in which the system requirements are established. The agenda of these meetings is often concerned with many other matters than the user interface, however. In fact the people who will use the completed system may not even be present. Their requirements are defined by a representative (a system analyst for an internal project or a market researcher for a product) who may not have much experience of design for usability.
For this reason, user interface designers often conduct studies specifically to discover the requirements of the system users. One of the cheapest and most straightforward techniques is to conduct interviews with the users. Interviews must be carefully planned to be effective, however. They are generally more or less structured, encompassing a selected range of users, and taking care to encourage cooperation from users who may feel threatened or anxious.
A structured interview is based around a set of questions that will be asked of every interviewee. This need not necessarily be a long list, but it helps to collect data into a common framework, and to ensure that important aspects of the system are not neglected.
Newman and Lamming (5.2) suggest that an interview might be based around an initial enumeration of the user's activities, followed by explanation of his or her work methods and establishment of connections to other people and systems. It is also valuable at this stage to note potential measures of system usability, to discover unmentioned exceptions to standard procedures, and to capture any relevant domain knowledge.
4.1.2. Observational studies
Observational studies are a less intrusive way of capturing data about users' tasks, and can also be more objective. They involve more intensive work, however. An observational study of tasks that take place in a fixed location can be conducted by making video recordings which are transcribed into a video protocol. This protocol can then be used for detailed analysis of the task - relative amounts of time spent in different sub-tasks, common transitions between different sub-tasks, interruptions of tasks and so on.
Audio recordings can also be used for this purpose in certain domains, but these are less likely to be useful for task analysis than they are in think-aloud experiments.
If a task ranges over a number of locations, the investigator has no choice but to follow the subject, taking notes or recordings as best as possible. This is sufficiently difficult that ethnographic techniques are more likely than passive observation
4.1.3. Ethnographic field studies
Ethnographic study methods recognise that the investigator will have to interact directly with the subject, but while taking sufficient care to gain reasonably complete and objective information. An ethnographic study will attempt to observe subjects in a range of contexts, over a substantial period of time, and making a full record using any possible means (photography, video and sound recording as well as note-taking) of both activities and the artefacts that the subject interacts with.
4.1.4. Field tests
Some very successful products have carried out field testing of their products in addition to field studies at the specification phase. A well-documented example is the "follow-me-home" programme carried out by Intuit Inc. after the release of their Quicken product. Company researchers selected customers at random, when they were buying a shrink-wrapped copy of Quicken in a store. The researcher then went home with the customer in order to observe them as they read the manuals, installed the product, and used it for their home financial management. Intuit directly attribute the impressive success of the product to this type of exercise, and to the observational studies they carried out during initial product planning. (Quicken survived an assault from a Microsoft product priced at a predatory $15, and Microsoft later made a bid of $1.5 billion to buy Intuit).
User-centred analysis and design was once considered a fairly radical approach to software development, and books on the topic were more likely to be written by HCI researchers than by software engineers. Software design is now recognised as an important discipline with objectives that differ from the main objectives of computer science research. Software design is ultimately concerned with the needs of users, for reasons that were argued in the introduction to these notes.
This emphasis on system users when designing software is now recognised in the expanding use of object-oriented design methods based on the Universal Modelling Language UML. UML was created through the synthesis of several earlier design methods, including Ivar Jacobson's Object Oriented Software Engineering. The OOSE method prescribed the analysis of user activities in terms of use cases - specific scenarios for interactions with the system.
The use cases from OOSE have been adopted completely into UML. Use case analysis is the first stage of system design with UML, in which the behaviour of the system is described from the point of view of abstract actors. Actors represent abstract roles that users will take when interacting with the system, potentially structured according to classes of users. A use case is a narrative of some specific interaction that a specific actor conducts with the system.
Use cases are relevant through later stages of system design, as they can be used for the specification and validation of event traces involving different objects and subsystems. They provide sufficient formality for this description of system behaviour, but also provide a comprehensible unit of user interface functionality that can be discussed directly with clients and users. These attributes theoretically provide traceability of system implementation from specification through to the object-oriented design, and should therefore allow straightforward modification of the system when use cases are altered in response to maintenance requirements.
Various international research efforts are in place to integrate use case oriented design with more psychological approaches to HCI. At the time of writing, substantial progress is still awaited.
4.3. Cognitive dimensions of notations
The approaches to user-oriented design that have been described in this theme are rather atheoretical when compared to the psychological theories and methods in the previous themes. This is one of the main challenges for HCI - to integrate theoretically sound cognitive models into engineering design processes.
That is the aim of Green's Cognitive Dimensions of Notations, developed from 1989 onwards at the Applied Psychology Unit in Cambridge, and now at the Computer Based Learning Unit in Leeds. The cognitive dimensions are designed for use in an environment where designers accept that there can be no perfect user interface. As in all fields of engineering, every user interface design is a compromise. Even if a user interface were constructed that was perfectly suited to a particular user carrying out a particular task, it would not be perfect for other users and tasks. The cognitive dimensions therefore aim to provide designers with a working vocabulary in which they can discuss usability issues that are cognitively relevant while also being recognisably related to the potential solutions. The dimensions are partially independent, in a way that means trade-offs can be analysed, discussed and selected as appropriate for a particular design.
The cognitive dimensions framework describes the system under investigation as an information artefact - something that has been built for the processing, storage and communication of information. Every information artefact provides one or more notations in which the information being manipulated is encoded. The notation itself does not uniquely determine usability, however. The environment used to manipulate the notation is equally important. The complete system of the notation and the environment can be analysed to determine its usability for different tasks. This analysis process, and the dimensions themselves, are described in more detail in the last of the analysis technique sections later in these notes.
Research into HCI is an active field. Reports of recent research can be found in the annual proceedings of the ACM CHI conferences called Human Factors in Computing Systems, and in a range of specialist journals including SIGCHI publications, the International Journal of Human-Computer Studies, Human-Computer Interaction, Behaviour and Information Technology and others.
There are several important sub-fields which have expanded sufficiently to have their own conferences and research groups. Some examples of these significant areas are:
4.4.1. Computer supported cooperative work
Traditional HCI research has focused on a single user sitting in front of a computer, and has neglected the environment that the user is working in. Most users of complex computer systems do not work alone, but in organisations where they must cooperate with many other users. CSCW research investigates how the user interface can support this collaboration.
One stream of CSCW relies on a structured analysis of human collaboration, using software to organise online discussion into this structure. Design discussions, for example, can often be broken down into a series of questions that need to be addressed, options for addressing each question, and criteria by which an option should be selected. The discussion can be structured by graphical presentations showing the relationships between the questions, options and criteria. This type of argumentation support system can potentially be integrated into computer-aided software engineering tools to provide a record of design rationale - the reasons why design decisions were taken.
It is possible to conduct basic research into CSCW using only networked workstations, but there are many more sophisticated alternatives. A great deal of research has been conducted into uses of video conference technology and networked shared whiteboards, which provide a common workspace for physically separated groups. This research analyses the interaction between groups of people working together in order to determine which attributes need to be preserved in physically distributed collaboration.
An alternative approach to CSCW research analyses the interaction in successful online communities. Examples include Usenet newsgroups (ucam.cl.students appears to be an effective networked community), and collaborative role-playing environments such as multi-user dungeons (MUDs). Graphical avatars and shared virtual reality promise to provide interesting developments in this area.
4.4.2. Information appliances / Ubiquitous computing
As microprocessors are incorporated into a greater range of devices, it is reasonable to ask what potential this offers for new modes of interaction with both new gadgets and traditional appliances. Research groups working in this field (including several in Cambridge) investigate what you can do by incorporating computing and communication functions into ordinary appliances such as toasters, kettles, refrigerators, desks, televisions or radios.
Large commercial laboratories also investigate the potential of expanding the range of computing devices, and integrating a wider range of information devices into our environment. There are many opportunities to expand the capabilities of existing devices such as PDAs, cell-phones or smart cards, as well as introducing new categories of device - intelligent walls and paper, smart badges, keyrings or jewellery. Much of this research currently concentrates on providing different styles of network interaction using a variety of devices that establish the user's location and identity, but have only minimal user interfaces.
4.4.3. New interaction devices
Hardware devices such as the mouse and the bit-mapped display have been extremely influential on the current generation of user interface, as was described in the first theme. There are continual attempts to define and characterise the next generation of interaction devices. Examples include extended capabilities of current hardware - new techniques for pen input (e.g. text entry techniques, gesture languages) or extended physical interaction (two-handed interaction techniques such as information lenses, foot-operated devices or gaze tracking).
Interaction in 3D spaces is still a very difficult problem. Standard hardware includes 3D position sensors such as head trackers, data gloves, and 3D mice or wands. The effectiveness of these devices differs depending on the context, the task, and the type of display - 3D display on a screen offers different opportunities from immersive virtual reality, or augmented reality in which data displays are superimposed on the user's view of the real world.
It is unclear how sound should be exploited in a user interface. As speech recognition technology improves, it is likely to require a completely new interaction paradigm - perhaps abandoning direct manipulation and returning to the command dialogue models of teletype-based interaction. There have also been occasional attempts to provide status information and feedback to system users by generating non-speech audio in response to user actions or system events.
4.4.4. End user programming
The study of programmers has always been an important sub-field of HCI, usually described as the psychology of programming. It was once the case that most computer users were likely to write at least small programs. The majority of computer users now do little programming, and this area of HCI has become less widespread, with specialist groups such as the Psychology of Programming Interest Group (PPIG) providing research reports. This topic is now gaining importance for user interfaces which include tasks that resemble programming: defining the behaviour of agents and scripting languages. This is often described as end-user programming, and there are many examples of commercial products providing programming capabilities for specialist groups of users - the laboratory automation language LabView is one example. Macro languages in common desktop applications have clearly failed to provide benefits to most users. An alternative approach is programming by demonstration, in which the system watches the user's actions, and infers a program which will automate the operations it observed.
There has also been a great deal of research into special languages for teaching programming principles or general reasoning abilities. This is relevant to computer science students, but also to younger students including school-children and preschoolers. Psychologists and educationalists consider this type of research to be a high priority, and it is generally based on studies of actual students using existing and experimental programming languages in the classroom. Some of this research has resulted in commercial educational products such as Logo, ToonTalk, AgentSheets and StageCast Creator (details of all of these are available online).
4.4.5. Summary of Research Trends
Much HCI research is either developing or responding to new technologies, as has always been the case. Despite the fact that HCI research is often led by technology, the case made in my first theme is still relevant. In research, as in commercial system development, usability can only be improved by the application of psychological and engineering principles. The techniques for usability analysis that have been described in these themes provide a basis for anticipating the usability implications of new technology, rather than simply implementing "neat" ideas with little knowledge about the effects they will have.
Analysis Technique 1: Heuristic Evaluation
Nielsen suggested that the usability of a system should be evaluated by a panel of experts, each working from a list of usability heuristics. These are similar to Shneiderman's abstraction of the important principles of direct manipulation interfaces, including: Objects of interest should be continuously visible, operations should involve physical actions, effects should be rapid, visible, and reversible etc. Nielsen extended the list to other aspects of direct manipulation, and also to other features of the user interface besides direct manipulation.
However the heuristics themselves are not the most important feature of heuristic evaluation; they can be changed at any time. The essence of the technique is that once we have a set of such heuristics, it can be applied to make a systematic evaluation of a software system. The interpretation of the heuristics and the resulting evaluation are subjective, but the use of a panel of experts is intended to provide a degree of objectivity.
Procedure
It is therefore essential that heuristic evaluation involve multiple evaluators (preferably with differing backgrounds, in order to consider the system from different perspectives). Each evaluator inspects the interface alone, perhaps using a scenario describing the things that a typical user of the system would want to do with it. At each step of the inspection the evaluator compares its compliance to each of the heuristics - all evaluators use the same set of heuristics. The evaluators go through the interface at least twice, listing all the usability problems that they find. The results from all the evaluators are then compiled into a list documenting the usability problems of the system.
Sample heuristics
Nielsen provides a sample list of heuristics that might be used in an heuristic evaluation. A number of these are recognisably derived from principles of direct manipulation, although they apply to a wide range of different interaction styles.
Visibility of system status
The system should always keep users informed about what is going on, through appropriate feedback within reasonable time.
Match between system and the real world
The system should speak the users' language, with words, phrases and concepts familiar to the user, rather than system-oriented terms. Follow real-world conventions, making information appear in a natural and logical order.
User control and freedom
Users often choose system functions by mistake and will need a clearly marked "emergency exit" to leave the unwanted state without having to go through an extended dialogue. Support undo and redo.
Consistency and standards
Users should not have to wonder whether different words, situations, or actions mean the same thing. Follow platform conventions.
Error prevention
Even better than good error messages is a careful design which prevents a problem from occurring in the first place.
Recognition rather than recall
Make objects, actions, and options visible. The user should not have to remember information from one part of the dialogue to another. Instructions for use of the system should be visible or easily retrievable whenever appropriate.
Flexibility and efficiency of use
Accelerators -- unseen by the novice user -- may often speed up the interaction for the expert user such that the system can cater to both inexperienced and experienced users. Allow users to tailor frequent actions.
Aesthetic and minimalist design
Dialogues should not contain information which is irrelevant or rarely needed. Every extra unit of information in a dialogue competes with the relevant units of information and diminishes their relative visibility.
Help users recognize, diagnose, and recover from errors
Error messages should be expressed in plain language (no codes), precisely indicate the problem, and constructively suggest a solution.
Help and documentation
Even though it is better if the system can be used without documentation, it may be necessary to provide help and documentation. Any such information should be easy to search, focused on the user's task, list concrete steps to be carried out, and not be too large.
Applicability
At the time of writing, heuristic evaluation is the most popular technique for assessing usability of software designs. It is simple and cheap to conduct, and appears easily justifiable on commonsense grounds. The disadvantages are that it provides little opportunity to address deeper system design problems, and that it does not provide any systematic way to generate solutions to the problems that are discovered.
More information on heuristic evaluation is available from Nielsen's web site:
Analysis Technique 2: Keystroke Level Models
The keystroke level model (KLM) is a technique that is superior to heuristic evaluation in one very specific respect - it provides detailed quantitative information about usability. KLM is developed from Card, Moran & Newell's Model Human Processor. It aims to provide a simplified model of human performance that is sufficient for predicting speed of interaction with a user interface. KLM assumes that the user already knows the sequence of operations that he or she is going to perform - that is, he or she is an expert user performing a routine task. Card, Moran & Newell's GOMS model additionally takes into account the time required to plan more complex operations, but the use of GOMS for performance prediction is too complex to be presented here. The complexity of GOMS also means that it is of questionable utility compared to the relatively simple KLM (some well-known HCI researchers created a spoof satirising GOMS - you can see the GOMSerciser at: http://www.parc.xerox.com/csl/members/dourish/goms.html).
The basic approach of KLM is to decompose the total task into unit operations, using an established set of prediction components to estimate the time required to perform each operation, and add these estimated times in order to predict the overall task completion time.
Basic components
KLM has four basic time prediction components based on human performance:
K: The time that it takes to press a key. This is assumed to be constant, but depends on both the task and the typing skill of the user. A good typist takes 0.12 seconds on average to press keys, while an average typist takes 0.28 seconds. For difficult tasks, such as typing complex codes, 0.75 seconds is more typical, while a very inexperienced typist might take 1.2 seconds.
H: The time that it takes to move your hands to the home position on a device (mouse or keyboard) = 0.40 seconds.
P: The time that it takes to point with a mouse. This is predicted by Fitts' law, based on the size of the target and how far away it is. The result typically varies between 0.8 to 1.5 seconds, with an average of 1.1 seconds.
D: The time that it takes to draw using a mouse. Card et. al. give a value based on a very primitive drawing algorithm that is probably not relevant to modern devices.
A further component describes the additional time taken while the user waits for the system to do something:
R: The time that the system takes to respond to an action.
Finally, there is a component that estimates the time the user spends thinking before carrying out a unit operation:
M: The time that it takes to mentally prepare for an action. This is estimated as a constant of 1.35 seconds.
Mental preparation
The main psychological subtlety in KLM is the question of when the user is expected to need mental preparation time. A set of rules define these circumstances for the purposes of estimation. The rules basically state that every operation must be preceded by mental preparation, but that no mental preparation is needed between two unit operations that form a chunk. The definition of a chunk, however, is slightly ambiguous, as can be seen from the following rules.
Start by listing all of the operations that are required to complete the task, including points at which the system must respond before the user continues. Then apply the following rules:
Rule 0: Insert Ms in front of all Ks that are not part of a string (either text string or number string). Insert Ms in front of all Ps that select commands.
Rule 1: If the operator after an M is fully anticipated by the operator before it, the M can be deleted.
Rule 2: If a string of Ks belong to a cognitive unit, such as a command name, the Ms between them can be deleted.
Rule 3: Two Ks that are both terminators (e.g. Return keys) do not need to be separated by an M.
Rule 4: Where a particular command string is always followed by a terminator, the terminator can be regarded as part of the command string, so no M is needed between them.
Applicability
The keystroke level model is a useful approach to analysing situations in which a user interface has a limited number of features, and these are used in a repetitive way. It provides detailed time and motion estimates that can be used to predict the improvements that would result from relatively minor changes to a user interface (or possibly to compare constrained and equivalent parts of alternative interfaces for a particular task). It is only really useful as a means for making comparative estimates - the absolute accuracy of the time estimates can vary quite widely according to user and task, and should probably be confirmed in practice by empirical measurements. Furthermore the chunking rules are rather ambiguous (e.g. the meaning of fully anticipated), and only apply to command-based systems. Equivalent chunking rules for phenomena such as dismissal of Windows dialogues would have to be established by further investigation.
A more complete discussion of KLM is provided in section
8.4.2. of Newman and Lamming. The above description is
paraphrased (with additional critical comments) from the
original paper describing the Keystroke Level Model:
S.K. Card, T.P. Moran and A. Newell, (1980). The
keystroke-level model for user performance time with
interactive systems. Communications of the ACM 23(7),
396-410. That paper is reprinted in Buxton & Baecker
Readings in Human Computer Interaction: see the further
reading list.
Analysis Technique 3: Cognitive Walkthrough
The Cognitive Walkthrough (CW) method is very different to Keystroke Level Models. Where KLM can only analyse the performance of an expert user carrying out routine operations, CW assesses the usability of a system in situations where the user is not an expert, and may be attempting a task that he or she has never done before. The authors, Lewis and Polson, achieve this by applying their own theory of exploratory learning, called "CE+". Further details of the CE+ theory are not important - the CW method itself expresses quite clearly what are the assumptions and applicability of the theory.
Behaviour model
The model of a user carrying out a task through exploratory learning involves four basic phases:
1) The user sets a goal to be accomplished with the system. A typical goal will be expressed in terms of the expected capabilities of the system, such as "check spelling of this document".
2) The user searches the interface for currently available actions. The availability of actions may be observable as the presence of menu items, of buttons, of available command-line inputs, etc.
3) The user selects the action that seems likely to make progress toward the goal.
4) The user performs the selected action and evaluates the system's feedback for evidence that progress is being made toward the current goal.
Evaluation procedure
The evaluation procedure is based on a manual simulation of a user iteratively carrying out the stages of the behavioural model. Before evaluation can start, the evaluators need to have access to the following information:
1) A general description of the type of users who are expected to use the system, and the relevant knowledge that these users would be expected to have.
2) A description of one or more representative tasks to be used in the evaluation.
3) For each of the tasks, a list of the correct actions that should be performed in order to complete the task.
The evaluation is conducted by the interface designer, and by a group of peers. This group includes a nominated scribe who records the results of the evaluation and a facilitator who is responsible for the smooth running of the evaluation process. The scribe and the facilitator are also active members of the evaluation group.
The group of evaluators move through each of the tasks, considering the user interface at each step. At each step, they examine the interface and tell a story about why the user would choose that action. These stories are then evaluated according to an information-processing model derived from the exploratory learning behavioural model:
1) consider what the user's current goal is;
2) evaluate the accessibility of the correct control;
3) evaluate the quality of the match between the control's label and the goal; and
4) evaluate the feedback provided after action.
Applicability
Cognitive walkthrough is widely considered to be based on a realistic model of system use, and one that is applicable to the current generation of WIMP / direct manipulation interfaces. It does assume that the evaluators are knowledgeable designers who are able to assess visibility, feedback and goal structures using relevant theories from cognitive psychology. It is more structured than heuristic evaluation, and is probably less likely to suffer from subjectivity as a result of its emphasis on the user (imagine a group of designer/evaluators arguing about the aesthetic quality of an interface that one of them has designed).
More information on cognitive walkthrough, from the original authors, is available in a brief description presented recently at the ACM conference on Human Factors in Computing Systems:
The authors have also produced a "shareware" book describing cognitive walkthrough in a form suitable for use by non-psychologists. It is intended for use by professional programmers in commercial situations, and the authors therefore request a payment of $5 (or equivalent) when people download it. The shareware book is available at:
Analysis Technique 4: Cognitive dimensions of notations
The cognitive dimensions of notations framework (CDs) is intended to provide a broad-brush approach to usability analysis. The author, Thomas Green, considered that earlier usability methods such as KLM and GOMS suffered a "death by detail" - the analysis results were at such a low level that designers could lose track of the best way to improve the interface. Green therefore set out to provide a tool that was directly usable by engineers, although reflecting his own psychological expertise.
The CDs are presented as a vocabulary for design discussion. Many of the dimensions reflect common usability factors that experienced designers might have noticed, but did not have a name for. Giving them a name allows designers to discuss these factors easily. Furthermore, CDs are based on the observation that there is no perfect user interface. Any user interface design reflects a set of design trade-offs that the designers have had to make. Giving designers a discussion vocabulary means that they can discuss the trade-offs that result from their design decisions. The nature of the trade-offs is reflected in the structure of the dimensions. It is not possible to create a design that has perfect characteristics in every dimensions - making improvements along one dimension often results in degradation along another.
Information artefacts
CDs are relevant to a wide range of situations including household appliances, telephones, and novel interaction devices as well as conventional computer systems. These devices are regarded as information artefacts which provide a notation of some kind, and an environment for viewing and manipulating the notation. Usability is a function of both the notation and the environment. Complex systems can include several specialised notations to help with a specific part of the job. Some of these might even seem to be separate from the rest of the system, for example when a user sticks a Post-It note on the computer screen, as a reminder of what to write in a word processor document. There are two kinds of these sub-devices.
Sub devices such as helper devices and redefinition devices often have their own notations that are separate from the main notation of the system, and an independent set of cognitive dimensions. The dimensions of these devices must be analysed independently.
Notational activities
When users interact with notations, there are a limited number of activities that they can engage in, described with respect to the structure of the notation. A CDs evaluation must consider which classes of activity will be the primary type of interaction for all representative system users. If the needs of different users have different relative priorities, those activities can be emphasised when design trade-offs are selected. The basic list of activities includes:
Search
Finding information by navigating through the notational structure, using the facilities provided by the environment (e.g. finding a specific value in a spreadsheet);
Incrementation
Adding further information to a notation without altering the structure in any way (e.g. adding a new formula to a spreadsheet);
Modification
Changing an existing notational structure, possibly without adding new content (e.g. changing a spreadsheet for use with a different problem);
Transcription
Copying content from one structure or notation to another notation (e.g. reading an equation out of a textbook, and converting it into a spreadsheet formula);
Exploratory design
Combining incrementation and modification, with the further characteristic that the desired end state is not known in advance (e.g. programming a spreadsheet on the fly or "hacking").
Representative cognitive dimensions
The following list gives brief definitions of the main dimensions, and examples of the questions that can be considered in order to determine the effects that these dimensions will have on different user activities.
Premature commitment: constraints on the order of doing things.
When you are working with the notation, can you go about the job in any order you like, or does the system force you to think ahead and make certain decisions first? If so, what decisions do you need to make in advance? What sort of problems can this cause in your work?
Hidden dependencies: important links between entities are not visible.
If the structure of the product means some parts are closely related to other parts, and changes to one may affect the other, are those dependencies visible? What kind of dependencies are hidden? In what ways can it get worse when you are creating a particularly large description? Do these dependencies stay the same, or are there some actions that cause them to get frozen? If so, what are they?
Secondary notation: extra information in means other than formal syntax.
Is it possible to make notes to yourself, or express information that is not really recognised as part of the notation? If it was printed on a piece of paper that you could annotate or scribble on, what would you write or draw? Do you ever add extra marks (or colours or format choices) to clarify, emphasise or repeat what is there already? If so, this may constitute a helper device with its own notation.
Viscosity: resistance to change.
When you need to make changes to previous work, how easy is it to make the change? Why? Are there particular changes that are especially difficult to make? Which ones?
Visibility: ability to view components easily.
How easy is it to see or find the various parts of the notation while it is being created or changed? Why? What kind of things are difficult to see or find? If you need to compare or combine different parts, can you see them at the same time? If not, why not?
Closeness of mapping: closeness of representation to domain.
How closely related is the notation to the result that you are describing? Why? (Note that if this is a sub-device, the result may be part of another notation, not the end product). Which parts seem to be a particularly strange way of doing or describing something?
Consistency: similar semantics are expressed in similar syntactic forms.
Where there are different parts of the notation that mean similar things, is the similarity clear from the way they appear? Are there places where some things ought to be similar, but the notation makes them different? What are they?
Diffuseness: verbosity of language.
Does the notation a) let you say what you want reasonably briefly, or b) is it long-winded? Why? What sorts of things take more space to describe?
Error-proneness: the notation invites mistakes.
Do some kinds of mistake seem particularly common or easy to make? Which ones? Do you often find yourself making small slips that irritate you or make you feel stupid? What are some examples?
Hard mental operations: high demand on cognitive resources.
What kind of things require the most mental effort with this notation? Do some things seem especially complex or difficult to work out in your head (e.g. when combining several things)? What are they?
Progressive evaluation: work-to-date can be checked at any time.
How easy is it to stop in the middle of creating some notation, and check your work so far? Can you do this any time you like? If not, why not? Can you find out how much progress you have made, or check what stage in your work you are up to? If not, why not? Can you try out partially-completed versions of the product? If not, why not?
Provisionality: degree of commitment to actions or marks.
Is it possible to sketch things out when you are playing around with ideas, or when you aren't sure which way to proceed? What features of the notation help you to do this? What sort of things can you do when you don't want to be too precise about the exact result you are trying to get?
Role-expressiveness: the purpose of a component is readily inferred.
When reading the notation, is it easy to tell what each part is for? Why? Are there some parts that are particularly difficult to interpret? Which ones? Are there parts that you really don't know what they mean, but you put them in just because it's always been that way? What are they?
Abstraction: types and availability of abstraction mechanisms.
Does the system give you any way of defining new facilities or terms within the notation, so that you can extend it to describe new things or to express your ideas more clearly or succinctly? What are they? Does the system insist that you start by defining new terms before you can do anything else? What sort of things? These facilities are provided by an abstraction manager - a redefinition device. It will have its own notation and set of dimensions.
Evaluation procedure
Cognitive dimensions are intended to be useful in a range of research and design contexts, and it is possible to apply them without a strict evaluation procedure. In a tutorial presented in 1998, Green and Blackwell suggested the following approach to system evaluation using CDs:
1) Identify the main notation of the system, describing the medium in which the marks of the notation are expressed, and the environment in which it is manipulated.
2) Identify sub-devices: helper devices and redefinition devices (some sub-devices may only become apparent once the analysis of the main notation is under way). Describe the notation used by each sub-device. Some systems also include other layers of notation where the system regenerates the same information in different notational forms. These must also be analysed separately, if the user ever interacts with them.
3) Consider each notation in terms of the list of dimensions, identifying any usability problems where the system characteristics on that dimension are inappropriate to the user activity (for example, high viscosity is inappropriate to exploratory design).
4) Where problems have been identified, consider design manoeuvers to adjust that dimension (design manoeuvres are described in more detail in other publications on cognitive dimensions). Many design manoeuvres introduce trade-offs that must be considered before finalising the change.
Applicability
Cognitive dimensions are far more appropriate as a design tool than are other evaluation techniques. They provide quite specific guidance regarding potential changes that can be made to the interface, as well as the likely consequences of those changes. They can also be used to analyse complex types of software, such as spreadsheets or programming languages, that cannot be analysed meaningfully using other evaluation techniques. At present there is no detailed evaluation procedure defined for use with CDs, but it is clear that they offer the potential to provide more information than other evaluation methods regarding the relative needs of different classes of user. They were originally developed in order to overcome sterile debates about the relative advantages of different programming languages, and this pragmatic orientation is highly valuable within a design team that must find alternatives to the search for an idealised solution to interface problems.
More information on Cognitive dimensions, including detailed descriptions of the dimensions with their respective implications and trade-offs, can be found on-line at:
These exercises are intended as a basis for discussion during supervisions. Each of them requires several hours work, when done properly.
Interface Evaluation
Interface Design
Sketch a basic user interface for an online application that will match students up with potential supervisors in the Computer Lab. The application should allow students to choose who will be in their tutorial groups, and it should allow changes to be made. See if you can anticipate problems with the interface, using either heuristic evaluation or cognitive dimensions of notations. Create a low-fidelity prototype of your interface using paper and pencil. Ask a friend to operate the prototype (while you provide system responses), and write a brief report describing the usability problems you discovered - compare these to the predictions you made.
Task Observation
Choose a situation in which you can watch people carrying out routine paper-based tasks, such as the queue at a building society, travel agent or post office, or an unobtrusive corner of a university department or college office. Spend five to ten minutes observing their activities and taking notes. Try not to get arrested. Describe the task that this person carries out, and identify a user profile suitable for use in a cognitive walkthrough evaluation of a new computer system (characteristics of the user, relevant knowledge etc.). Consider software packages that you are familiar with, and see if you can identify one that might be useful in this situation. What adaptation would be required?
Recommended Text: Newman & Lamming
Newman, William M. & Lamming, Michael G., Interactive System Design. Addison-Wesley 1995.
William Newman and Mik Lamming are both very respected researchers in HCI, and have been instrumental in the development of some of the core technologies of personal computing, including Postscript and Photoshop. They currently work in Cambridge at the Rank Xerox Research Centre, a European outpost of the famous Xerox Palo Alto Research Centre (which was a commercial pioneer of almost all the elements of the modern computing environment: Ethernet, laser printers, and windowing user interfaces).
This book has been written as a practical resource for software engineers, and emphasises the aspects of HCI that are relevant to system design. It provides a useful summary of psychological theories, and guidelines for taking these into account when designing interfaces. It reviews the leading analysis methods that are currently used for usability evaluation, including most of those that have been covered in these lectures. It does not present them in great detail, however: it provides information that should be sufficient for choosing an evaluation technique, but an actual evaluation project would require further reading.
It also provides ample practical advice about design procedures, including how to collect and analyse system requirements for development into the specification of an interactive system. This is practically oriented, with sensible advice about integrating interface design and evaluation procedures into a software project. At the time of writing these lecture notes, this advice is up-to-date, and accurately reflects good commercial practice (that is, it is far superior to general commercial practice).
The following table of contents gives an idea of the organisation and coverage of the book.
Part 1: Basic Framework:
Defining the problem, The Human Virtual Machine, Design processes and representations
Part 2: System design:
User study methods, Systems analysis and design, Requirements definition
Part 3: System evaluation:
Usability analysis and inspection, Prototyping and evaluation, Experiments in support of design, Case Study: Evaluation and analysis of a telephone operator's workstation
Part 4: User interface design:
User interface notations, Interaction styles, Conceptual design: The user's mental model, Conceptual design: Methods, Designing to guidelines, Case Study: Designing a human memory aid
Recommended Text: Borenstein
Nathaniel S. Borenstein. Programming as if People Mattered: Friendly programs, software engineering and other noble delusions. Princeton University Press, 1991.
This book is complementary to, and very different from, Newman and Lamming. It is not a conventional textbook, but gives a far clearer idea of the actual process of user interface development. It is recommended for this course because it includes the kind of case studies and experience of actual product development that we do not have time to cover.
Borenstein bases many of his observations on his personal experience of working on a large project: the Andrew Project developed by IBM and Carnegie Mellon University. The Andrew project pioneered many of the user interface facilities that are now central to the Internet, so he is able to discuss them from the perspective of a user interface designer who has seen the results of his work widely distributed and modified. Moreover his role as a manager gives him a similar perspective to that of Fred Brooks, author of the classic software engineering text The Mythical Man-Month. This book can be regarded as a user interface developer's version of The Mythical Man-Month.
Although it is a valuable source of practical advice for software engineers doing user interface development, the general tone is quite light-hearted. It can be very amusing for readers who have experienced the problems of software development in the corporate world. Chapter titles include the ten commandments of user interface design, such as: "Lie to your managers", "Cut corners proudly" and "Your program stinks and so do you!"
Martin Helander (Ed.) (1990). Handbook of Human-Computer Interaction. North-Holland.
This is a large collection of short articles, organised to cover most of the research topics in HCI. It is a valuable research resource for further work in HCI, and gives a good introductory discussion for most topics. It has detailed descriptions of some analysis techniques, including GOMS. A number of the topics appear rather dated, however.
William S. Buxton & Ronald M. Baecker (Eds.) (1987). Readings in Human Computer Interaction: A multidisciplinary approach. Morgan Kaufmann.
Another large book, this time reprinting classic research papers in HCI. Many of the topics covered in the current course were first described in papers that can be found here. Examples include the Keystroke-Level Model, Mental Models, Direct Manipulation, and the history of the Xerox Star project.
Alan Cooper (1995). About Face: The Essentials of User Interface Design. IDG Books.
This book is less research-oriented, but is based on very sound opinions and experience. The main advantage of this book is that it is more up to date, and gives much practical advice of direct relevance to the current generation of Windows software development, with examples and case studies.
Colin Robson (1994). Experiment, Design and Statistics in Psychology (3rd edition). Penguin.
A basic text on experiment design and simple statistical analysis techniques that are suitable for use in HCI experiments. Many more sophisticated texts are available! Newman and Lamming also give a brief introduction to this topic that may be sufficient.
Ericsson, K.A. & Simon, H.A. (1985). Protocol Analysis: verbal reports as data. MIT Press.
A detailed text giving advice on the collection of verbal protocols, as well as a defense of the verbal protocol technique against criticisms of subjectivity or invalidity.
Interface Hall of Shame
http://www.iarchitect.com/shame.htm
An entertaining collection of bad examples (as well as good examples) of interface design. The site also has many useful links to other HCI resources.
Jakob Nielsen's website
A respected HCI researcher who gained a high public profile while promoting Web usability for Sun. His advice on making usable web sites is particularly valuable and popular (the design of the site itself follows his advice, of course).
HCI Bibliography
A searchable bibliography of the HCI research literature.
Cognitive Dimensions Tutorial
http://www.cl.cam.ac.uk/~afb21/publications/CDtutSep98.pdf
A beginner's guide, including detailed explanations, of the Cognitive Dimensions of Notations framework. This material was presented as a half-day tutorial at the British Computer Society HCI conference in 1998.
Cognitive Walkthrough
http://www.acm.org/sigchi/chi95/Electronic/documnts/tutors/jr_bdy.htm
Basic instructions on how to conduct a Cognitive Walkthrough. More detail is provided in the shareware book at: http://www.cis.ohio-state.edu/~perlman/CIS516/uidesign.html.
Heuristic Evaluation
http://www.useit.com/papers/heuristic/heuristic_evaluation.html
Basic instructions on how to conduct an Heuristic Evaluation (a set of heuristics is also available).
Tutorial on Interacting Cognitive Subsystems
Sun's guide to Web style
Sun's Java look and feel guidelines
Apple's interface guidelines:
Microsoft's new opinion on guidelines:
A discussion of questionnaires as a research tool: