We want to pull out a particular element from the document, namely the table with boat race results, so we need to work out how to refer to it in XPath. The Chrome webbrowser has a handy tool to help with this. Go to the page you're interested in, and click on … | More tools | Developer Tools. Click on the element-selector button at the top left:
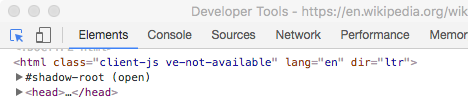 Go back to the web page, and click on a piece close to what you want to select. I clicked on the top left cell of the table:
Go back to the web page, and click on a piece close to what you want to select. I clicked on the top left cell of the table:
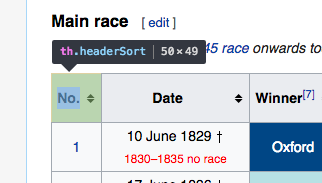 Go back to the developer tools window, and navigate to the exact element you want. Here, we want the table. Right-click and choose Copy | Copy XPath.
Go back to the developer tools window, and navigate to the exact element you want. Here, we want the table. Right-click and choose Copy | Copy XPath.
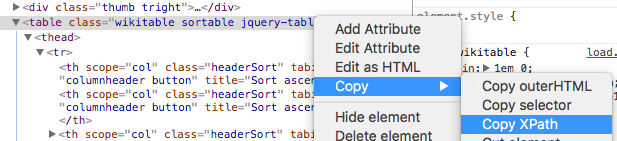 It gave me the XPath location `"//*[@id="mw-content-text"]/div[1]/table[2]"`. Now we can extract the data.
It gave me the XPath location `"//*[@id="mw-content-text"]/div[1]/table[2]"`. Now we can extract the data.