Parallel Computing Notes
Flynn s Classification (1966)
Broad classification of parallel computing systems based on number of instruction and data streams
Source MIT CSAIL.
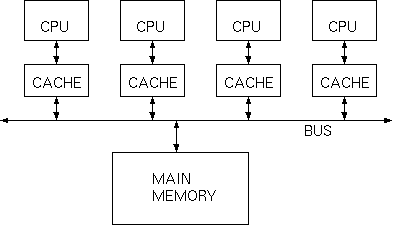
Cache Consistency
MSI CC Protocol
M - Modified: The cache line is present only in the current cache, and is dirty; it has been modified from the value in main memory. The cache is required to write the data back to main memory at some time in the future, before permitting any other read of the (not longer valid) main memory state.
S - Shared: Indicates that this cache line may be stored in other caches of the machine.
I - Invalid: Indicates that this cache line is invalid.
MESI CC Protocol
MESI protocol (known also as Illinois protocol) is a widely used cache coherency and memory coherence protocol, which was later introduced by Intel in the Pentium processor to "support the more efficient write-back cache in addition to the write-through cache previously used by the Intel 486 processor".
Every cache line is marked with one of the four following states (coded in two additional bits):
M - Modified.
E - Exclusive: The cache line is present only in the current cache, but is clean; it matches main memory.
S - Shared.
I - Invalid:
A cache may satisfy a read from any state except Invalid. An Invalid line must be fetched (to the Shared or Exclusive states) to satisfy a read.
A write may only be performed if the cache line is in the Modified or Exclusive state. If it is in the Shared state, all other cached copies must be invalidated first. This is typically done by a broadcast operation.
A cache may discard a non-Modified line at any time, changing to the Invalid state. A Modified line must be written back first.
A cache that holds a line in the Modified state must snoop (intercept) all attempted reads (from all of the other CPUs in the system) of the corresponding main memory location and insert the data that it holds. This is typically done by forcing the read to back off (i.e. to abort the memory bus transaction), then writing the data to main memory and changing the cache line to the Shared state.
A cache that holds a line in the Shared state must also snoop all invalidate broadcasts from other CPUs, and discard the line (by moving it into Invalid state) on a match.
A cache that holds a line in the Exclusive state must also snoop all read transactions from all other CPUs, and move the line to Shared state on a match.
The Modified and Exclusive states are always precise: i.e. they match the true cacheline ownership situation in the system. The Shared state may be imprecise: if another CPU discards a Shared line, and this CPU becomes the sole owner of that cacheline, the line will not be promoted to Exclusive state. (because broadcasting all cacheline replacements from all CPUs is not practical over a broadcast snoop bus)
In that sense the Exclusive state is an opportunistic optimization: if the CPU happens to have it right, moving into the Modified state needs no memory bus transactions - if the CPU has it wrong, there's an extra bus transaction, but cache coherency is still preserved.
MOESI Protocol
MOESI is a full cache coherency protocol that encompasses all of the possible states commonly used in other protocols. Each cache line is in one of five states:This is a more elaborate version of the simpler MESI protocol, which avoids the need to write modifications back to main memory when another processor tries to read it. Instead, the Owned state allows a processor to retain the right to modify a shared cache line by promising to share any writes it performs with the other caches.
MOESI is beneficial when the communication latency and bandwidth between two CPUs is significantly better than to main memory. Multi-core CPUs with per-core L2 caches are an example of that.
Wikipedia
Taken from Wikipedia Feb 2006.CC Network
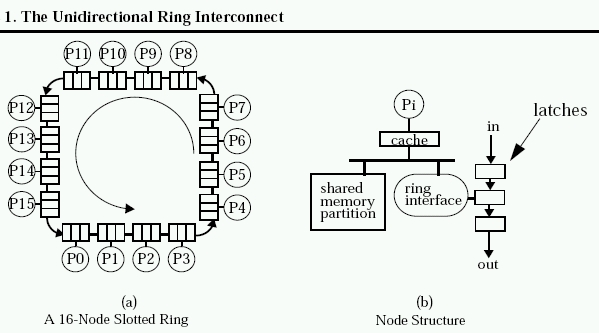

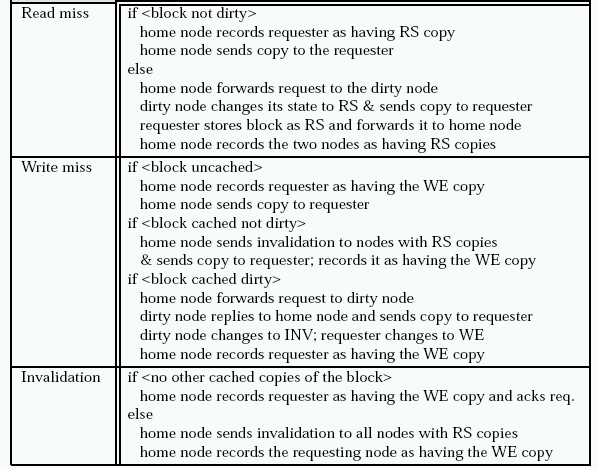
Directory Protocols
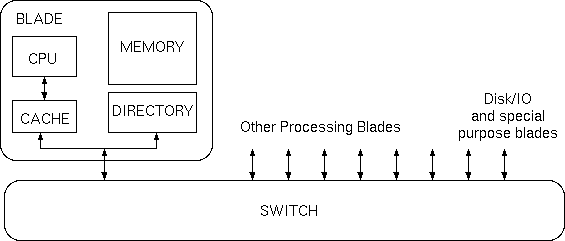
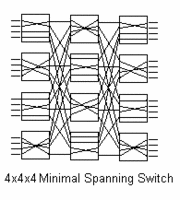
Traditional Switch Structures
![]() A Tesseract - 4D cube.
A Tesseract - 4D cube.
Supercomputer Interconnect
SGI NumalinkExample Supercomputer
SoC Bus Protocols
SAN. Storage Area Network
Cluster Computing
www.answers.com/topic/parallel-computing