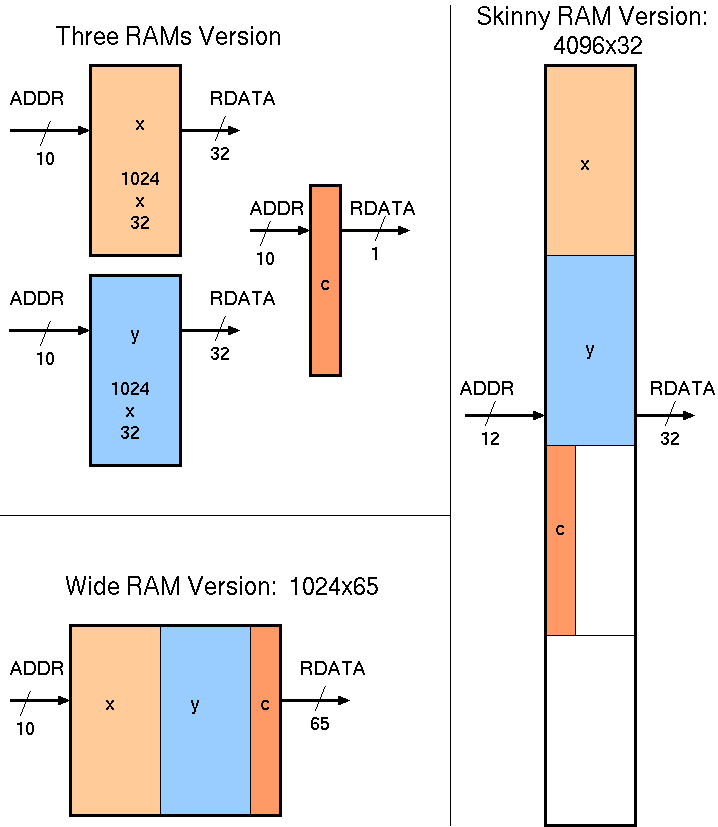
Several Possible RAM deployments for the example code fragment.
We do not want to deploy a lot of resource to support seldom-used data paths.
Profile-directed guidance or explicit datapath description hints, such as unroll pragmas, are needed to select a good RAM arrangement and datapath structure.
In the absence of profile information from actual runs, we can either assume sequencer states are equi-probable or better solve balance equations based on the flowgraph entry node being visited exactly once.
For example, the best mapping of the record fields x and y to RAMs is different in the two foreach loops:
class IntPair
{
public bool c; public int x, y;
}
IntPair [] ipairs = new IntPair [1024];
void customer(bool qcond)
{
int sum1 = 0, sum2 = 0;
if (qcond) then foreach (IntPair pp in ipairs)
{
sum1 += pp.x + pp.y;
}
else foreach (IntPair pp in ipairs)
{
sum2 += pp.c ? pp.y: pp.x;
}
...
}
The fields x and y could be kept in separate RAMs or a common one. If qcond rarely holds then a skinny RAM will serve but the lookup of c will then add a pipeline delay (assuming read latency of one clock). Whereas if qcond holds most of the time then keeping x and y in separate RAMs or a common wide RAM will boost performance and it hardly matters where c is stored. The skinny solution in the
Depending on the implementation technology, wide RAMs may or may not be better than skinny ones. Also, RAMs whose word size is not a power of 2 might be readily available in FPGAs where a RAM is aggregated from small tiles. For instance, the Virtex 7 FPGA has, at the lowest level, an 18 Kb BRAM tile that can be configured as a 16K x 1, 8K x2 , 4K x 4, 2K x 9, 1K x 18 ...
| 36: (C) 2008-18, DJ Greaves, University of Cambridge, Computer Laboratory. |