
December 1990 An experimental general topology local area network based on Asynchronous Transfer Mode (ATM) is described. This network is intended to be used to support multiservice traffic. The provision of guarantees of quality of service to various traffic types is an important feature of the network. The management algorithms which will be used to provide these guarantees are the subject of current research; the network components described here can be viewed as a platform on which these algorithms will be developed.
Fairisle is supported by the SERC under Grant GR/F 6090.8 and by HP Laboratories Bristol.
Fairisle was begun in October 1989. It arose from work in the Computer Laboratory in ATM networks, multimedia communications, protocol architectures and fast packet switching. The overall purpose of Fairisle is to investigate networks rather than switches. Such an investigation is as much concerned with how components fit together as it is with network components themselves.
In the tradition of the Computer Laboratory this investigation is based on experience of a real network moving real user data. Thus the first problem that Fairisle has faced is in designing and constructing components. These components will form the basis, or rather the experimental apparatus, on which the real experiments will take place.
A major goal of the Fairisle network is to support multiservice traffic, supplying guarantees (bandwidth, delay, loss) when required. Decisions about what sort of guarantees are made and how many types of guarantee there are have been left open for experimentation. It is the management of network resources which will be the most novel aspect of Fairisle.
In developing an network architecture which is to be used as a basis for experimentation in network resource management, one must produce an architecture that gives rise to a manageable network. By a manageable network we mean one in which both network resources and resource demands made by traffic are identifiable and quantifiable. The precision of guarantees given to different types of traffic will necessarily be related to the precision with which traffic demand is specified when communication is initiated.
As well as an architecture, we have developed an implementation of the network. This implementation will eventually include specific management algorithms, but in the first instance it must be sufficiently flexible to allow a variety of algorithms to be used and monitored.
The Fairisle Network Architecture is presented in the next section. Following this, section three describes the network implementation in terms of the network components. Finally the current status of the implementation and some concluding remarks are made in section four.
We are using ATM for a number of reasons. Briefly these are
The expectation that B-ISDN will be the ubquitous high speed long haul interconnect, leads us not only to believe that the local distribution of B-ISDN traffic is important, but also that ATM provides an opportunity to integrate not just traffic types, but local and wide area communication. This has implications for network architecture - we are interested in ATM internetworking.
Finally, whatever the problems to be solved, and the penalties to pay in running an ATM network we believe that the unpredictability of traffic demands, both in quality and quantity make ATM an attractive strategy. ATM is the most flexible network interface.
We do not consider this an open and shut case. One can imaging globally addressing each ATM cell and using fields in the cell header to indicate traffic type which could be used to facilitate the management of guarantees. However, the virtual circuit approach is more natural, particularly when it comes to measure resource usage against resource guarantee.
MSNA is designed to support multiservice communication all the way up to the multimedia application. It achieves this in two ways:
There is a cost associated with multiplexing - these are often listed as bandwidth, processing and complexity [4], but in a multiservice environment multiplexing introduces contention among traffic streams. The streamlining of multiplexing minimises these points of contention (although some may always exist) in end systems. In MSNA, the virtual circuit identifier (VCI) can be used to indentify the end application entity or indeed a single thread within the application entity. Thus it is possible to have a single contention point within the end system.
Virtual circuits are the units to which quality of service guarantees and priority are given. Thus cells do not have an explicit priority field in them. MSNA does not dictate what qualities of service should be provided.
The lower layers of MSNA are concerned with cell transfer. MSNA uses an internetworking layer (analogous to IP) to provide end to end transfer of cells. The data link layer of MSNA is concerned with cell transfer on a link (where a link includes a simple topology LAN such as an Ethernet or Cambridge Fast Ring).
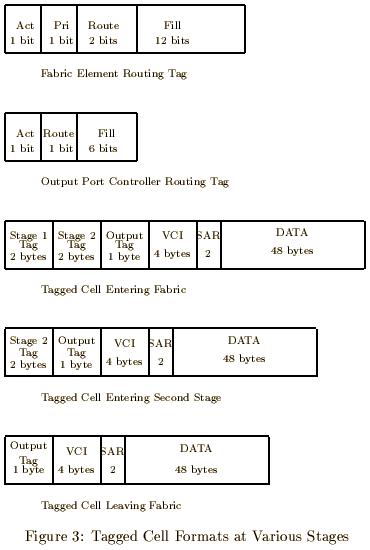
The format of a cell for the Fairisle network is shown in figure 1. As can be seen, there are four bytes of virtual circuit identifier (VCI), two bytes of segmentation and reassembly information and 48 bytes of data.
As part of association setup, an MSDL entity allocates the VCI for cells it is going to receive. The VCI has no structure visible outside the allocating entity. The allocating entity (which is the only entity which will have to process cells with that VCI) may of course place any internal structure it wishes on the VCI in order to make the processing task simpler .
A series of concatenated associations which forms an end to end channel is an MSNL liaison.
Port controllers are analogous to line cards in a telephone exchange. Their main functions in the Fairisle switch are to map VCIs, manage queues, select priority, select routing tags, and deal with blocking in the fabric. Each port controller (there are 16 in each switch) is connected to an input and output of the switch fabric.
The fabric is a very regular interconnection network. It is the place where cells contend for bandwidth. The fabric is relatively straightforward to describe; we will do this first.
It is a 16 by 16 (that is 16 inputs, 16 outputs) fabric built up from eight 4 by 4 crossbar switching elements arranged in a delta network as shown in figure 2. The delta network gives rise to the internal blocking. (Consider when port 0 and 1 both wish to send to ports 5 and 6 respectively. The cells both wish to use the internal link from element A to F; only one of them can.)
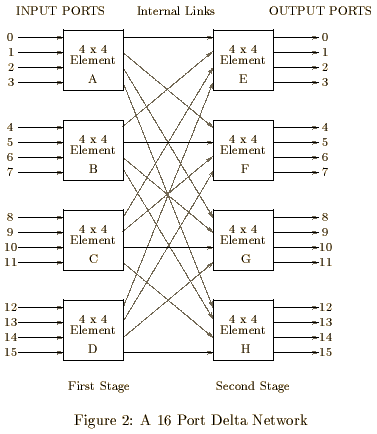
The fabric is self routing, that is, the cells have prepended to them routing tags which tell the fabric which links the cells should be sent along. The routing tags also contain priority information (in fact a single bit is used) which is examined when two cells contend for the same link. The fabric is a two stage delta so there are two routing tags. Each switching crossbar element has four outputs so two bits of routing information are required for each tag. Each stage strips off the routing (and priority) information which it uses as it processes the cell. In fact it is easier for the fabric to strip off whole bytes so routing tags are padded to a full byte. This is shown in figure 3.
Since the fabric (or indeed an output port controller) may chose not to accept a cell, an acknowledgment signal is provided. If the cell is blocked in the fabric, the input port on which the cell was injected will see a low on the acknowledgement line, otherwise it will see whatever the output port controller chooses to respond with - in fact it is a clear return data path from output to input.
Whenever two or more cells contend for the same output of a switching element, arbitration takes place. Arbitration is done for each of the four outputs of a switching element. Each output arbiter runs an independent round robin system with two levels of priority. The input links are numbered 0 to 3 and the last input to have a cell (of any priority) selected is remembered:
Each element (a 4 by 4 crossbar) is built on a Xilinx programmable gate array. (The Xilinx device is in fact a 4200 gate equivalent device with 84 pins, the XC-3042PC84-100.) A link consists of eight unidirectional data signals and an acknowledgement signal travelling in the opposite direction. There are four input links and four output links making 72 signals for data and acknowledgement.
There are two other signals of importance - the byte clock and a frame start signal. The byte clock runs at 20 MHz giving a datarate of 160 Mbps. Frame start is used to synchronise cell submission to the fabric. The port controllers also use frame start for this purpose. The frame start pulse is in fact the only indication the fabric has about cell size; it is generated by a PAL on the fabric board.
A hardware description language (or rather a pseudo hardware description language) description of the top level of an element is given below:
/*********************************************************************
Note ``0-3'' indicates an iteration, ``0..3'' means elements 0 to 3, so
X[0-3] := Y (a[0-3], b[0..3]);
is equivalent to
X[0] := Y (a[0], b[0..3]);
X[1] := Y (a[1], b[0..3]);
X[2] := Y (a[2], b[0..3]);
X[3] := Y (a[3], b[0..3]);
*********************************************************************/
MODULE SwitchingElement (Din[0..3;0..7], AckOut[0..3],
Dout[O..3;0..7], AckIn[0..3],
Clock, FrameStart);
BEGIN
/* Bit 0 in a routing tag indicates an active cell */
TimeModule := Timing (Din[0..3;0], FrameStart, RouteNow);
/* HiPri[i,j] indicates a request from input i to output j */
/* Data bits 1 and 2 are route bits, bit 3 is priority bit */
Decoder[0-3] := Decode (Din[0-3;0..2], HiPri[0-3;0..3],
LowPri[0-3;0..3]);
/* FilReq[i,j] as above but with overridden low pri requests out */
PriFilter[0-3] := PriFilt (HiPri[0..3;0-3], LowPri[0..3;0-3],
FilReq[0..3;0-3]);
/* Sel[x;0..1] are the select lines for output x */
Arbiter[0-3] := Arb (FilReq[0-3;0..3], RouteNow, Sel[0-3;0..1]);
DataMux [0-3] := Mux (Din[0..3;0..7], Sel[0-3;0..1], Dout[0-3;0..7]);
AckOut[0-3] := AckNet (Ack[0..3], Sel[0-3;0..1]);
END;
As a rough guide, the complexity of the subelements in terms of
Xilinx Configurable Logic Blocks (CLBs) are as follows:
Subelement Number per element CLBs per subelement Timing 1 3 Decode 4 4 PriFilt 4 4 Arb 4 5.5 Mux 4 12 AckNet 4 3 Total 117
Port controllers are MSNL routers. They receive cells from the transmission system and perform a lookup on cell VCIs in order to determine:
The output side is straightforward. There is a mechanism for routing cells either to the port controller itself (for management) or to the outgoing transmission system. Speed matching is provided by a simple FIFO technique, when the FIFO is logically full the output port blocks back through the fabric by keeping the acknowledgement signal unasserted.
The port controller can also gather statistics about cell flow. These can be use for policing and monitoring.
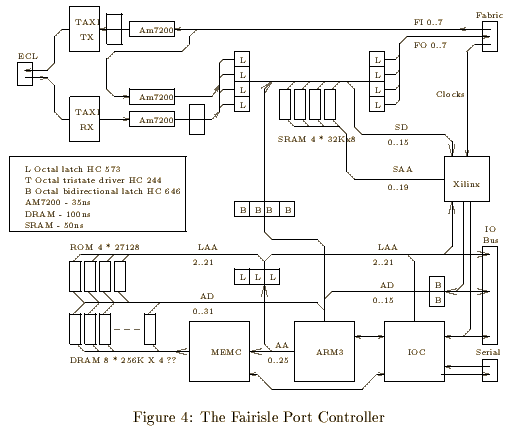
The main components are
The Xilinx device is a 4200 gate equivalent device. However a pin compatible 6400 gate equivalent device is available should we wish to put more functionality (for example all functionality) in hardware.
A version of Wanda is held in PROM, but this attempts to boot the latest system of the port controller software (including the latest Xilinx configuration).
The key feature of the network components is their flexibility. This flexibility is essential to allow as wide a range of experiments as possible. Fairisle is not so much a network design as a network simulator that happens to move user data.
PhD Dissertation, University of Cambridge Computer Laboratory, Technical Report 186. September 1989.
[2] A Fast Packet Switch for the Integrated Services Backbone Network. P Newman.
IEEE Journal on Selected Areas in Communications, Vol 6, No 9, December 1988.
[3] AutoNet: a High-speed, Self-configurating Local Area Network Using Point-to-point Links.
MD Schroeder, AD Birrel, M Burrows, H Murray, RM Needham, TL Rodeheffer, EH Satterthwaite, and CP Thacker.
Digital Equipment Corporation Systems Research Center Technical Report 59. April 1990.
[4] Layered MultiplexingConsidered Harmful. DL Tennenhouse.
IFIP Workshop on Protocols for High-Speed Networks, Zurich. May 1989.