About QJump
QJump reduces network interference in datacenters, and offers guaranteed latency messaging.

Look at the slides
To find out more, read our papers.
To learn what guaranteed latency is good for, read this blog post.
The dirty secret of datacenter networks
Today, the muscle behind the Internet is found in datacenters. Each datacenter contains tens of thousands of compute nodes networked together. Like the internet, datacenter networks use statistical multiplexing. In a statistically multiplexed network, packets share network resources in a "first come, first served" way. A packet arriving at a network switch is either forwarded immediately, or forced to wait until the link is free. This makes it hard to determine exactly how long the packet will take to cross the network. In other words, statistically multiplexed networks do not provide latency determinism.
Limit yourself and jump to get ahead!
QJump is a simple approach that improves latency determinism in datacenter networks. It works by employing two techniques:
- rate-limiting the input into the network, so that long queues cannot build up; and
- prioritizing traffic in the network, so that different applications can use rate-limits that suit them best.
When pessimism pays
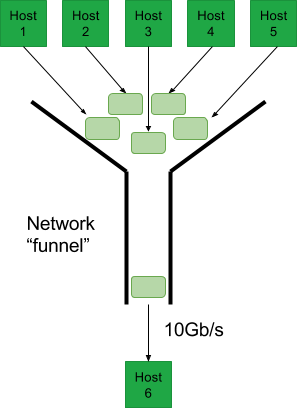
Imagine that the datacenter network is a big funnel. At the bottom of the funnel is a single host, waiting to receive traffic. At the top of the funnel is every other host in the datacenter, trying to send traffic to the host at the bottom (i.e., the worst case). If we let all of the hosts at the top send at full rate into our funnel, it fills up, overflows and drops packets. Instead, we limit the hosts at the top, so that they can fill up, but never overflow the funnel.
The rate that we can drain the funnel is limited by the connection at the bottom. For example, assume that the connection at the bottom is 10 Gb/s. If we want to make sure that the funnel never overflows, it is clear that we cannot put more than 10 Gb/s in at the top. For (e.g.) 10 hosts at the top, this is easy to do if we rate-limit all 10 hosts to 1 Gb/s. Since the funnel can never overflow, queues can never build up indefinitely, and the latency in the network can be guaranteed. This simple calculation is the basis for QJump. In practice, matters are a bit more involved, but we leave those details to the papers.
But optimism is good too
It's great to be able to guarantee latency in the network, but QJump's approach comes at the cost of throughput. If we apply the trick described above to a network with 1,000 machines, each host only gets 10 Mb/s of traffic (instead of 1Gb/s with 10 hosts). That's clearly not enough for many applications. But not every application needs guaranteed latency " in fact, many applications can get away with a statistical improvement in their latency variability (= their latency determinism). This is where QJump applies a second trick: using hardware enforced priorities to allow multiple "levels" to co-exist on the network. Each QJump level is assigned both a rate-limit and a hardware-enforced priority level. The rate-limits reduce the possibility of long queues happening in the network (in the extreme case, guaranteeing latency by bounding queue length). In other words the stricter the rate-limit, the better the latency determinism.
The QJump level with the highest priority is assigned the special rate-limit described above, granting guaranteed latency. The QJump level with the lowest priority is assigned an unlimited rate. This means that applications that need to utilize the fully available bandwidth can have it, though at the cost of still suffering from latency variations similar to a network without QJump. Between these extremes, we apply decreasingly severe rate-limits with decreasing priorities.
The reasoning behind this is simple. The guaranteed latency rate-limit described above assumes completely pessimistic conditions: it assumes that every host decides to send to the one host at the bottom of the funnel at the same time. This is pretty unrealistic, but it could happen. However, most of the time, this pessimistic condition does not happen, or at least does not get quite so bad. For example, if we assume that only half of the machines in the network send to the bottom of the funnel at a given time, then they can send at twice the rate and maintain the same latency. If this assumption breaks, they can still send at twice the rate, but the latency guarantee is violated. This is how QJump achieves a statistical improvement for applications that require more throughput.
For a more detailed and rigourous description of QJump, please see our publications page.