Four-Phase Handshake in Synchronous, Asynchronous and Behavioural Forms - Revision Notes
0. Introduction
Of the many transactional protocols widely used in electronics to asynchronously transfer data, the four-phase handshake is about the most common. The protocol provides rate adaptation, in that it has an idle state that it starts in and resets in when the sender is not ready to send, and in that it has backpressure or flow-control that prevents the sender sending further data when the receiver has no accommodation.
The familiar parallel port for printers uses an asynchronous four-phase handshake MY SHD SLIDES (PDF).
The protocol is defined at the net level using a request and an acknowledge signal and one or more data signals that carry the data: {req, ack, data[n]}. We here assume that there are sufficient data signals for all of the data to be conveyed in a single transaction to be carried in parallel over the interface.
At the net level, the system may be implemented with or without a shared clock. When there is a shared clock, each participant updates its nets only during a specified interval in each clock cycle and so knows to only sample its inputs outside that interval. (Generally, outputs are updated in a delay window after the active clock edge and sampled in a non-overlapping window starting just before and ending just after the clock edge.) Where each end system operates with a local clock, each signal must be correctly resynchronised to the local clock at the receiving end so as to avoid metastable failure.
Apart from synchronisation issues, there is an further, important, difference in the protocol that arises when a shared clock is present. Without a shared clock, exactly one transaction occurs per handshake cycle. With a shared clock, a stable setting of the handshake lines, sustained for n consecutive clock cycles can be used to indicate n back-to-back transactions.
The recent rise in interest of transactional interfaces in EDA can be considered as an exercise in interfacing between synchronous and asynchronous logic. This is because it is desired to express the transactional interfaces without reference to clock nets, whereas the underlying RTL implementations must preferably be implemented with conventional synchronous design flows.
The four-phase handshake can be used between any pair peers that wish to exchange data, but for simplicity, in this note, we concentrate on FIFO stages that are chained to form the FIFO. This immediately results in multiple instances of the handshake protocol. It should be noted that this study also applies when 4-phase is used to construct a systolic array or any other structure with processing at the nodes. Each FIFO stage receives data with from its left peer and sends it to its right peer using separate instances of the protocol.
Overview of this note
1. Behavioural Forms
By a behavioural form, we mean that the behaviour of a component is expressed using an imperative program whose statements are executed sequentially. However, many statements can be considered to execute in zero time, meaning that in a hardware implementation, all of the effects of a consecutive group become visible in one step.
Naive Behavioural Blocking Code
The nets are modelled as shared variables visible to the sender and receiver. A behavioural program to implement the interface is:
o1.send(D) o2.recv()
{ {
while (ack) wait(); while(!req) wait;
data = D; D = data;
sync(); ack = 1;
req = 1; while (req) wait();
while (!ack) wait(); ack = 0;
req = 0; return D;
} }
The call to sync is a write barrier that ensures the data is visible
on all data nets at the receiver before the req is asserted. In a software
implementation, this is a special instruction on the processor and in a
hardware implementation it is a time delay longer than the skew of the
nets that make up the interface. Most hardware or software systems do
not require an equivalent barrier in the receiver (see
http://www.cl.cam.ac.uk/users/kaf24/mem.txt for details).
It is possible to make a FIFO stage by putting a send and receive together in an infinite loop. A chain of these stages, running in parallel, form a FIFO queue.
while(1) o2.send(o1.recv()); while(1) o3.send(o2.recv()); while(1) o4.send(o3.recv()); ...
Improved Behavioural Blocking Code
We note that both client and server routines are blocking, in that they spinlock on wait. In an improved version, both threads remain blocking but the scheduler accepts a guard condition to wait on:
o1.send(D) o2.recv()
{ {
while (ack) wait(ack); while(!req) wait (!req);
data = D; D = data;
sync(); ack = 1;
req = 1; while (req) wait(req);
while (!ack) wait(!ack); ack = 0;
req = 0; return D;
} }
The while loops are still shown in the above code because the wait call is avoided if the guard already holds and because, in many systems, a wakeup may occur for a wide variety of reasons, not necessarily just the condition that was being waited on.
Event Variable Blocking Code
Many systems do not allow waiting on arbitrary conditions. All waits must be on a system event variable, and so the interface must be extended to contain such a variable. When no multiplexing is implemented, a single event variable, can be shared by both sides of the interface, but here we show a pair, R and A. As with the shared net declarations themselves, this event variable may be declared by the receiver, the transmitter or by the host that introduced the peers.
o1.send(D) o2.recv()
{ {
while (ack) wait(A); while(!req) wait (R);
data = D; D = data;
sync(); ack = 1;
req = 1; A.signal();
R.signal(); while (req) wait(R;
while (!ack) wait(A); ack = 0;
req = 0; A.signal();
R.signal(); return D;
} }
This version of the interface can be implemented with fewer tests than shown, but it then becomes unable to recover from the sender and receiver becoming desynchronised. Practical systems are implemented to recover from this error, or else two-phase handshaking is used, that intrinsically does not suffer.
Two-Phase Handshake
For reference, the two-phase handshaking implementation is:
o1.send(D) o2.recv()
{ {
data = D; r = req;
sync(); while(r==req) wait();
a = ack; D = data;
req = !req; ack = !ack;
while (a==ack) wait() return D;
} }
Multiplexing
Dynamic binding of transactional interfaces is a logical way to implement multiplexors and demultiplexors. In pure software systems, multiplexing is implemented by a number of clients being able to calling a common subroutine and demultiplexing is implemented by a number of servers being able to register an upcall (sometimes called a callback) and allowing the client to select which subroutine to call (known in software as dispatching).
To implement the multiplexing behavioural interface, separate event variables should be associated with the req and ack signals.
2. Asynchronous Forms (including Micropipelines)
In asynchronous logic, a (Sutherland) micropipeline FIFO structure is sometimes used. This is a chain of half-stages that each consist of a Muller C element, an XOR gate and a transparent latch to hold the data. A pair of half stages give the equivalent of a master-slave edge-triggered structure.Here is the standard Muller C element and four stage ripple FIFO oscillator:
// A Muller C-element module MCEL (q, a, b); input a, b; output q; wire reset; wire p1 = !(a & q); wire q1 = !(b & q); wire r1 = !(a & b); assign #13 q = !(p1 & q1 & r1); endmodule //Micropipeline stage (David Sutherland style). module MPHSL(req_l, ack_l, req_r, ack_r, din,dout); input req_l; output ack_l; output req_r; input ack_r; MCEL left(ack_l, req_l, !req_r); MCEL right(req_r, ack_l, !ack_r); // Data handling stage input [7:0] din; output [7:0] dout; reg [7:0] dout1; always @(posedge req_l) dout1 <= din; assign dout = dout1; endmodule
Here we used a master-slave, edge-triggered register for the data stages, although a pair of tandem transparent latches is often shown in the literature.
A simple testbench using four FIFO stages.
// Simulation wrapper module SIMSYS(); wire req_1, ack_1; wire req_2, ack_2; wire req_3, ack_3; wire req_4, ack_4; reg tn; initial begin tn = 0; #350 tn = 1; # 20 tn = 0; end wire [7:0] d1,d2,d3,d4; MPHSL s1(tn | req_4, ack_4, req_1, ack_1, (tn)? 8'hx5A: d4+1, d1); MPHSL s2(req_1, ack_1, req_2, ack_2, d1, d2); MPHSL s3(req_2, ack_2, req_3, ack_3, d2, d3); MPHSL s4(req_3, ack_3, req_4, ack_4, d3, d4); endmodule
Simulation waveforms from this circuit are:
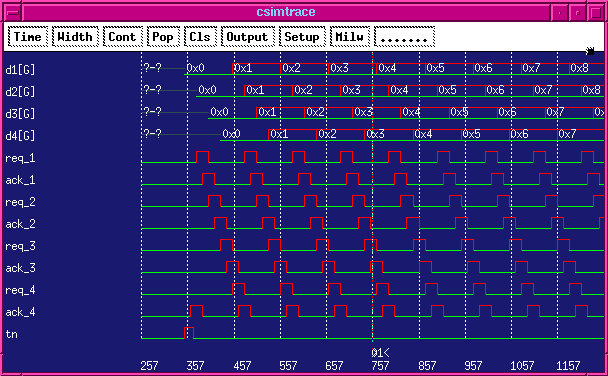
Alternate Form
We can change the form of the pipeline stage to just use an RS-latch. This results in data moving through faster.
//DJG Micropipeline stage module MPHSL(req_l, ack_l, req_r, ack_r, din, dout); input req_l; output ack_l; output req_r; input ack_r; wire s, r, q, qb; assign #13 q = !(r | qb); // RS latch made from assign #1 qb = !(s | q); // cross-coupled NORs. assign s = req_l; assign r = ack_r; assign ack_l = q; assign req_r = q; // Data handling stage input [7:0] din; output [7:0] dout; reg [7:0] dout1; always @(posedge req_l) dout1 <= din; assign dout = dout1; endmodule
Using the same testbench, simulation waveforms from this circuit are:
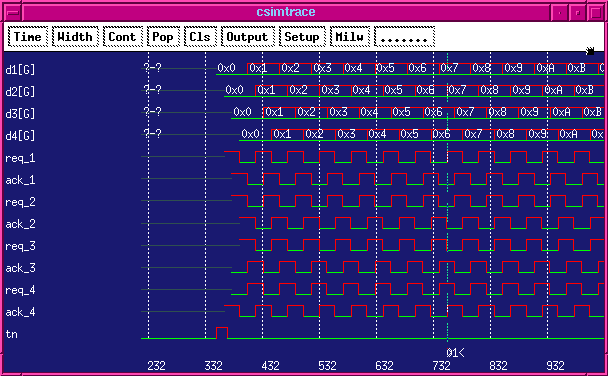
Asynchronous Compiler
For passing interest we can examine the FIFO stage generated by the Orangepath H2 asynchronous compiler when presented with the following input. In H2, ideally, we should define the handshake for a single interface and then get H2 to join together the input and output interfaces of the stage, but instead we here interconnect the two interfaces manually with one behavioural thread:
interface FIFO
{
forward:
node in [7:0]: data;
node in: req;
node out: ack;
}
section FIFOSTAGE
{
node forward interface FIFO: left;
node reverse interface FIFO: right;
protocol FIFOSTAGE;
}
protocol FIFOSTAGE
{
statemachine()
{
// Receiver 4-phase code inlined.
wait(left.req); D = left.data; left.ack = 1; wait(!left.req); left.ack = 0;
// Sender 4-phase code inlined.
wait(!right.ack); right.data = D; right.req = 1; wait(right.ack); right.ack = 0;
}
}
The generated output will be placed on this link and a simulation trace placed HERE.
Synchronous Compiler
The same source code can be fed to a "behavioural software to synchronous logic compiler". A simple version of such a tool replaces each wait() call with a one-clock-cycle delay. The `while' statements enclosing each wait statement then take on a specific role: the microsequencer sits at that wait statement until the required exit condition holds.
The generated output and trace to be placed HERE.
Clearly, such a compiler will consume far more clock cycles than the hand-optimised synchronous implementation given in the next section. However, it is interesting to test whether the two implementations bisimulate each other when the clock input changes are considered to be tau (delta) transitions. TODO.
3. Synchronous Variation
Basic Synchronous Alternate Protocol
The most convenient way to implement the handshaked in synchronous logic is to use a slightly different protocol that uses a rdy signal instead of an ack signal. Data is transferred on every clock edge where req and rdy are both asserted. Therefore, multiple words are transferred, back-to-back, without executing the protocol. A Verilog RTL implementation of a FIFO stage that implements this protocol would be as follows:
module sfifo(clk, req_l, data_l, rdy_l, req_r, data_r, rdy_r);
input clk;
input req_l, req_r;
output rdy_l, rdy_r;
input [N:0] data_l;
output [N:0] data_r;
reg logged; reg[N:0] holding;
assign req_r = logged, data_r = holding;
always @(posedge clk) begin
if (req_l & rdy_l) holding <= data_l;
logged <= req_l | (logged & !rdy_r);
end
assign rdy_l = !logged | rdy_r;
endmodule
Postprocessing to reduce clock cycle consumption
The synchronous variation has synchronous Moore outputs to the next (right) FIFO stage but the rdy signal to the previous (left) FIFO stage is a Mealy function of the right rdy signal. A cascade of stages leads to combinatorial delay growth in the rdy signal path. This build up cannot be avoided if one desires the property that the input to the FIFO goes ready as soon as any stage further down or the output itself goes ready. If Moore outputs were used for the backpressure path (the rdy signals), then extensive numbers of FIFO empty stage `bubbles' would exist, because the input side would not be able to insert data as soon as possible. This leads to wasted clock cycles in the system and hence reduced throughput.
Both Mealy and Moore ready outputs cause speed problems if used exclusively, it turns out that the best approach is to mix them, using mostly Mealys. Rather than generating a mix to start with, one can generate a system as shown above, using only Mealys, and then apply post-processing to improve performance.
The first style of post processing is to exactly mirror carry lookahead. In carry lookahead, as used in fast adder circuits, the chain of the ripple carry path is replaced with a log-n depth tree structure where the base of the log is essentially the fanin of the widest AND and OR gates in the logic family. For our handshake circuits, the lookahead is applied to the ready signals and quickly computes the OR of all ready signals further down the chain.
The second style of post processing is to add pipeline stages at regularly spaced places. These stages convert the end of the Mealy chain (or lookahead unit output) to a Moore signal that is re-timed with the clock.
4. Unification of the Variations
The interesting thing now is to compare all these design styles and find a formalism under which they may be shown to be equivalent.
We wish to study how a clock structure can be added and removed as we move from behavioural to synchronous implementations. Although asynchronous hardware remains somewhat of a specialist area, migration from untimed-behavioural specifications to synchronous RTL is the main focus of the so-called ESL modelling style being advocated in the EDA industry. Study of the asynchronous styles within our formalisms will lead to useful insight.
Definition: let us call the following circuit a 'synchronous RS latch with setting priority'
always @(posedge clk) logged <= s | (logged & !r);
The essence of our unification of the various styles is that the four-phase micropipeline can be reduced to the simplified RS latch form given certain assumptions about relative timing of the inputs to a stage. The RS latch may then be observed to have a very similar form to the synchronous RS latch used in the synchronous pipeline stage.
Sadly, the best bits of this note are yet to be written...
(C) 2004 DJG. UP.