FPGA computing has commonly been poorly served in terms of file and network I/O. Potential pitfalls are:
So when big data is stored on the file server, it makes sense to stream it as quickly as possible, without interruptions, to the FPGA server blades. This may mean taking a programming approach for the FPGA application that makes data streaming the central focus and organising all other aspects of computation around such a stream. The computed result can sometimes be streamed back to the fileserver at high rate, but commonly (eg. with feature recognition) it is much smaller or even a scalar quantity, and so not really a problem.
In "Live Video Stream Processing on a Maxeler Reconfigurable Computer" Argyrios (Alexandros Gardelakos) writes Examples of dataflow languages include the Value Algorithmic Language (VAL) proposed by the MIT [17], the Irvine Dataflow language (Id) proposed by the University of California [18], the Stream and Iteration in a Single-Assignment Language (SISAL) proposed by the Lawrence Livermore National Laboratories [19], and the MaxCompiler created and developed by Maxeler Technologies [20].
As he says, this design style has something in comon with that of Maxeler, so in this article we use one of the Maxeler Open Stream Processing (OSP) small examples.
But we also should not forget memory bandwidth. FPGAs have a hugh (What a vauge term! please quantify!) amount of on-chip memory bandwidth for BRAMs. FPGAs also have had fairly poor DRAM bandwidth in the past. But recent FPGAs have now sometimes overtaken Intel-style CMPs in terms of memory bandwidth. For instance, the Altera stratix V FPGA has 48 GByte/second peak DRAM bandwidth when its six 8 GB/s banks are all in concurrent use. So does how well an application stage its data makes a big difference to how well it works on a given platform? And can an HPC compiler restage the data successfully?
There is no doubt that FPGAs are the go-to execution platform of choice for network packet inspection...
The original application is here github.com/maxeler/maxpower.
It computes the running average along a stream.
I have not used Maxeler's tools, so I apologise if I have misunderstood something in what I say in this section.
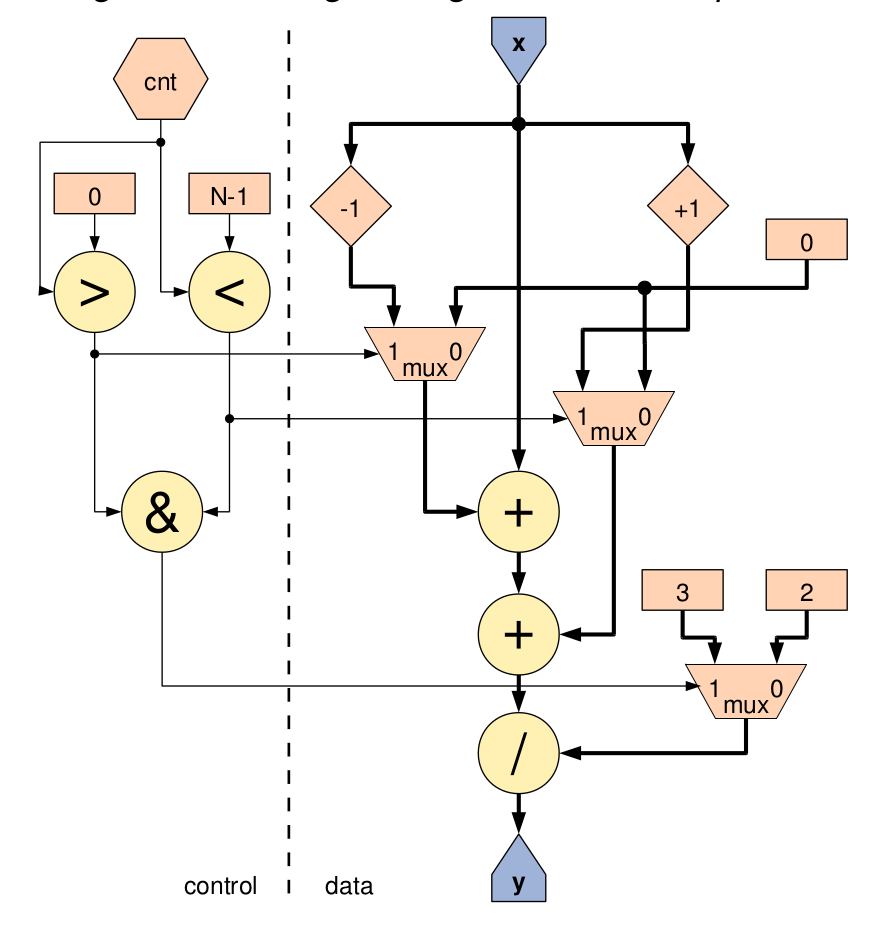
The Maxeler code is not like normal imperative languages as handled by Kiwi and other HLS tools such as LegUp. Instead there is no concept of a program counter and the whole program is executed for every word of the input stream. Conditional execution is not via branches or 'if' statements: predicated execution using the query-colon statement must be used.
HWType flt = hwFloat(8,24); HWVar x = io.input(”x”, flt ) ; HWVar x_prev = stream.offset(x, − 1); HWVar x_next = stream.offset(x, +1); HWVar cnt = control.count.simpleCounter(32, N); HWVar sel_nl = cnt > 0; HWVar sel_nh = cnt < (N − 1); HWVar sel_m = sel_nl & sel_nh; HWVar prev = sel_nl ? x_prev : 0; HWVar next = sel_nh ? x_next : 0; HWVar divisor = sel_m ? 3.0 : 2.0; HWVar y = (prev+x+next)/divisor; io.output(”y” , y, flt ) ;
Here is the small example compiled for Kiwi. We wrote a simple KiwiStreaming library to support applications coded in this nature. The fragment shows an application that will run equally well on mono or on FPGA via KiwiC.
// Streaming Kernels Demo
// Kiwi Scientific Acceleration
//
// (C) 2010-15 - DJ Greaves - University of Cambridge Computer Laboratory
//
using System;
using KiwiSystem;
using KiwiStreaming;
class streaming_avs1
{
[Kiwi.OutputWordPort(31, 0)][Kiwi.OutputName("average")] static uint average = 0;
[Kiwi.OutputWordPort(31, 0)][Kiwi.OutputName("dmon")] static int dmon = 0;
[Kiwi.OutputBitPort("finished")] static bool finished = false;
static void mainloop()
{
long counter = 0;
int last = 0;
while (true)
{
counter = counter + 1;
Kiwi.Pause();
int nd = KiwiBinaryStreamSrc.get_int32();
average = (uint) ((nd+last)/2);
last = nd;
dmon = nd;
Console.WriteLine("Average at point {0} {1} is {2}", Kiwi.tnow, counter, average);
}
}
[Kiwi.HardwareEntryPoint()]
public static void Main()
{
bool kpp = true;
Kiwi.KppMark("START", "INITIALISE"); // Waypoint
Console.WriteLine("Stream ");
KiwiBinaryStreamSrc.start();
mainloop();
System.Diagnostics.Debug.Assert(false, "Never Reached");
Kiwi.Pause();
finished = true;
Kiwi.Pause();
Kiwi.KppMark("FINISH"); // Waypoint
Kiwi.Pause();
}
}
// eof
iverilog -I/home/djg11/d320/hprls/kiwipro/kiwic/distro/support/performance_predictor streaming_av1_fpga.v vsys.v streamwrapper.v /home/djg11/d320/hprls/hpr/cvgates.v ulimit -t200000; ./a.out VCD info: dumpfile vcd.vcd opened for output. Stream Kiwi streaming input start Average at point 900 1 is 1500 Average at point 1100 2 is 2500 Average at point 1300 3 is 1512 Average at point 1500 4 is 2532 Average at point 1900 5 is 2559 Average at point 1900 5 is 2512 ...
The idea of compiling a program to make the maximum use of the network interface is clearly a good idea. The same goes for streaming data from DRAM in a row-sequential or other prefetch-friendly order. But being able to express a design with full-blooded HLL constructs such as method calls is also a good idea. In the future, we might try to design a compilation mode for KiwiC so that it transforms a general C# program (with unrestricted control flow) into a program that is fully pipelined and aims to process work from its primary input streams as rapidly as possible.
In the meantime, Kiwi is implementing a new Pipelined Accelerator compilation mode. This generates a fully-pipelined, fixed-latency stream processor that tends not to have a controlling sequencer, but which instead relies on predicated execution and a little backwards and forwards forwarding along its pipeline. In this mode, one loop body from the application named and converted to hardware. The resulting logic must be manually instantiated inside a framework that sources and sinks the streaming data.
Streaming hardware designs with low initiation interval are suprisingly complex when the ALUs available are heavily pipelined. Floating point ALUS tend to have multi-cycle delay (latency of four to six cycles is commmon for add and multiply in FPGA).
A design with initiation interval of one is said to be fully-pipelined whereas a higher initiation interval can generally be supported with less silicon area using modulo schedulling.
The figure shows three fully-pipelined implementations of the common running sum algorithm. The requirement is for an output that is simply the sum of all X values that have arrived. A fully-pipelined circuit, by definition, has initiation interval of unity. But meeting II=1 adds complexity according to the adder components available.
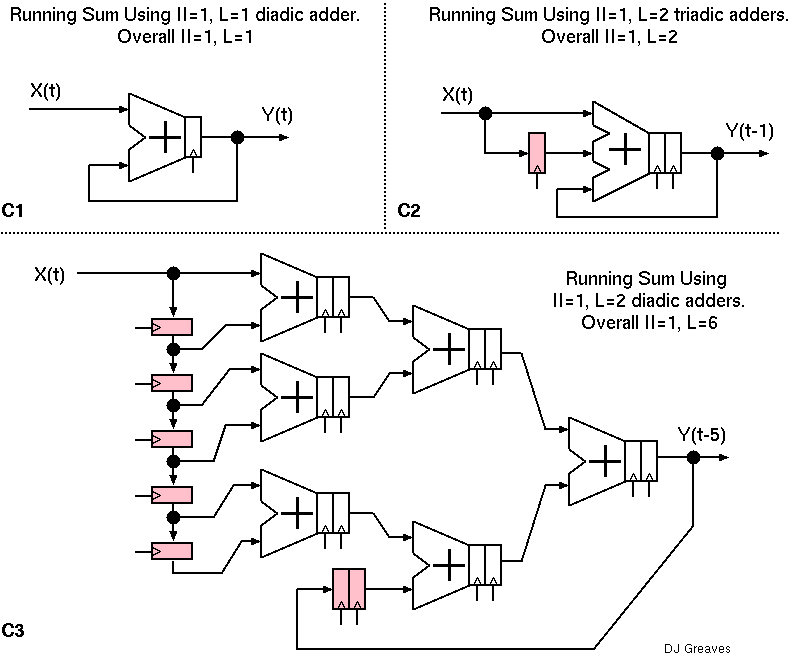
Explanation of designs C1, C2 and C3:
Moreover, when addition is not associative, as is the case for IEEE floating point, the different designs will give result in subtle variations in rounding owing to underflow effects.
The design C3 was created from C2 by a naive syntax-directed algorithm. The triadic adder was replaced with a two-stage adder that summed four inputs with four cycles latency. But this then needed that four input values were summed along with the feedback term and so that design point was impossible. Hence the adder was further replaced with a three-stage circuit that summed eight inputs in six cycles. This needed only to sum six input values and one feedback value, so the input adder that summed with zero was peephole optimised to a two-stage delay. C3 is not an efficient design.
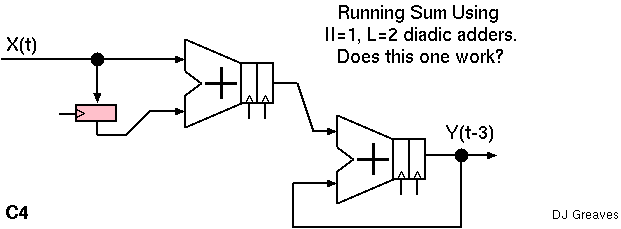
What about the C4 design. What does it do ?
 Overall, finding good designs, whether the II is unity or greater, is an immense search problem.
Overall, finding good designs, whether the II is unity or greater, is an immense search problem.
Watch this space for a whitepaper on HLL constructs that make this paradigm easy to use ...