
Here are my project suggestions for Part II students in the academic year 2011/2012. Some of the information on past years' suggestions may also be relevant. I have supervised about 30 Part II and Diploma projects in previous years, most of which received 1st class marks, with several being singled out for special commendation by the examiners. I also co-authored five academic papers together with former project students of mine. In short, my project suggestions are likely to be challenging but I am fully committed to putting in a lot of effort to provide the best support I can to make sure the project is completed successfully. Who knows, you might end up having a lot of fun too!
The platforms of choice for implementation of most projects are Matlab and OpenCV, although Java might also be an option (especially for UI components). No previous experience of image and video processing is required, just enthusiasm. The projects are challenging in that they address interesting research problems, but plenty of support will be available. Apart from an interest in the project, a reasonable grounding in continuous mathematics and probability theory would be helpful, as would proficiency with high level programming languages such as Java, C++, or the Matlab environment. See also the prerequisites for my Part II Computer Vision course.
Some of the following descriptions are still a bit brief and open to interpretation, watch this space or (better) contact me to find out more. I may add or change project suggestions as the various deadlines approach.
Optical Music Recognition (OMR) seeks to automatically analyse and recognise the information contained within an image of a music score. The aim of this project is to design and implement an OMR system which, given an image of a printed music score, will automatically create a machine-based representation thereof in the open source music score format. This ill require steps such as image preprocessing, music symbol recognition, musical notation reconstruction, and final score rendering into a format such as MusicXML.
Optical character recognition (OCR) of printed documents now achieves very high levels of accuracy, but many challenging application areas remain, such as ANPR (automated number plate recognition) and the recognition of hand-written forms and documents.
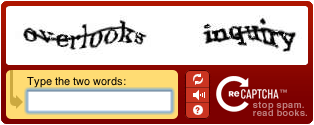
The difficulties of segmenting joint-up letters and of handling slant, noise, and other sources of distortion are exploited by CAPTCHA systems (see http://en.wikipedia.org/wiki/CAPTCHA, http://www.captcha.net/). This project will investigate some techniques for handling common types of CAPTCHA using a range of image processing and computer vision techniques.
Related work:
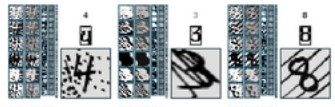
Most of the considerable body of work on OCR has been devoted to the Latin alphabet. There is evidence that "non-Western" writing systems, even those with similarly sized alphabets such as Arabic, differ both in their information theoretical complexity and in the types of features and cognitive processing required for recognition. This project will restrict itself to single character recognition of printed (i.e. not handwritten or calligraphic) letters in one or two non-Latin alphabets and contrast the performance and characteristics of the recognition engines with that for standard 26 character Latin alphabet.
The recognition framework of choice for OCR, and hence for this project, is a convolutional neural network (CNN) (see in particular this paper and this one). Implementations of CNN exist for various platforms, including open source multi-platform APIs such as eblearn. Relevant OCR training data is either freely available or can be machine generated to investigate robustness to viewing conditions, distortions, and noise.
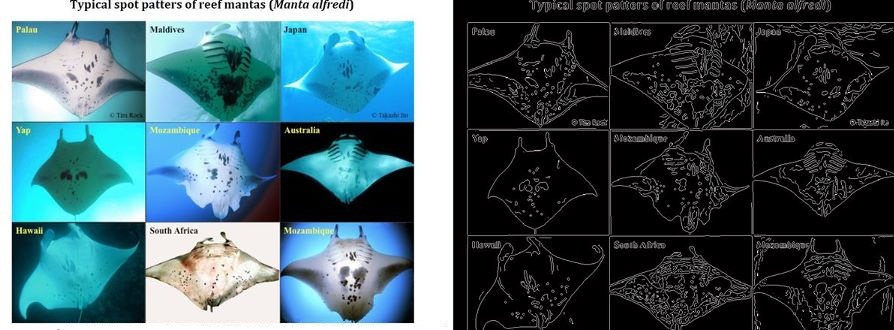
While technologies such as tagging are being used to track and thereby learn more about the behaviour of migratory megafauna, most field work continues to rely on visual identification to catalog and recognise particular specimens. The problems of visual identification are exacerbated in the case of large pelagic marine animals such as whales, manta rays, and sharks, many of whom exhibit characteristic markings that in principle allow individuals to be identified. To this day very little is understood about the roaming behaviour of many of the most magnificent animals in our oceans, and marine scientists and conservationists are having to deal with the task of matching observations against databases of hundreds or thousands of photographs, often taken thousands of miles apart and under very different conditions (lighting, visibility, viewing angle, distance from the subject, occlusions etc.).
This project will build on existing research into using computer vision techniques to extract, analyse, and match characteristic visual patterns in large marine animals. One starting point would be open source systems such as I3S, and published methods such as
Depending on interest, there is scope for perhaps two partII projects within this remit. While the main goal will be to produce a good dissertation, it would of course be desirable to take account of the needs of marine scientists working on projects such as manta ray ecology (see also this page) and the Foundation for the Protection of Marine Megafauna in order to make a contribution towards tools such as the ECOCEAN Whale Shark Photo-identification Library.