Sequential Consistency
- Assume we have cache consistency, but is this enough ?
- Sequential consistency -
- All operations happen in the order specified by the code
- All CPUs' views of these operations are consistent with a global ordering of the combined operations
- Expensive to maintain on modern CPUs
- Tantamount to an implicit memory barrier (fence) instruction
between each memory operation (load or store).
- Actually, need to wait for all possible invalidations or exceptions from a previous
instruction to have settled before starting the next.
Single CPU Guarantees
1. A given CPU always perceives its own memory operations as
occurring in program order. That is, memory-reordering issues arise
only when a CPU is observing other CPUs' memory operations.
2. An operation is reordered with a store only if the operation
accesses a different location from the store.
3. Aligned simple loads and stores are atomic.
Self-Modifying Code
Not supported since I/D cache separation.
Needed for JIT and OS loader.
Flush whole I cache gets expensive if frequent.
Used deliberate alias techniques for very small, known caches
Better to use an OS primitive that maps to partial flush/invalidate instructions.
Possible Consistency Models
Three (at least) main models should be considered:
1. Sequential Consistency
2. Processor consistency (W to R ordering): Writes
from a given processor are always seen by others as in that processor's order
but stores by different processors may not be seen in true order.
2. Weak Consistency:
- All operations on synchronisation variables are sequentially consistent,
- No synchronisation variables may be accessed until data operations are complete,
- No data variables may be accessed until synchronisation operations are complete.
A write is 'complete' when no subsequent read can find a different value.
(A read is 'complete' when no subsequent write can change the value read.)
Do we need cache consistency between barriers ?
OO Race Problems
Java has synchronised keyword
C C++ has volatile keyword

Processor 1 executes its code first. Its cache happens to flush the
modification of Foo.bar back to main memory, but none of the other writes.
Then, processor 2 executes its code, it loads its cache only
with the new value of Foo.bar from main memory (finding old values in
the cache for all other memory locations).
Will processor 2 see garbage for integer x ? What if it were an object handle ?
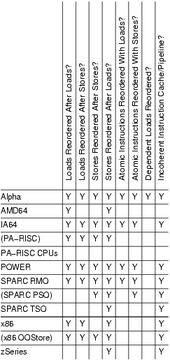
Memory Barrier Instructions
CPUs differ greatly in the reordering they introduce and in the
memory barrier (fence) instructions they offer.
Linux library offers a clean, portable interface.
Linux-kernel synchronization primitives contain any needed memory barriers, which is a good reason to use these primitives.
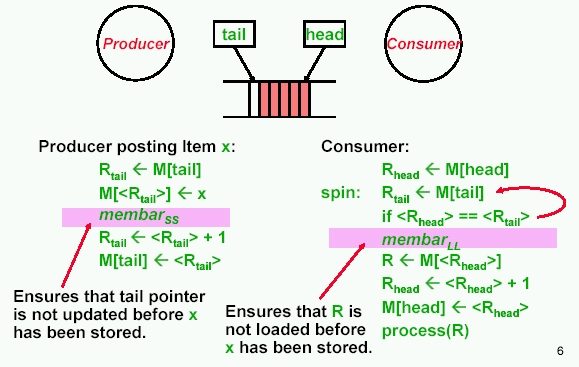
Using a Barrier (slide from MIT)
Linux SMP Primitives
Loads and/or stores preceding the memory barrier are committed to
memory before any loads/stores following the memory barrier.
smp_mb(): "memory barrier" that orders both loads and stores.
smp_rmb(): "read memory barrier" that orders only loads.
smp_wmb(): "write memory barrier" that orders only stores.
smp_read_barrier_depends(): forces subsequent operations that depend on prior operations to be ordered. This primitive is a no-op on all platforms except Alpha.
Linux Journal Articles:
1
2.
Power PC : eieio instruction
(Enforce In-Order Execution of I/O)
Atomic Instructions
Uniproc: Test and Set Instruction.
Uniproc: Compare and Swap Instruction.
Uniproc: Load and increment Instruction.
SMP: These need to bypass cache completely and become atomic DRAM operation.
SMP: Two stage solutions using load linked and store conditional.
Try to use 'lock-free' data structures and don't spin.
|