Figure 1a / 5
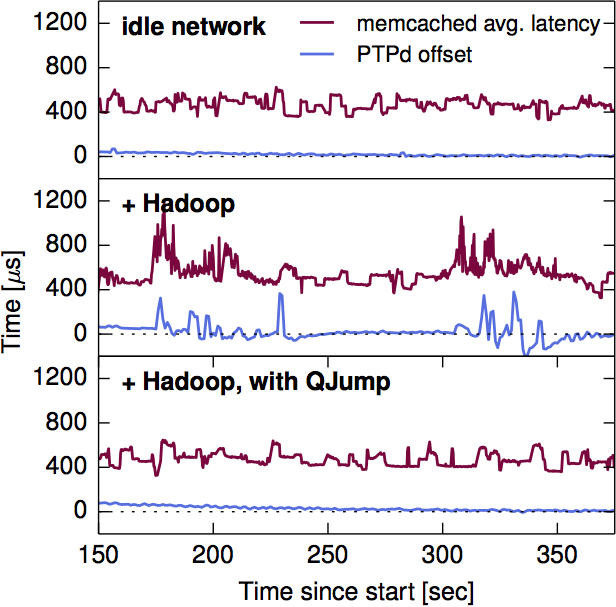
Figure 1a (page 2) is used as a motivational experiment to show that Hadoop MapReduce is capable of interfering with the behavour of precision time protocol. This figure is repeated in Figure 5 (page 8) in a slightly different form, combined with results from memcached combined. In this case, the figure shows that QJump is capable of resolving interference in PTPd as well as memchaced.
Figure 1a
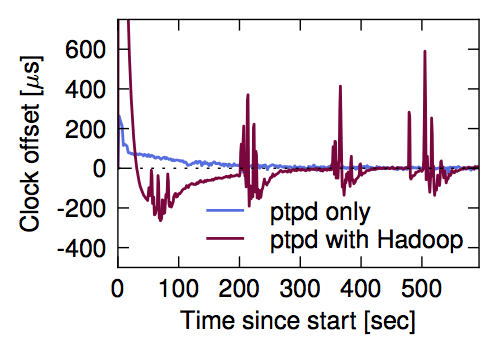
Figure 5
Software Required
In addition to these general software requirements, we also used:
- QJump kernel module
- QJump application utility
- Hadoop Map-Reduce 4.5.0 (installed from Cloudera packages, instructions here)
- Memcached 1.4.14 (installed from Ubuntu packages)
- memaslap from libmemcached 1.0.15 (patched as below)
- PTPd 2.1.0 as installed from the Ubuntu repository
Physical Configuration
The basic physical network configuration is described here. In this experiment the following configuration was used:
- When running, H3 ran the (patched) memaslap client and H11 ran the memcached server
- When running, H1 ran the PTPd client and H8 ran the PTPd master
- When running, The Hadoop Map-Reduce cluster ran on H2, H4-H7, H9,H10 and H12
Patches
To obtain more detailed results from memaslap, we patched it to collect statistics in memory and dump them to standard output when complete. The patch file should be applied to the clients sub-directory of the libmemcached 1.0.15 source tree listed above. To build memaslap, run "./configure --enable-memaslap" followed by "make && sudo make install".
Sofware Configuration
The full Hadoop Map-Reduce configuration can be found here. The PTPd client and server were configured as follows:
Server
e=1; p=0; ./qjau.py -p $${p} -c "ptpd -c -b eth6.2 -y 0 -D -h -T 10"
Client
e=0; p=7; ./qjau.py -p $${p} -c "ptpd -x -c -g -D -b eth0 -h -T 10 -f ../data/ptpdCFRS201_memcachedBS206_hadoop_R2D2P$${p}_PTPD_$${e}
Where "$$e" is th experiment number and "$$p" is the QJump prioirty level.
Memcached and memaslap were configued as follows:
Server
e=1; p=0; sudo ./qjau.py -p $${p} -c "/usr/bin/memcached -m 64 -p 11211 -u memcache"
Client
e=1; p=0; for {1..25}; do
./qjau.py -p $${p} -c "../clients/memaslap -s 10.10.0.3:11211 -S 1s -B -T2 -c 128 -X 1024" > ../data/ptpdCFRS201_memcachedBS206_hadoop_R2D2P$${p}_$$(printf "%02i" $${i})_MEMD_$${e};
done
Where "$$e" is th experiment number and "$$p" is the QJump prioirty level.
When QJump was enabled, it was configured as follows
bytesq=256 timeq=5 p0rate=1 p4rate=100 p7rate=9999999
Raw Data
PTPd Data
Our original unprocessed datasets can be found here (109kB). Inside the archive are file names of form:
- ptpdCFRS201_R2D2P0_PTPD_[0-1] - PTPD running alone of the network with the client on FS (Freestyle) and the server on 201 (Quorum 201). 3 trials were run, with a runtime of 10 minutes each. Data from tail 3 is missing.
- ptpdCFRS201_memcachedBS206_hadoop_R2D2P0_PTPD_[0-3] - PTPd running on the network, shared with memcached and Hadoop. 4 trials were run, with a runtime of 10 minutes each.
- ptpdCFRS201_memcachedBS206_hadoop_R2D2P7_PTPD_[4-6] - PTPd running on the network, shared with memcached and Hadoop. PTPd is configured for QJump level 7. 3 trials were run, with a runtime of 10 minutes each.
2014-01-22 19:51:27:363605, slv, 90e2bafffe27fbc8/01, 0.000140635, -0.000019134, 0.000197000, 0.000108000, 21106
Where the first column is the timestamp, and the fifth coloum is the syncornization offset.
Memcached Data
Our original unprocessed datasets can be found here. There are 10 archives of approx 310MB each. The file names are of the form:
- memcachedBS206_R2D2P0_MEMD_[0-2] - Memcached running alone of the network with the client on BS (Backstroke) and the server on 206 (Quorum 206). 3 trials were run, with a runtime of 10 minutes each.
- ptpdCFRS201_memcachedBS206_hadoop_R2D2P0_PTPD[0-3] - Memcached running on the network, shared with PTPd and Hadoop. 4 trials were run, with a runtime of 10 minutes each.
- memcachedBS206_hadoop_R2D2P5_MEMD_4[4-6] - Memcached running on the network, shared with PTPd and Hadoop. Memcached is configured for QJump level 5. 3 trials were run, with a runtime of 10 minutes each.
{GET | SET | TOTAL} , REQUEST ID, LATENCY
Processing and plotting the results
The processing and plotting scripts can be found here. To produce Figure 1, we ran the following:
python plot_ptp_offset_timeline.py \
../data/ptpd/ptpdCFRS201_R2D2P0_PTPD_0 \
../data/ptpd/ptpdCFRS201_memcachedBS206_hadoop_R2D2P0_PTPD_3 \
figure1a.pdf
Before plotting Figure 5, the memcached data needs to be processed into a more compact form. To do so, we ran the following:
python process_mem.py ../data/memcachedBS206_R2D2P0_MEMD_1/
Then, to produce Figure 5, run something like the following:
python plot_ptp_memcached_hadoop_timeline.py \
../data/ptpd/ptpdCFRS201_R2D2P0_PTPD_0 \
../data/memd/ptpdCFRS201_R2D2P0_PTPD_0/memcachedBS206_R2D2P0_MEMD_1.set.processed \
../data/ptpd/ptpdCFRS201_memcachedBS206_hadoop_R2D2P0_PTPD_3 \
../data/memd/ptpd_memcached_haroop_data/ptpdCFRS201_memcachedBS206_hadoop_R2D2P0_MEMD_1.set.processed \
../data/ptpd/ptpdCFRS201_memcachedBS206_hadoop_R2D2P7_PTPD_1 \
../data/memd/ptpd_memcached_haroop_data/ptpdCFRS201_memcachedBS206_hadoop_R2D2P5_MEMD_4.set.processed \
figure5.pdf