Existing hardware implementations of ATM interfaces are now presented in Sections 6.1, 6.2 while enhancements are presented 6.3.
ATM interfaces for Unix workstations have been reported by Davie [3] and Traw [18]. These are both high functionality interfaces. Traw's controller adapts ATM cells on a 155 Mbit/s SONET STS-3 carrier to an IBM RS 6000 Microchannel and performs sorting of received cells in microcoded hardware. However it does not implement reassembly check functions. Davie's controller is for the DEC Turbochannel and is equipped with two Intel 960 processors to offer a variety of processing options. The controller will connect to four STS-3 carriers or one STS-12 carrier.
Simpler controllers have been built by Olivetti Research and Fore Systems for Turbochannel and S-bus respectively. These do not perform protocol processing, except for the ATM header check (HEC-8), and in the case of the Fore Systems units, the payload AAL-4 CRC-10. Neither interface maintains state information at a granularity larger than a cell.
Design and performance of the ORL interface is now presented.
The ORL controller, known locally as the `Yes V2' interface, employs a physical layer using the AMD TAXI transmission devices at 100 Mbit/s. The physical layer cell format accords with a de facto standard drawn up by Sun and Xerox and now adopted by the ATM Forum [1]. Hence taking the header and inter-cell symbols into account this affords 94.5 Mbit/s of payload throughput.
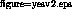
Figure 2: Block diagram of the `Yes V2' option module
The controller has separate receive and transmit FIFOs, each able to hold 76 cells. A further `token' FIFO is used merely as an up-down counter to keep track of the number of cells completely received. Host data transfer is either through programmed IO or by DMA. DMA transfers of up to 39 cells are supported by the current Turbochannel host system, the DECStation 5000. DMA transfers may either be used to copy a block of memory which has already been formatted by the processor with the appropriate ATM cell header inserted every 13 words, or in conjunction with programmed IO, where the processor reads or writes the ATM header word directly to/from the FIFO and then initiates a DMA transfer of the cell payload.
A receive interrupt can be generated on each cell received, or alternatively, on the arrival of cells with the header indication flag set. Using this latter mode, a PDU may accumulate in the receive-side FIFO until its last cell has been received, and then the host interrupted. Of course, the host may find other cells in the FIFO from incompletely received PDUs on other associations, in which case it must sort and store these as usual. However, these cases will be rare for many data applications [17] and, in all cases, the overall frequency of interrupts may be reduced. On the transmitter side, interrupts are available on TX FIFO less than half full and on end of DMA.
Transmit side interrupts are not yet required in the Unix device driver, since, as is explained shortly, we have found that sustainable transmit rates are less than the 100 Mbit/s available and so the transmit side does not go busy.
Experiments where performed using MSNA under both Ultrix and our local
experimental kernel Wanda, on DECStation models 5000/200 and 5000/25
respectively![]() . The experimental system consisted of a single workstation
with the MSNL protocol in its kernel provided to user processes as an
MSNL socket and a Turbochannel controller, with the output from
the TAXI transmitter looped back to the TAXI receiver using a short
length of cable.
. The experimental system consisted of a single workstation
with the MSNL protocol in its kernel provided to user processes as an
MSNL socket and a Turbochannel controller, with the output from
the TAXI transmitter looped back to the TAXI receiver using a short
length of cable.
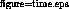
Figure 3: Stages of the loop-back test
Two processes were involved, a sender and receiver process. The sender process sends a PDU of 70 cells through its MSNL socket and out through the controller. Since the controller cable is looped back, the receiving side of the interface directly receives the PDU. The receiver passes the cells up through another MSNL socket to the receiver process. The receiver process then sends a single cell ACK message in the reverse direction. The process then repeats; this repetition gives a stable display of various signals on an oscilloscope for taking measurements in a non-intrusive manner. All values for throughput represent ATM cell payload throughput.
Figure 3 represents one cycle of this repeating process and labels the various time intervals of interest in the test:
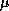 s.
s.
The measured values of interest are presented in Table 1. Other experiments have shown that it is reasonable to allocate the operating system and user overhead component equally amongst the transmit and receive paths. Hence we can deduce that sustained transmission rates of 28 Mbit/s and 46 Mbit/s, and reception rates of 16 Mbit/s and 19 Mbit/s can be achieved with Ultrix and Wanda respectively. The througput rates shown over the whole period, of 9 and 13 Mbit/s, show the performance possible to a simple RPC type of communication.

Table 1: Interval durations and equivalent throughput for programmed IO
Two observations can be made from the results. The first is the difference between the transmission and reception rates; this is explained by the cost of per cell checks on reception, including VCI checks and, with the SAR protocol being used, sequencing checks. The second is the difference between the Ultrix and Wanda performance; this is mainly due to the lack of a data copy in the case of Wanda where all data is moved between kernel and user via a pool of interprocess communication buffers, with the optimization of not changing their virtual address on transfer of ownership having been taken to avoid performance penalties due to cache flushing.
Considering the hardware simplicity of an interface which is only required to support programmed IO, the performance is still respectable. The `Yes V2' also has support for DMA and we have been able to achieve some preliminary results using DMA, presented in Table 2. However, while comparing programmed IO on Ultrix and Wanda was straightforward, in supporting DMA, significant differences are experienced in the implementation route taken for the two operating systems. Of major importance is that with the machines used, while the processor has a write through cache, it does not snoop on the memory bus and hence explicit action must be taken to avoid inconsistencies between the cache and the memory system due to DMA actions. Hence while tranmission DMA is straightforward, DMA on receive is more complex.
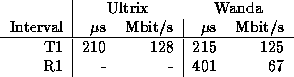
Table 2: Interval durations and equivalent throughput for DMA
With Ultrix, advantage can be taken of the need to copy from user to kernel mode; during the copy, a valid header is inserted in front of every 48 octets of user data copied, so that on transmission, multiple cells are moved in a single DMA transfer. Using this mechanism the sustainable transmit throughput can be increased to 61 Mbit/s, with the DMA transfer itself happening at 128 Mbit/s. This ``multiple cells at a time'' mechanism is not suitable for use on reception (without resorting to another copy) as each cell header must be interrogated to obtain the VCI. In fact within Ultrix, we have so far been unable to deal with the cache/memory consistency problem so that results for receive DMA are not available.
With Wanda, we were able to implement DMA on both receive and transmit. As there is no user/kernel copy operation within Wanda, we chose to implement a DMA transfer per cell.. Even so, the overall transfer rate from memory to transmission FIFO is still a respectable 125 Mbit/s, and together with Wanda's lower per packet overhead this represents a sustainable transmission rate of 99 Mbit/s (hence greater than the supported 94.5 Mbit/s). The manner in which the interprocess communications buffers are used within Wanda also allow us to overcome the cache/memory consistency problem for reception so that the FIFO to memory transfer achieved is 67 Mbit/s resulting in a sustainable throughput of 57 Mbit/s.
We have shown that an interface which merely reduces the host interaction rate to below once per cell is only sufficient for half-duplex operation of a 100 Mbit/s ATM interface, when using the full processing power of current RISC workstations. Using DMA for each cell increases the performance of the interface over programmed IO, but fails to release the processor to enable it to handle other activities. This is contrary to the typical case when using DMA with lower speed and non-ATM interfaces.
The approach of advance formatting a user message into cells enables longer DMA transfers to take place. Per-cell processing is still required to generate the cell structure, but this processing is decoupled in time from actual cell transmission. In addition, consecutive cells need not be for the same virtual circuit, hence enabling more flexible rate control and smoothing out bulk arrivals, which can be of benefit to downstream switches.
An alternative transmit structure of not much greater complexity puts the complete fragmentation sub-system in the interface. The host writes a prototype 32 bit cell header to a header register in the interface. This header, along with its HEC, are automatically inserted in the outgoing stream after every 12 words (48 bytes) of data are transferred to the interface. (Data may be moved either by programmed IO or by DMA.) In addition, the interface may insert other convergence sub-layer and AAL fields, including any per-cell (AAL-3/4) or final (AAL-5) CRC and length checks. This interface removes all per-cell processing from the host, but has lost the ability to intermix cells from different virtual channels at a fine granularity in the outgoing stream.
For reception, the presence of interleaved cells from different virtual circuits must be handled, but one can implement a relatively straightforward interface where the hardware has only the capability to handle adjacent cells on the same virtual circuit and software is used otherwise.
When a cell is received which is on a different virtual circuit from the previous cell a `context swap' of the interface is required. The processor reads out the partially-calculated running state, such as total AAL-PDU length and overall CRC or checksum, and any other fixed values, such as block identifiers, VCI, VPI and MIDs, and stores them in an internal association table. The identity of the next virtual circuit is available by reading just the cell header out of the buffer store in the interface. There are then two methods for context restoration aspect. The processor may either re-load the interface with the running values of parameters which contain inter-cell state, or it may reset these registers to a known starting value and afterwards combine the separate results in software.
An interface for a modern RISC processor using this approach should easily be able to transmit at the 100 Mbit/s rate. Reception will only be significantly slower than transmission if cells from separate associations are highly interleaved.
In general, the incorporation of CRC generating and checking hardware is vital for high performance interfaces. Since we intend to use the new adaptation layers which employ CRCs, such hardware must be deployed in all of our future interface designs.
It is not clear that any further worthwhile features can be added to an interface unless it implements the sorting function. A sorting interface may either accumulate cells in its own local memory, or may use direct insertion into the main host memory. An advantage of the former approach is that a CRC may be calculated without interruption when data is copied once from the controller to host memory. Advantages of the latter approach are intrinsically shorter bus holding times and `cut-through' where data is ready in host memory as soon as possible.
Sorting interfaces may only be able to support a subset of the
available VCI space since it is desirable to use directly-mapped
memory to look-up VCIs. In all of our current MSNA data-link services
(our ATM switches and rings), this problem is ameliorated since
receivers are able to allocate their own incoming VCIs. If this is
not possible when directly connected to B-ISDN, then it should at
least be possible when using a local ATM LAN. The ATM LAN may be
connected to B-ISDN at one or more points. The entity at the B-ISDN
to ATM LAN boundary can then use associative techniques if
necessary![]() . An interface which can support 64000
active VCIs is deemed sufficient by [3], and we would agree.
. An interface which can support 64000
active VCIs is deemed sufficient by [3], and we would agree.
Custom and semi-custom VLSI are being used to implement an ATM LAN controller. These devices connect to OEM host bus controllers, such as those available for EISA, Turbochannel, VME etc. and to inexpensive fibre-optic physical layer devices, such as the AMD FOXI parts, or other standard line interface units (e.g. for T3, E3 or SDH). A full ATM interface ASIC performs sorting, adaptation, rate control and probably buffer management of local memory and scatter-DMA in host memory. Example specifications are available as data sheets from the manufacturers PMC Sierra Inc of Burnaby BC and Base 2 Systems of Boulder CO and from Cambridge UK in [5] and [7].