
Collapsed LAN
|
These pages were last modified 2/7/05.
|
Introduction
The CLAN project has designed and implemented a server room architecture, which will enable the next generation of ASP, web fronted database, and videocast applications to operate in a multi-gigabit, very- high transaction rate environment. We have implemented a fully functional prototype gigabit user-level network, which reduces network software overhead, enabling higher throughputs and transaction rates at the server. Evaluation of our prototype has shown up to an order of magnitude improvement in transaction rates over Gigabit Ethernet, even though both run at the same physical line rate. Our network architecture is unique amongst other user-level networks in that we are addressing the issues of simplicity, reliability and scalability. We support both a large number of servers in the cluster and a large number of independent application components on each server, and implementations are able to ride the future network bandwidth curve easily.The CLAN model for communication
Clan has adopted non-coherent distributed shared memory as our mechanism for data transfer, rather than channel based I/O. Once a shared memory aperture has been created between two applications' address spaces, data transfer can be achieved using processor load-store instructions for the lowest possible latency and overhead. DMA and RDMA are of course also possible through these apertures for bulk data transfer while off-loading the CPU.This mechanism also offers the simplest hardware implementation and will keep pace with expected link speed rises. By contrast, channel based mechanisms, such as Inifiniband and VIA, suffer from complex implementation requirements and require significant per endpoint resources, both in the network interface card (NIC) and in the application (e.g large pinned-down buffer space requirements).
The CLAN model for Synchronisation
Our communication model is such that the operating system is by-passed during network transfers through user-level mapped apertures. Under these circumstances, synchronisation between applications becomes an issue. We have developed a novel synchronisation mechanism, Tripwire, which is an application programmable Content Addressable Memory (CAM) on the NIC, performing actions (such as enqueuing a message) in response to data transfer events (such as receipt of data to a particular memory location) on the NIC. In doing so, Tripwire enables the synchronisation of large numbers of user-level network endpoints to be managed efficiently.
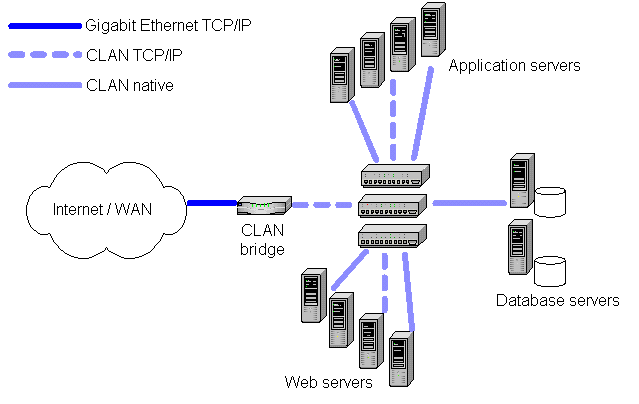
The CLAN interface to Conventional Networks
Clan treats conventional networks as first class peers and seeks to handle conventional traffic with the same performance and scalability advantages as offered within the interconnect. Taking incoming TCP/IP streams as an example, the CLAN bridge device also acts as a packet filter onto user-level packet queues. This enables TCP stacks to be run at user-level on the servers, resulting in significant improvements in the efficiency of protocol processing. This architecture also distributes protocol processing over the cluster, allowing the bridge design to be fast, simple and reliable.
Prototype CLAN Network

The MarkIII PCI-Link NIC |

The MarkI PCI-Link Switch |

The MarkI GigE to CLAN Bridge |
Our current status is that we have a prototype network running at our lab, comprising 2 5-port switches and 12 NICs. These were built using a mix of FPGAs and off-the-shelf parts, but have been operated successfully at 1Gbps, offering application-application latencies of 1.5us and bandwidths of 960Mbps.
Also, we are in the final stages of building a prototype Gigabit-Ethernet to CLAN bridge. This will have the capability of demultiplexing TCP/IP streams onto user-level CLAN connections.
A number of transports over CLAN have been implemented, including: TCP, CORBA, MPI, VIA, and BSD sockets. These use the library level communication abstractions with good results. Additionally, we have experience of application level integration with NFS and a DBMS, together with an appreciation of the issues involved in maximising the system level benefits from our network.
The driver and communications libraries are portable between Linux and Windows2000 and may reside either in-kernel or as user-level objects.
{kind=link}
Performance
Round Trip Performance
On a 533Mhz Alpha Linux platform, a 40 byte application to application round trip (RTT), for a single endpoint on two processors connected via a MarkIII has been measured at 7.9 us, where CPU polling is used for Rx synchronisation. This could be compared against 304us for Gigabit Ethernet (3c985) and 19us for a hardware VIA (cLAN1000).
Streaming Performance

The graph shows the performance of an application to application streaming abstraction: the Queue, and compared with the streaming performance of both Gigabit-Ethernet (using a 3c985 NIC) and a hardware VIA implementation (using a Giganet cLAN1000 NIC).
Using the Queue between two user-level applications and measuring the bandwidth of data both passed over the interconnect and being copied into and out of the Queue, we achieve our maximum transfer rate of 880Mb/s at 32KB transfers, but half our maximum rate is achieved at 128 Byte transfers and our buffer space requirement is only 10KB per endpoint.
By contrast, where sending and receiving applications are decoupled by kernel protocol stacks (as in the case for the Gigabit-Ethernet trace), there are very large buffering requirements in order to achieve high bandwidths. In the Gigabit-Ethernet trace, 9KB jumbo Ethernet frames and 512KB socket buffers were required. This does not scale to large numbers of network endpoints and means that the available bandwidth of the network will simply never be used by most applications.
Similarly, for the user-level networking industry approach VIA, where sending and receiving applications are decoupled by asynchronous hardware request queues, it may not be possible for a NIC to deliver received data, because no buffer descriptors are available for a given application. In such a situation, VIA mandates either tearing down the connection or dropping the packet. This either means that VIA endpoints require very large receive buffer allocations, or else must use a higher level protocol with a window mechanism based on the receiver's buffer availability. In the above trace, a software window update mechanism is used, with 256KB buffers reserved. This feature of VIA reduces its scalability and increases the latency of the interconnect. We have developed an implementation of VIA as a software library over the CLAN network. Our implementation alleviates this problem by providing flow control within the VIA model, plus a number of other enhancements.
Other reports of per-endpoint buffer allocations have been given only in Arsenic which is a VIA implementation on the Alteon Networks ACEnic Gigabit-Ethernet and required 256KB per user-level TCP endpoint under benchmark conditions.
Transaction Rates
We illustrate the potential of the Tripwire mechanism for transaction processing using a demonstration server. This server uses a single-threaded event processing model, the main event loop being based on the standard BSD select system call.
The file descriptor corresponding to a Tripwire event queue is a member of a 'select set', and becomes readable when there are entries in the event queue. In this case a handler extracts events from the queue and dispatches them to call-back functions associated with each endpoint. This event queue is serviced until it is empty, and then polled for up to 15 us before returning to the main select loop.
Hence, when a large (>15 us) gap is left between each request the server goes to sleep between requests, and the round-trip time consists of the transmit overhead, the hardware latency, the interrupt overhead, the rescheduling overhead, the message processing overhead and the reply. The total is 16.8 us.
A server using the Tripwire event queue becomes more efficient when kept busy, since it avoids going to sleep. If messages are sent as quickly as possible, one after another, but with only one message in flight at a time, the round-trip time consists of the same steps as above, but without the reschedule, and improved cache performance. The round-trip time is reduced to just 7.9 us.

The graph illustrates a test where multiple requests are sent by the client on different connections before collecting each of the replies. This simulates the effect of multiple clients in the network. Note that even when the server is overloaded the performance of the network interface is not degraded.
The curve is tending towards 461000 requests per second, and given that the server is effectively performing a no-op, we can assume that all the processor time is spent processing messages. Thus the total per-message overhead on the server when fully loaded is 1/461000, or 2.2 us.
This should be compared with the traces for Ethernet. Using Gigabit-Ethernet/TCP (3c985), the achievable transaction rate is only 21184 requests per second, only a marginal improvement over Fast-Ethernet (100BaseT). It should be noted that a Gigabit-Ethernet/UDP (not shown) would peak at 33000 requests per second, but packet loss at this rate would have made the server unusable.
The hardware VIA (cLAN1000) manages around 150000 requests per second which implies a per transaction cost of 6.6 us. This is surprisingly high, (since completions from each endpoint do not require an interrupt). It appears that the hardware is unable to efficiently amortise batches of completion events.
Group Members

David Clarke |

Kieran Mansley |

Tim Mills |

Steve Pope |

David Riddoch |

Derek Roberts |
Publications
| Distributed Computing with the CLAN Network | Submitted to SIGCOMM 2002. Do not cite. |
| VIA over the CLAN network | AT&T Laboratories Cambridge Technical Report |
| A Low Overhead Application/Device-driver Interface for User-level Networking | 2001 International Conference on Parallel and Distributed Processing Techniques and Applications |
| CLAN Scalable High Performance User Level Networking [ Abstract | Talk] | IEEE Gigabit Networking Workshop GBN 2001 |
| Tripwire: A Synchronisation Primitive for Virtual Memory Mapped Communication |
4th Intl Cnf on Algorithms and Architectures for Parallel Processing
'2000 Journal of Interconnection Networks Vol.2 No.3, September 2001 |
| The Collapsed LAN: a Solution to a Bandwidth Problem? | Computer Architecture News vol 25 No 3 |
Please note that the techniques disclosed here have been the subject of patent applications.
Contact information
Copyright © 2002 AT&T Laboratories Cambridge