Figure 7
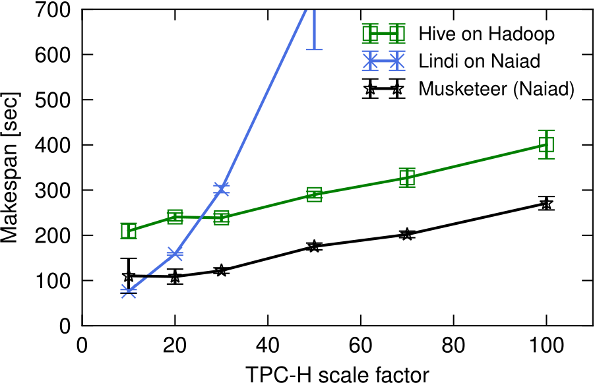
Figure 7 (page 10) compares the performance of TPC-H query 17 implemented using Hive and executed on Hadoop, implemented using Lindi on Naiad and implemented using Hive but executed with Musketeer.
Musketeer has the lowest makespan, although it still uses
Naiad. However, the generated code includes low-level Naiad vertex code
that fixes a limitation in Lindi's GROUP BY operator, thus
running up to 9x faster than the Lindi-on-Naiad implementation.
Figure 7
Under construction: we will add information on the experimental setup and our data sets here shortly.
If you are interested in being notified when the data appears,
please join our
musketeer-announce mailing list.
Thanks for your patience.
-- The Musketeer team.
Experimental setup
This experiment was executed on an Amazon EC2 cluster comprising of 100 instances. Please check the clusters page for more details.
Result data set
The raw results for this experiment are available here.
To plot Figure 7, run the following command:
experiments/plotting_scripts$ python plot_tpch.py ../tpch/tpc-h-q17_new.csv hive "Hive on Hadoop" naiad_100nodes_baseline "Lindi on Naiad" naiad_musketeer_merged_c4 "Musketeer (Naiad)"
The graph will be in tpch_runtime.pdf