Figure 13
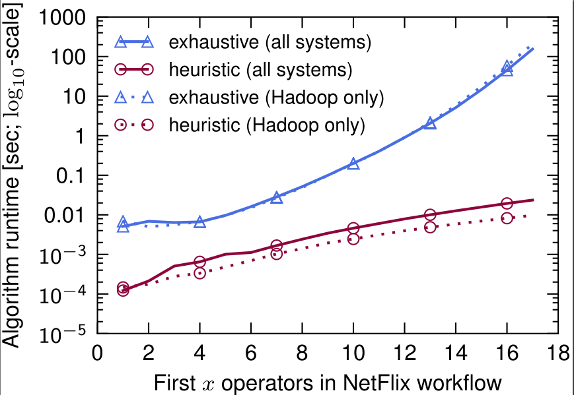
Figure 13 (page 12) compares the runtime of Musketeer's two different DAG partitioning algorithms: the exhaustive search (for small workflows) and the dynamic heuristic (for large ones). Independent of the number of back-end execution engines enabled, the exhaustive search runtime is exponential and only feasible up to 13 operators. The dynamic heuristic, by contrast, runs in milliseconds even for large workflows, but may miss merge opportunities.
Figure 13
Under construction: we will add information on the experimental setup and our data sets here shortly.
If you are interested in being notified when the data appears,
please join our
musketeer-announce mailing list.
Thanks for your patience.
-- The Musketeer team.
Experimental setup
This experiment was executed on the freestyle machine from our small dedicated cluster of seven machines.
The input consists of an extended version of the Netflix workflow. On the x-axis we vary the number of operators we include from the workflow. The exhaustive search algorithm runs in under a second for workflows of up to 13 operators. While it guarantees that the optimal partitioning with regards to the cost function is found, the runtime of exhaustive search quickly becomes impractible (e.g., 154s for the workflow with 17 operators).
Result data set
The raw results for this experiment are available here.
To plot Figure 13, run the following command:
experiments/plotting_scripts$ python plot_scheduler_runtime.py ../scheduler_time/sched_lat_large_net_all.csv " (all systems)" ../scheduler_time/sched_lat_large_net_had.csv " (Hadoop only)"
The graph will be in scheduler_runtimes_log.pdf